Binnen ieder bedrijf is het van belang om zoveel mogelijk processen te standaardiseren en vaak ook te automatiseren.
Ook wanneer we Excel als hulpmiddel bij ons werk gebruiken is het belangrijk om zoveel mogelijk handmatige handelingen, die regelmatig terugkomen, te vermijden. Power Query, draaitabellen, en VBA kunnen daarbij een grote rol spelen.
Voor diegene, die vaak verschillende rapportages moeten maken, is een andere invalshoek belangrijk. Ga niet voor iedere nieuwe rapportage weer opnieuw het wiel uitvinden, maar gebruik een flexibel stramien. Hoe dat in zijn werk gaat zullen we in dit artikel aan de hand van een direct inzetbaar Voorbeeldbestand laten zien.
Bedrijf
Het eerste tabblad van het Voorbeeldbestand, Bedrijf, bevat diverse bedrijfsspecifieke gegevens, inclusief een logo.
NB1 wanneer je dit logo vervangt (door er rechts op te klikken) zorg dan dat het nieuwe plaatje een transparante achtergrond heeft.
NB2 diverse cellen in dit tabblad (en ook op andere plaatsen in de werkmap) hebben een naam gekregen, die in de rest van het rapportage-stramien gebruikt worden. Cel C2 bijvoorbeeld heeft de naam BedrNaam.
In cel C8 wordt de meest recente datum uit het Data-bestand (zie hierna) opgehaald met behulp van de functie MAX. De inhoud van cel C9 bepaalt of deze datum als referentie dient voor de rapportage of een andere (cel C10).
NB3 op diverse plaatsen in dit stramien zul je zien dat de invoer in cellen beperkt is met behulp van Gegevensvalidatie; zie bijvoorbeeld de cel C9 (alleen Ja en Nee zijn toegestaan).
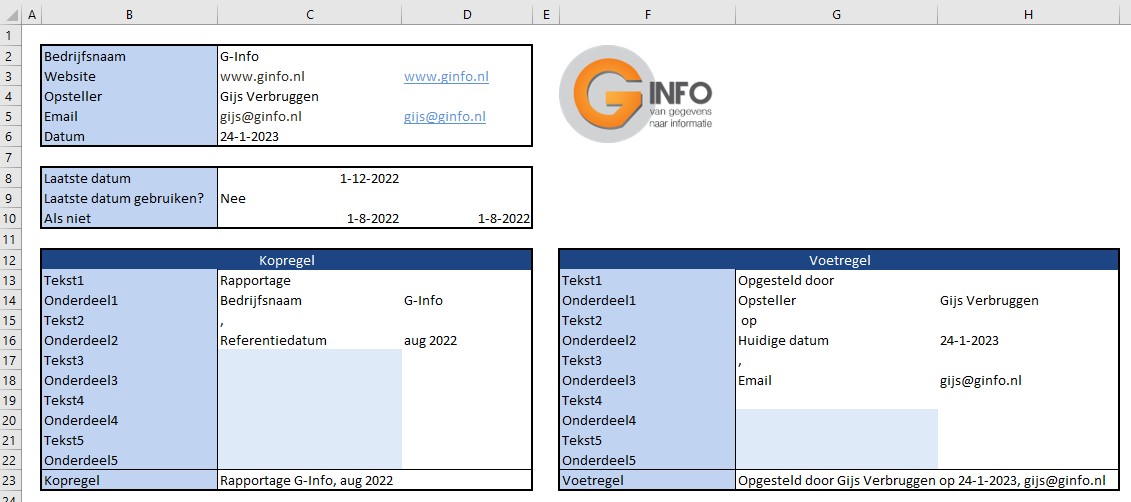
In de regels 13 tot en met 22 kun je zelf de diverse onderdelen (en teksten) kiezen die in de kop- en voetregel van een rapportage moeten komen.
NB4 in cel G19 staat een spatie om er voor te zorgen dat de voetregel aan de rechterkant niet tegen de rand aan komt.
Experimenteer met de mogelijkheden en beoordeel het effect op de rapportages in de tabbladen Ovz1 en Ovz2.
Basis-instellingen
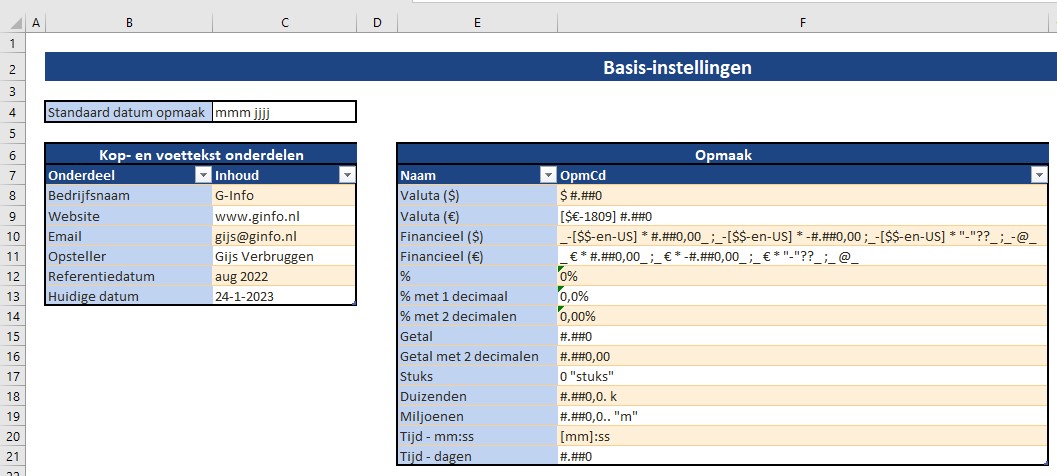
Het tabblad Basis van het Voorbeeldbestand begint met een standaardopmaak voor datums (in dit geval hebben we gekozen voor 3 letters voor de maand, een spatie en 4 cijfers voor het jaar). Daaronder staan 6 items die als onderdeel voor de kop- en voetregels kunnen dienen. In het blok in de kolommen E en F staan diverse opmaak-omschrijvingen en -codes die bij het weergeven van gegevens in de rapportage gebruikt kunnen worden.
