
Spanje – Nederland: 1-5!
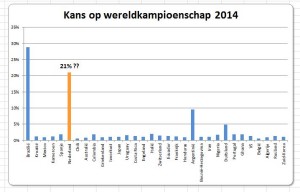 Wie had dat verwacht; niemand toch?
Wie had dat verwacht; niemand toch?
Mijn vrienden, met wie ik de wedstrijd samen bekeek, begonnen te twijfelen aan de WK-voetbal voorspeller van G-Info (zie mijn blog van 5 juni).
Ik kan alleen maar ter verdediging aanvoeren, dat in mijn vorige blog ook al stond aangegeven, dat de kwaliteit van ieder Excel-model afhangt van de input en van de gehanteerde systematiek. De systematiek hou ik nog even staande (hoewel er al mensen tips voor verbetering hebben aangeleverd); de input kan iedere gebruiker zelf aanpassen (ik heb een paar ‘kleine’ aanpassingen gedaan en zie hierboven het resultaat voor de verwachtingen voor Nederland!).
Maar ik had beloofd om deze week wat meer uitleg te geven over de opzet van het spreadsheet-model; dus voor diegene, die daar nu nog behoefte aan heeft ….
Werkblad Invoer
Hier valt weinig spannends te beleven; dit blad bevat 2 tabellen, die als basis dienen voor het vervolg.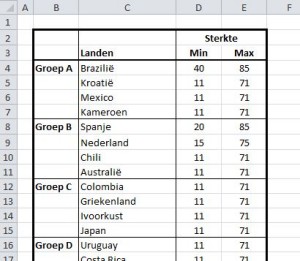
Groepsindeling
Ik neem aan, dat de opbouw van deze tabel logisch genoeg is.
Zoals vorige keer al aangegeven, leggen we de sterkte van een land (qua voetbal!) vast via een ondergrens en een bovengrens.
Hoe kleiner het verschil tussen die twee grenzen, hoe stabieler de resultaten van het land zullen zijn en omgekeerd.
Het voorspeller-bestand is zodanig opgezet, dat deze voor een volgend toernooi opnieuw bruikbaar is. Dit alles onder de condities, dat er weer 8 groepen zijn met ieder 4 landen/ploegen en dat de 2 beste van de groepen verder gaan naar de achtste finales.
In dat geval hoeven alleen de namen van de deelnemende ploegen te worden gewijzigd in het werkblad Invoer. En uiteraard de grenzen voor de ploegen!
Groepschema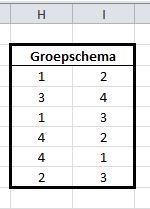
Met behulp van dit schema is vastgelegd in welke volgorde de groepswedstrijden worden gespeeld.
In dit geval speelt eerst ploeg 1 uit de groep tegen ploeg 2, dan 3 tegen 4, 1 tegen 3 etcetera.
Binnen dit werkblad zijn 4 namen voor groepen van cellen gedefinieerd:
- Landen (cellen C4:C35)
- LandKop (C3)
- Sterkte (C4:E35)
- GroepSchema (H3:I8)
In het vervolg van de spreadsheet wordt hier naar verwezen (meer over het gebruik van namen: zie het artikel van 31 mei 2014).
Werkblad Groepsfase
Nu begint het al wat leuker te worden! In dit blad zitten her en der wat aardige Excel-mogelijkheden ‘verstopt’.
Groeperen
Waarschijnlijk vallen de +-tekens aan de bovenkant en links meteen op. Hieraan is te zien, dat er (werk)-kolommen en -rijen zijn verborgen, zodat alleen de belangrijkste onderdelen van het overzicht getoond worden.
Klik op een plus-teken en je kunt zien wat er ‘ achter’ zit; klik dan weer op het min-teken en de zaak wordt weer verborgen.
LET OP: ik heb niet de optie Kolommen of Rijen verbergen gebruikt; daarbij valt het te weinig op, dat er iets verborgen is. Nee alles is uitgevoerd met behulp van de optie Groeperen: kies aaneengesloten rijen of kolommen, die je tijdelijk niet wilt zien, door de betreffende koppen te selecteren en ga naar de menu-optie Gegevens. In het onderdeel Overzicht zie je de optie Groeperen.