NB aangezien alle keuze-items in Excel-tabellen zijn opgenomen zal een gewenste uitbreiding van de opties direct overal in de werkmap geëffectueerd worden.
Overige instellingen
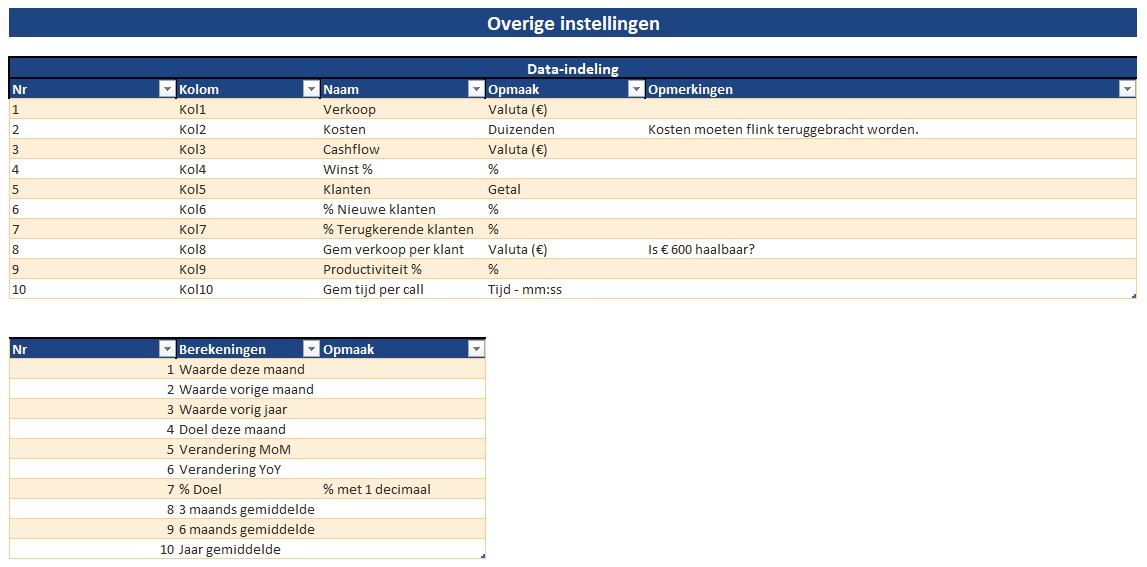
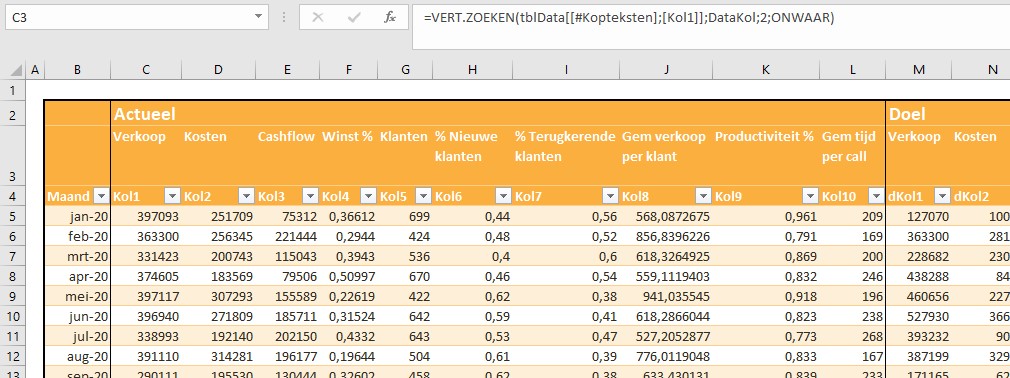
In het eerste blok van de Overige instellingen (zie het tabblad Instel van het Voorbeeldbestand) wordt van maximaal 10 items vastgelegd wat de inhoud is, welke opmaak uit de lijst van het tabblad Basis deze moeten hebben en eventuele opmerkingen er in de rapportage moeten worden weergegeven. Voor uw eigen rapportage moeten/kunnen de kolommen Naam, Opmaak en Opmerkingen aangepast worden.
Daaronder staat een Excel-tabel met daarin de omschrijvingen van de berekeningen die op de gegevens kunnen worden toegepast. De berekeningen zelf staan op het tabblad Berekeningen. Ook hier zult u voor uw eigen rapportage aanpassingen moeten doorvoeren en wel in de tweede en derde kolom.
NB in het voorbeeld-stramien staan 10 berekeningen, maar dit mogen er ook meer (of minder) zijn.
LET OP de opmaak van berekende items is standaard gelijk aan de opmaak van de onderliggende data; in het voorbeeld hierboven zal de opmaak van Waarde deze maand in het geval van Verkoop-cijfers gelijk zijn aan Valuta, maar die van Klanten heeft dus de opmaak Getal. Maar bij berekening 7 (in dit geval) geven we aan dat alle items hiervan de opmaak % met 1 decimaal zullen hebben.
Als laatste geven we nog aan wat voor een soort rapportage het hier betreft. Er zijn 2 mogelijkheden: alleen de data van het lopende jaar worden getoond (YtD = Year to Date) of altijd de laatste 12 maanden (YoY = Year on Year).