Maar makkelijker: heb je de kolommen of rijen geselecteerd, druk dan de toetscombinatie Shift-Alt-Rechts in. Degroeperen gaat op een vergelijkbare manier (Shift-ALt-Links). Met Rechts en Links bedoel ik de cursortoets naar rechts cq. links.
Verschuiving
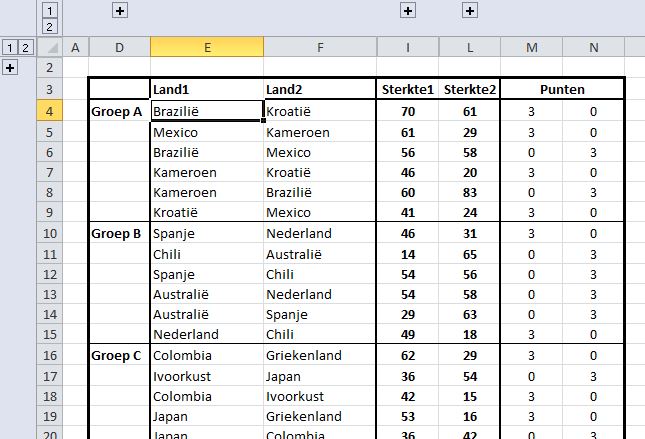
Nu gaan we naar wat steviger kost; kijk eens naar cel F13:
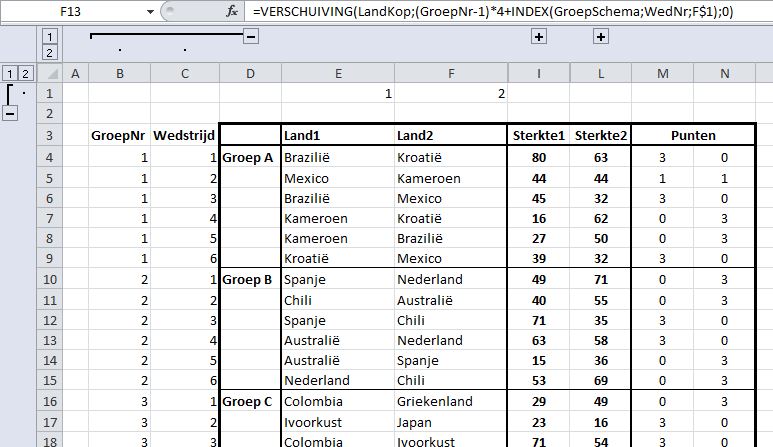 Om deze spreadsheet nog vaker te kunnen gebruiken, moet het systeem zelf afleiden welk land op die plaats moet komen staan: het moet Land2 zijn (info in cel F1) in de 4e wedstrijd (cel C13) van de 2e groep (cel B13).
Om deze spreadsheet nog vaker te kunnen gebruiken, moet het systeem zelf afleiden welk land op die plaats moet komen staan: het moet Land2 zijn (info in cel F1) in de 4e wedstrijd (cel C13) van de 2e groep (cel B13).
Uit het groepschema weten we, dat de 2e ploeg in de 4e wedstrijd in iedere groep het 2e land uit die groep is.
In Excel vinden we dat met de formule: INDEX(GroepSchema;WedNr;F1)
(zoek in Groepschema de rij op die overeenkomt met WedNr en daarbinnen de kolom, zoals vermeld in cel F1; in dit geval rij 4, kolom 2; voor meer informatie over zoeken via INDEX, zie ook het artikel Alternatief zoeken).
Ik maar hier gebruik van een heel handige eigenschap van het gebruik van Namen binnen Excel: WedNr is een reeks cellen, die loopt van C4 tot en met C51; wanneer je ergens in een cel daarnaast naar deze range verwijst via de naam (in dit voorbeeld vanuit cel F13), dan haalt Excel alleen de corresponderende cel in dezelfde rij op (dus hier C13, die de waarde 4 heeft), dus niet de hele reeks!
In het werkblad Invoer staan alle landen onder elkaar: eerst Groep A (de eerste groep), dan Groep B etc.
Om het land te vinden, dat in cel F13 moet komen, is het dus niet voldoende om te weten dat het het 2e land is maar moeten we ook nog weten in welke groep.
Het 2e land in de eerste groep staat in de landenkolom op de 2e plaats, het 2e land uit de 2e groep op 6, uit groep 3 op 10 etc.; telkens 4 verder dus.
Vandaar dat bij het hiervoor gevonden landnummer nog (GroepNr-1)*4 opgeteld moet worden om op de juiste plaats in de landenkolom terecht te komen (in dit geval gaat het om groep 2, dus komt er 4 bij en wordt het landnummer 6).
Met behulp van de functie INDEX zouden we nu in de reeks met de naam Landen kunnen zoeken, want we weten in welke rij we moeten zijn.
Ik heb deze keer voor een alternatieve manier gekozen: de functie VERSCHUIVING.
Met VERSCHUIVING geef je naast een verwijzing naar een bepaalde cel ook aan, dat je wat verder naar beneden (of naar boven!) en/of naar rechts of links wilt uitkomen.
In dit geval willen we dus vanuit de LandKop gerekend x rijen naar beneden en 0 kolommen naar links of rechts zoeken, ofwel
=VERSCHUIVING (LandKop; x; 0)
Maar de x kenden we ook al; die hebben we hiervoor afgeleid, dus de functie die we nodig hebben is:
=VERSCHUIVING(LandKop;(GroepNr-1)*4+INDEX(GroepSchema;WedNr;E$1);0)
Nu we deze formule eenmaal hebben, kan die ook naar de overige cellen in E en F gekopieerd worden.
Wie wint een wedstrijd?
In de kolommen G en H staan de grenzen voor het eerste land uit de corresponderende rij (opgezocht m.b.v. INDEX en VERGELIJKEN; zie het artikel Alternatief zoeken), in de kolommen J en K idem voor het tweede land.
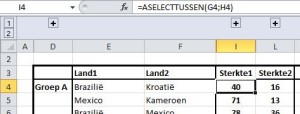 Als we kijken naar cel I4, dan zien we de formule =ASELECTTUSSEN(G4;H4).
Als we kijken naar cel I4, dan zien we de formule =ASELECTTUSSEN(G4;H4).
In dit geval wordt er voor Brazilië willekeurig een getal gekozen tussen zijn onder- en bovengrens (deze keer leverde dat 40 op; druk je op de functietoets F9 dan zal er hoogstwaarschijnlijk een ander getal komen).
In de kolommen M en N verdelen we de punten per wedstrijd via een dubbele ALS-formule; in cel M4 is dat =ALS(I4>L4;3;ALS(I4=L4;1;0)).
Als de sterkte van Brazilië groter is dan die van Kroatië krijgen ze 3 punten, als de sterktes gelijk zijn dan 1 punt, anders 0 punten.
De volgende keer ga ik verder met de uitleg van de overige gebruikte functies en de VBA.
Voortschrijdend inzicht
Nu de eerste wedstrijden zijn gespeeld, is er misschien iets meer duidelijkheid gekomen over de sterkte van de landen. In ieder geval kennen we al wat uitslagen en kent het model dus iets minder onzekerheden.
Wat kun je nu doen:
- download eventueel nog een keer de WK-voetbal voorspeller
- als je wilt kun je op het werkblad Invoer nog wat sterktes aanpassen (Nederland toch maar gelijk maken aan Brazilië??, de sterkte van Spanje flink verlagen??)
- vul op het werkblad Groepsfase de bekende uitslagen in:
Brazilië – Kroatië: 3-1; in cel I4 komt een 3 en in cel L4 een 1
Spanje – Nederland: 1-5; in cel I10 een 1 en in cel L10 een 5 - vul ook de andere uitslagen in
- wis op het werkblad MC de vorige run(s) en laat Monte Carlo ongeveer 500 keer zijn werk doen; dat is voldoende om een goed beeld te krijgen van de mogelijke resultaten (volgens het model is de kans, dat Nederland wereldkampioen wordt door de uitslagen tot nu toe, verdubbeld!).
- sla het spreadsheet onder een andere naam op: WK2014 Uitslagen.xlsm