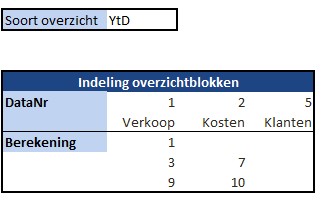
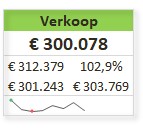
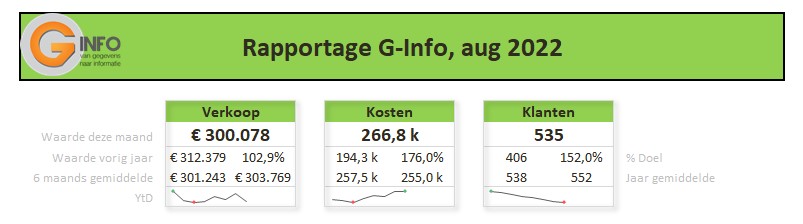
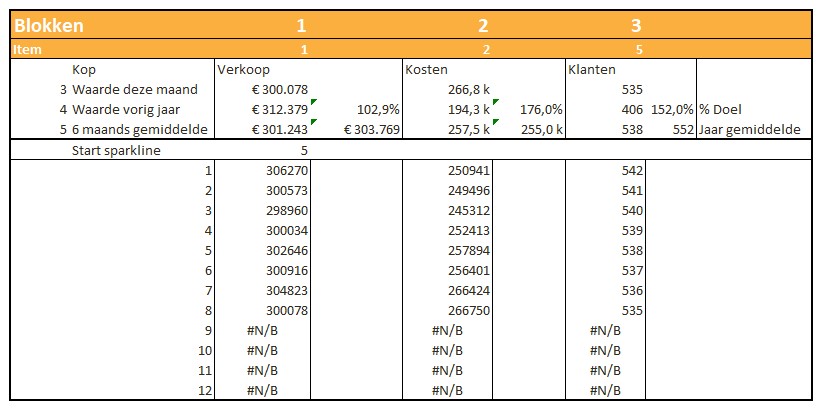
Iedere rapportage-pagina heeft bovenaan 3 blokjes met de belangrijkste gegevens/berekeningen. Bij Indeling overzichtsblokken wordt bij DataNr allereerst aangegeven welke 3 van de 10 items moeten worden getoond; bij Berekening kun je 5 opties kiezen die voor deze items moeten worden weergegeven.
De sparkline daaronder geeft het verloop in de tijd weer van het betreffende item (YtD of YoY). Met de instellingen zoals hierboven is het resultaat:
Data
In het Voorbeeldbestand is het tabblad Data gevuld met fictieve gegevens. Het systeem is beperkt tot 10 kolommen met gegevens waarvan de namen vastliggen in het tabblad Instel.
Per maand dienen alle gewenste kolommen met de juiste data gevuld te worden. Gebruik je ook berekeningen waarbij de actuele gegevens afgezet worden tegen de beoogde resultaten dan dienen ook de Doel-kolommen gevuld te worden.
Berekeningen
In het tabblad Berekeningen van het Voorbeeldbestand worden allereerst van alle 10 items (en de daarbij behorende doelen) de YoY-data opgehaald.
Daaronder wordt de opmaak van (nu) maximaal 16 berekeningen per item bepaald. De betreffende formule is uitdagend te noemen: =ALS(INDEX(tblBerekOpties[Opmaak];[@Nr])=0;INDEX(tblOpmaak[OpmCd];VERGELIJKEN(INDEX(tblDataInd[Opmaak];VERGELIJKEN(tblYoY[[#Kopteksten];[Kol1]];tblDataInd[Kolom];0));tblOpmaak[Naam];0));INDEX(tblOpmaak[OpmCd];VERGELIJKEN(INDEX(tblBerekOpties[Opmaak];[@Nr]);tblOpmaak[Naam];0)))
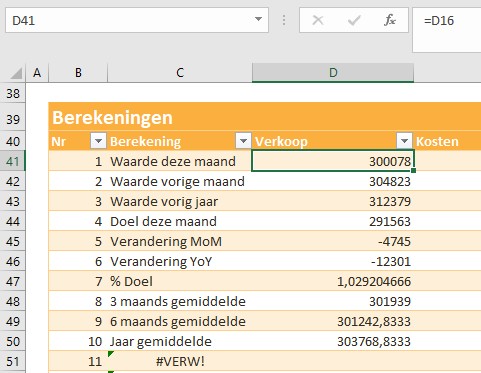
In het derde blok worden de benodigde berekeningen gedefinieerd. In cel D41 staat een simpele verwijzing naar een cel uit het eerste blok.
De formule waarmee berekening 8 (het gemiddelde van de laatste 3 maanden) wordt uitgevoerd, is: =GEMIDDELDE(VERSCHUIVING(D16;-2;0;3;1)) ofwel we gaan vanaf cel D16 2 regels omhoog en 0 kolommen naar rechts/links en kiezen dan een blok cellen, 3 hoog en 1 breed; van deze range wordt het gemiddelde bepaald.
Nog even de vorige 2 stappen combineren met (in cel D61) de formule: =ALS.FOUT(TEKST(D41;D21);0)
Dus met de functie TEKST wordt de inhoud van cel D41 opgemaakt met de inhoud van cel D21. Als dit onverhoopt een probleem oplevert, dan wordt de waarde 0 weergegeven.
Met al dat voorwerk kunnen we nu de blokjes in de kop van de rapportages samenstellen. Ook de cijfers voor de sparklines worden klaar gezet.
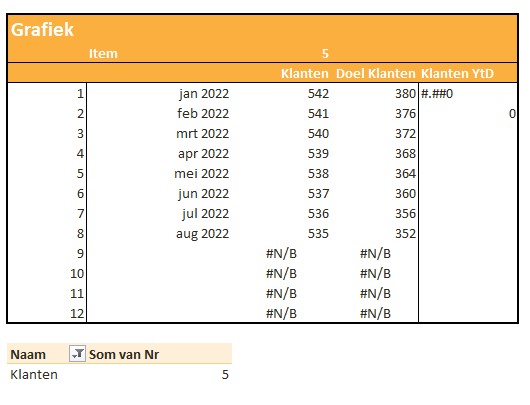
Omdat we ook een grafiek in de rapportage willen opnemen, moeten we de benodigde gegevens nog even klaar zetten.
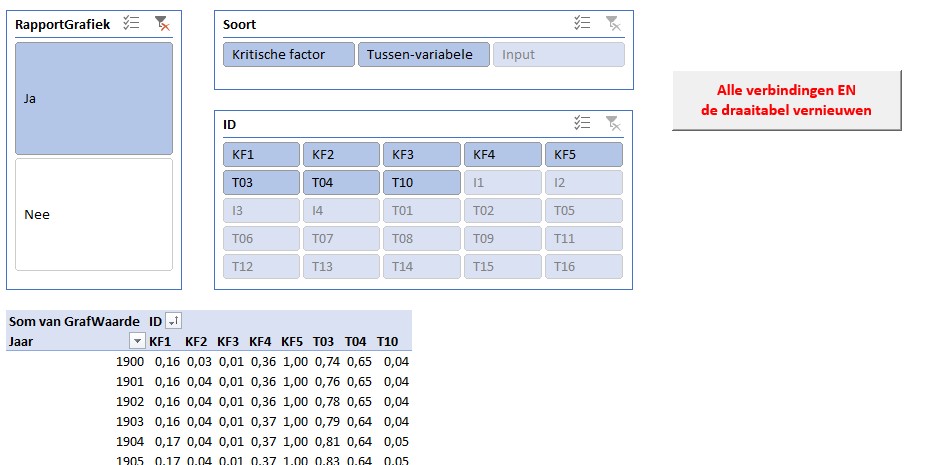
Onderaan staat een draaitabel. Een Slicer in de rapportage bepaalt welk item we willen weergeven. Het betreffende nummer gebruiken we in het grafiekblok.
Rapportage-pagina’s
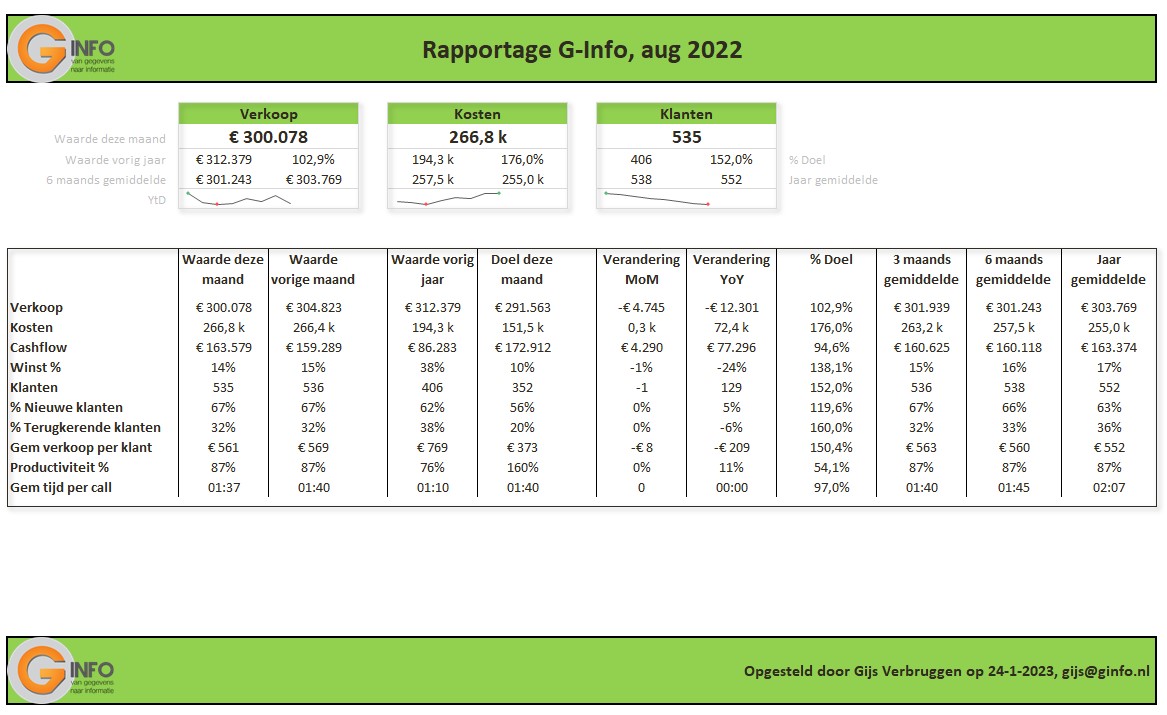
In het tabblad Ovz1 van het Voorbeeldbestand staat een eerste voorbeeld van een rapportage gebaseerd op alle berekeningen uit de rest van het werkblad. Wijzigingen in de diverse tabbladen hebben direct effect op het resultaat. Kies in de slicer aan de rechterkant van de grafiek een ander item en je krijgt de bijbehorende grafiek.
Wil je naast de drie belangrijkste items met de berekeningen in de blokjes aan de bovenkant van de pagina alle info in één oogopslag: zie het tabblad Ovz2 van het Voorbeeldbestand.
Uiteraard is dit nog geen totaal rapportage; ongetwijfeld kunt u nog andere invalshoeken vinden die van belang zijn. Kopieer een Ovz-tabblad en ga aan de slag!
LET OP: na het downloaden de extensie wijzigen in xlsb
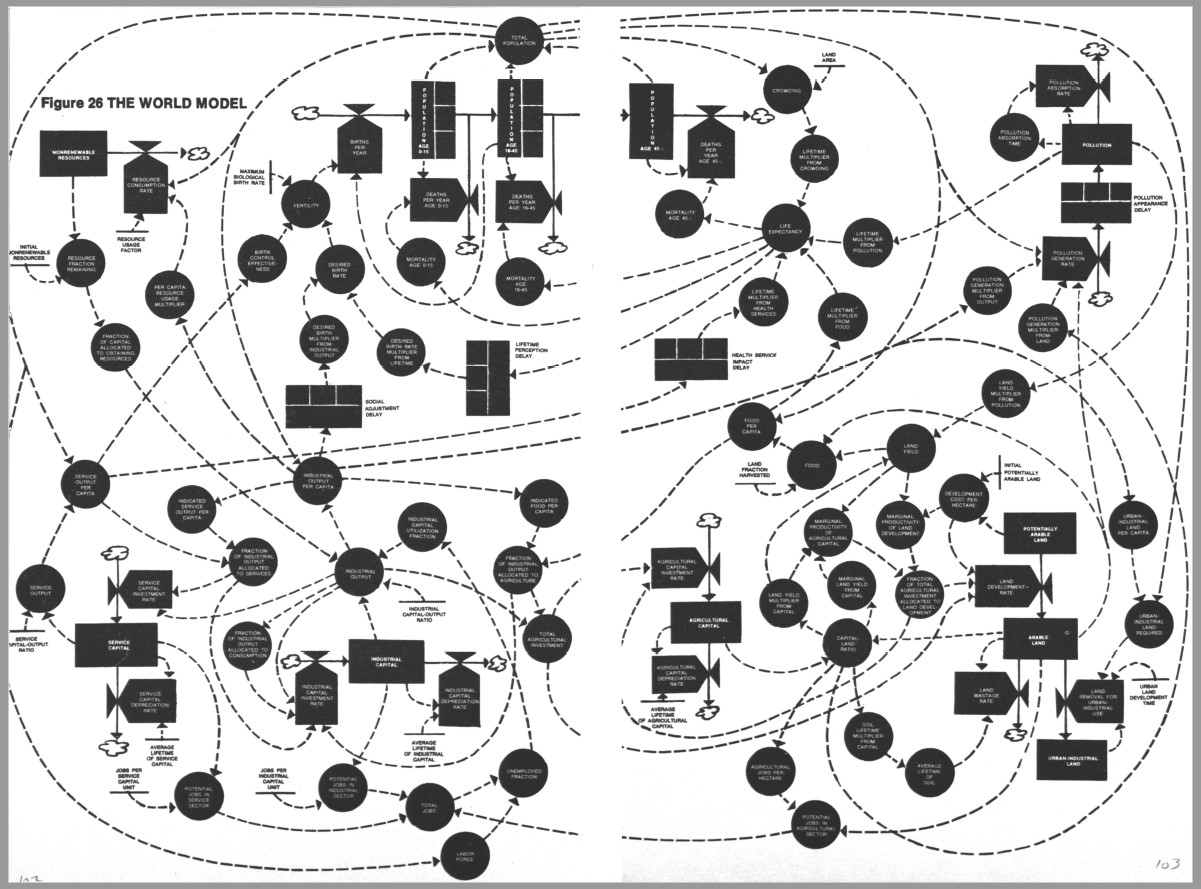
In het vorige artikel (Grenzen aan de groei – 1) hebben we beloofd dat we een poging zouden wagen om het model uit het rapport van de Club van Rome in Excel te implementeren, althans een vereenvoudigde versie daarvan. In dat artikel is te lezen hoe we dat zouden willen doen en aan de hand van wat vingeroefeningen hebben we laten zien dat het (in theorie) mogelijk zou moeten zijn.
Die laatste conclusie staat nog steeds, maar helaas hebben we wel moeten constateren dat de hoeveelheid verbanden tussen de diverse variabelen en de daarbij behorende parameters zo groot is dat een totale implementatie heel erg veel tijd gaat kosten. Dus deze keer vormt het Voorbeeldbestand geen afgerond project. In dit artikel zullen we laten zien hoe ver we gekomen zijn en welke Excel-opties daarbij zijn gebruikt.
Voor eenieder de uitdaging om de ‘handdoek in de ring’ weer op te rapen en het model verder uit te werken!
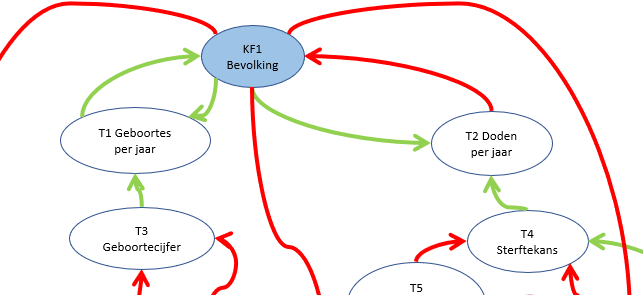
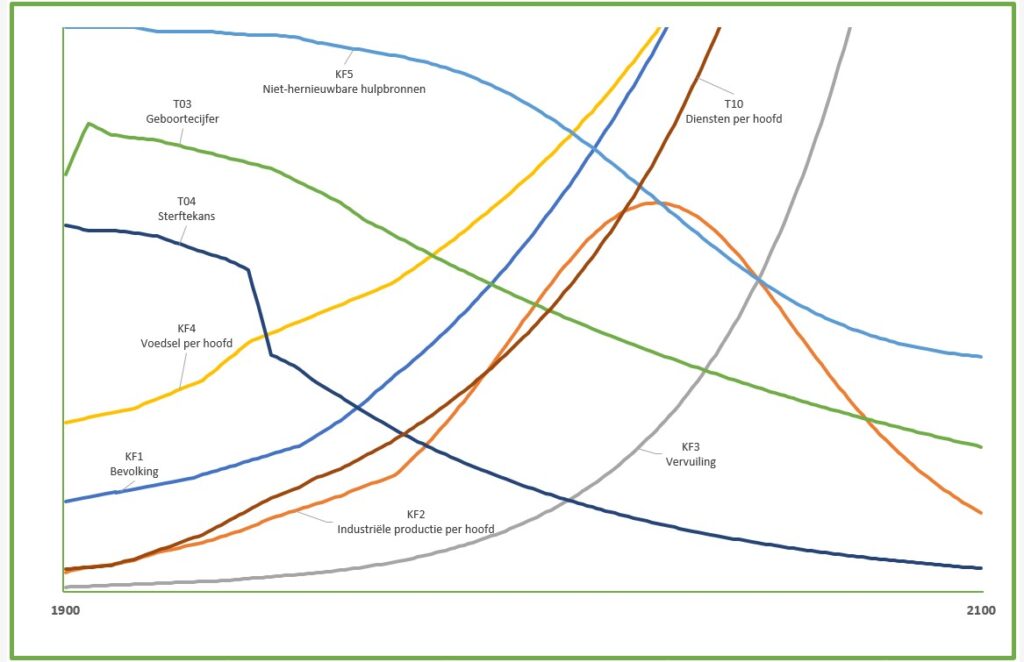
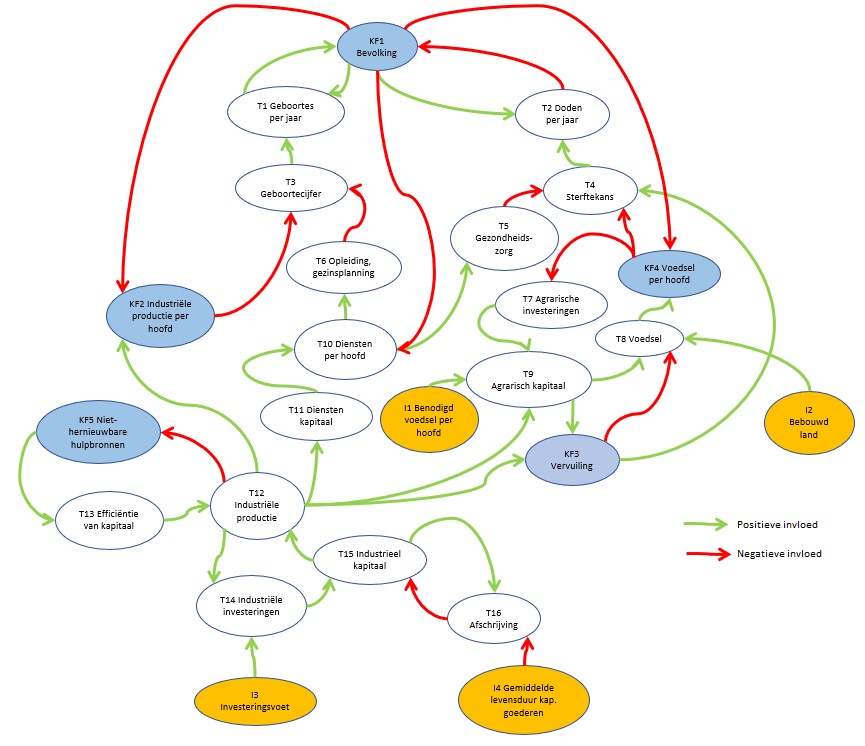
Dit is een schematische weergave van het (vereenvoudigde) ‘Club van Rome’-model; voor nadere uitleg zie het vorige artikel.
Belangrijk om te weten is het volgende:
de pijlen geven aan welke relaties er tussen de variabelen zijn onderkend
de pijlen laten zien in ‘welke richting’ de beïnvloeding loopt
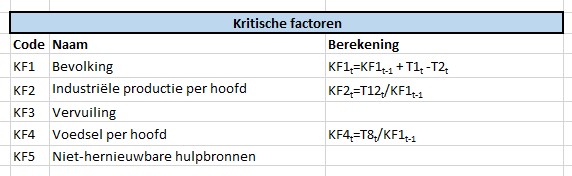
we onderkennen in het model 3 soorten variabelen: de Inputs, de Kritische Factoren en de Tussen-variabelen. De Input-variabelen worden niet beïnvloed door de omgeving, maar kunnen wel in de loop van de jaren variëren. De KF’s zijn die 5 variabelen die in alle grafieken van het rapport terugkomen. Alle overige vallen onder de categorie Tussen-variabelen.
het rapport van de Club van Rome is in 1972 gepubliceerd; waar in dit artikel naar het verleden wordt verwezen bedoelen we dan ook de periode van 1900 tot en met 1970.
voor diverse variabelen is in de literatuur (zie het tabblad Docu van het Voorbeeldbestand) te achterhalen wat de waardes in het verleden zijn geweest. Dit is de eerste basis van de implementatie van het model.
bij de verdere implementatie heeft iedere variabele een eigen tabblad gekregen (behalve de Inputs; zie hierna). Alle aannames voor de berekening van een variabele staan in het betreffende tabblad vermeld. Vaak is daar ook een grafiek opgenomen van die variabele om snel het resultaat van de aannames te controleren.
Tabblad T15
Implementatie
Tabblad Beschr
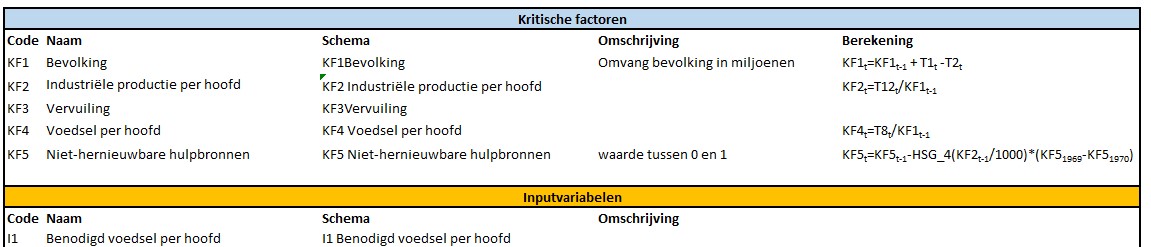
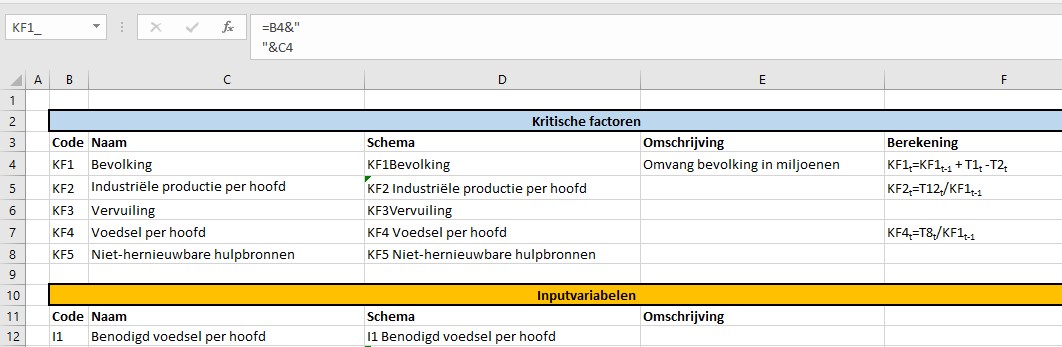
In dit tabblad van het Voorbeeldbestand staat een overzicht van alle gebruikte variabelen met daarbij (zover al uitgezocht) de meest relevante berekening:
De betekenis van de Code en de Naam moge duidelijk zijn; de kolom Schema bevat de tekst zoals die op het tabblad SystemDynamics wordt gebruikt. In de kolom Omschrijving staat in het kort een nadere toelichting op de variabele en de laatste kolom bevat de (belangrijkste) formule voor de berekening van die variabele.
NB de codes onder de 10 voor de Tussenvariabelen hebben een extra 0 gekregen; dit om bij standaard-sorteringen altijd direct de juiste volgorde te hebben (anders zou bijvoorbeeld T10 vóór T2 komen).
Tabblad Inputs
Dit tabblad bevat de gegevens van de 4 Input-variabelen. Deze vormen samen de Excel-tabel tblInputs.
Op dit moment zijn alleen de I3 en I4 gevuld en per kolom hebben alle jaren dezelfde waarde. De juiste interpretatie van deze variabelen vergt nog onderzoek.
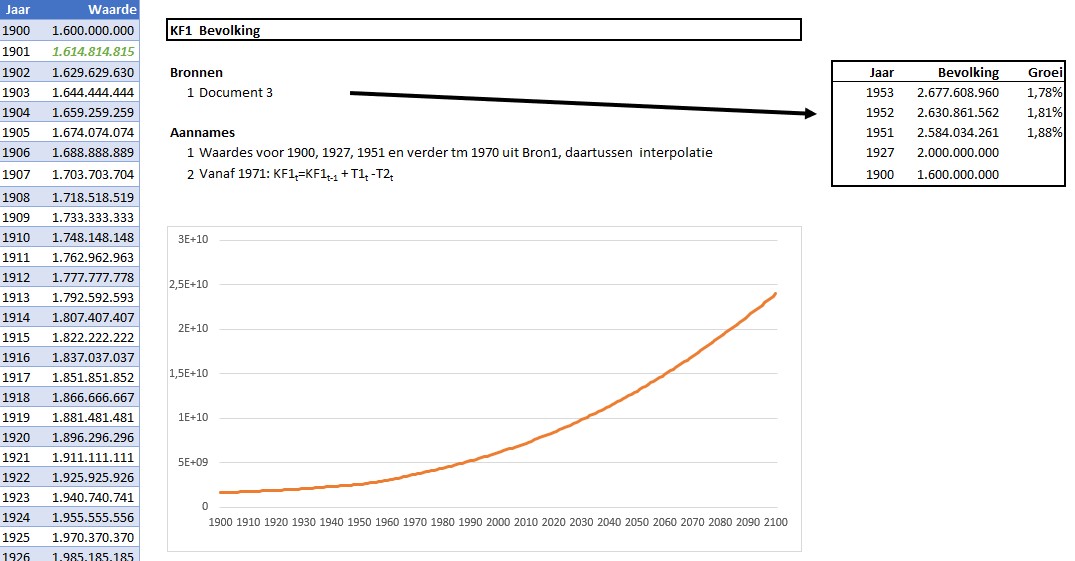
De KF-tabbladen
Zoals gezegd hebben alle KF’s (en ook de Tussen-variabelen) een eigen tabblad. Deze bladen hebben allemaal dezelfde structuur: de eerste kolom bevat de jaren en de tweede kolom de daarbij behorende waarde. Samen vormen deze 2 kolommen een Excel-tabel met een overeenkomende naam (in bovenstaand voorbeeld tblKF1).
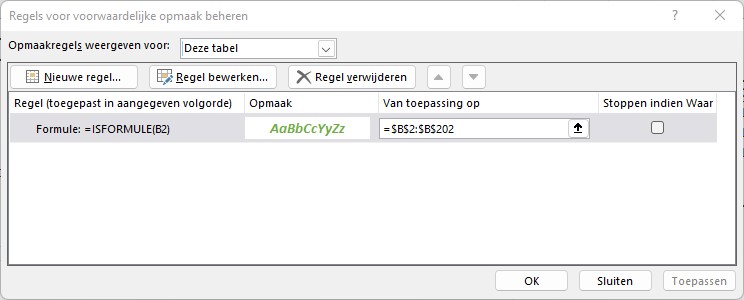
NB de waarde-kolom heeft een voorwaardelijke opmaak: wanneer een cel een formule bevat dan wordt de inhoud in het groen, vet en cursief weergegeven.
In de volgende kolommen staat altijd de code en naam van de variabele, eventueel gebruikte bronnen en de diverse aannames. De rest van het tabblad wordt gebruikt om zo nodig extra berekeningen uit te voeren, de aannames toe te lichten etcetera.
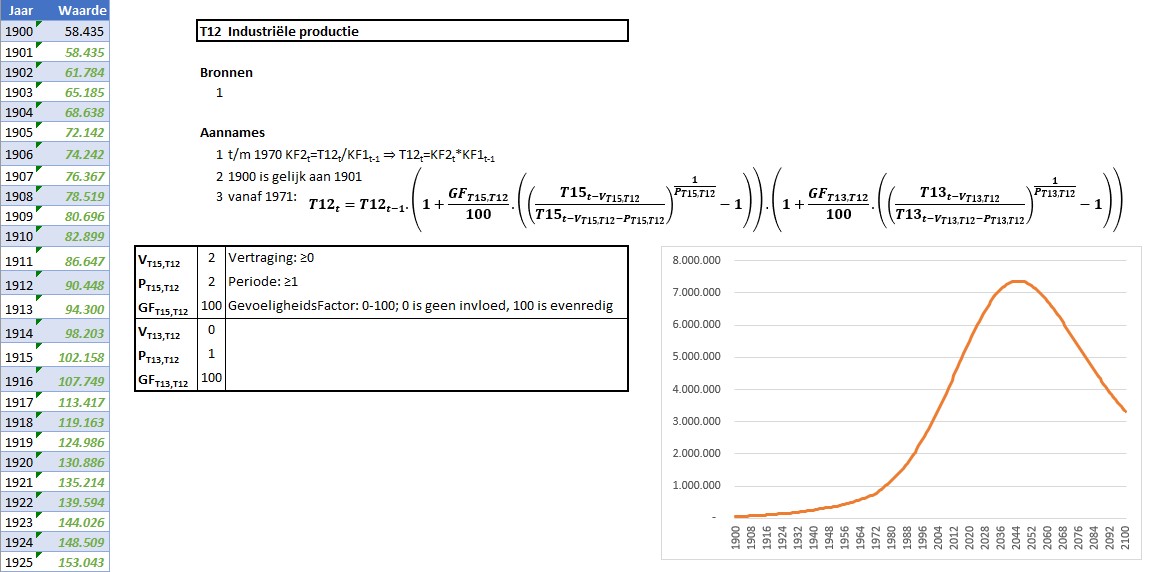
Zoals aangegeven hebben deze tabbladen dezelfde structuur als de KF’s. In het voorbeeld hierboven is te zien dat voor T12 een formule wordt gebruikt, waarbij de gevoeligheid (GF) voor de invloed van een variabele kan worden ingesteld. Daarnaast kan aangegeven worden of de beïnvloeding een vertraging V kent en of er over een periode P gemiddeld moet worden (zie het artikel Grenzen aan de groei – 1).
LET OP in dat artikel hebben we, bij het gebruik van een periode, een rekenkundig gemiddelde gebruikt. Dat is, theoretisch gezien, niet juist. Hoewel dat in dit model, bij niet te grote ontwikkelingen in de tijd, niet echt relevant is, hebben we toch de betere methode gehanteerd waarbij het gemiddelde wordt bepaald met behulp van de Pde-machts wortel (ofwel tot de macht 1/P).
Resultaten
In principe zijn de resultaten van het model bekend als alle tabbladen zijn gevuld met waardes en formules. Door ’te spelen’ met de aannames, en vooral met de eventuele GF-, V– en P-waardes kan het model gefinetuned worden.
We zijn gestart met de onderkant van het model, het gedeelte rond de Industriële productie. De bovenkant is op de uitkomsten daarvan gebaseerd. Het implementeren van deze onderkant heeft heel wat hoofdbrekens gekost (wat is de betekenis van de variabelen, hoe zijn deze variabelen van elkaar afhankelijk, hoe kunnen we de afhankelijkheid modelleren, welke GF-, V– en P-waardes geven een zo getrouw mogelijk beeld van de werkelijkheid etcetera).
Door tijdgebrek moet G-Info het verder vullen van het model dan ook aan anderen overlaten.
Wel zullen we hieronder nog laten zien op welke manier de resultaten in Excel gemakkelijk kunnen worden weergegeven.
Tabblad Variabelen
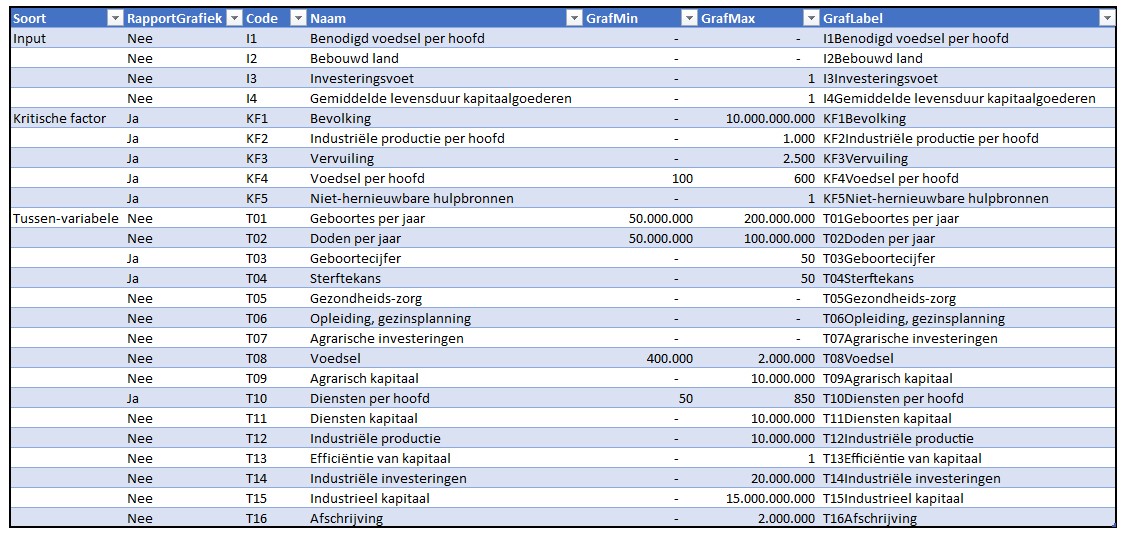
Op dit tabblad in het Voorbeeldbestand staan de 25 variabelen van het model nogmaals in een overzicht. Maar ditmaal met aanvullende gegevens, waarmee we de lay-out van de output kunnen sturen:
in de eerste kolom staat aangegeven welk soort variabele het betreft: Input, KF of Tussen
de tweede kolom geeft aan of de betreffende variabele in de standaard-grafieken van het rapport van de Club van Rome is opgenomen
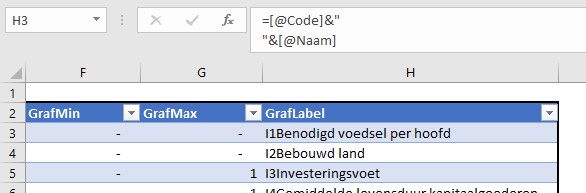
in dat rapport wordt een variabele altijd op dezelfde (onzichtbare) schaal weergegeven. Dat kunnen we nabootsen door aan te geven welke waarde van de variabele overeenkomt met de onderkant van het grafiekgebied (de kolom GrafMin) en welke waarde met de bovenkant (GrafMax)
in de laatste kolom staat een formule waarmee het label bij de betreffende lijn in de grafiek wordt bepaald. Standaard is het een combinatie van de 3e en 4e kolom, gescheiden door een ‘harde return’:
Dit overzicht is een Excel-tabel met de naam tblVar.
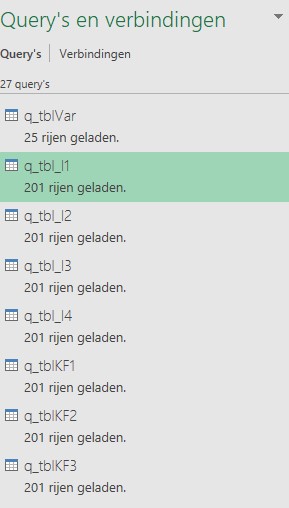
Query’s en verbindingen
Alle resultaten moeten nu nog geschaald worden. Dit kan uiteraard op de diverse tabbladen zelf door extra kolommen toe te voegen, maar we hebben er voor gekozen om dit met behulp van Power Query te implementeren.
NB1 Ziet u de Excel-verbindingen aan de rechterkant van het scherm niet, kies dan in de menutab Gegevens de optie Query’s en verbindingen.
Voor alle Excel-tabellen is een verbinding gemaakt. Wil je bekijken hoe die er uit ziet? Klik rechts op een verbinding en kies de optie Bewerken (of dubbel-klik op een query-naam).
NB2 de Input-query’s zijn iets ingewikkelder omdat daar één specifieke kolom uit de input-tabel moet worden opgehaald.
Bij het bewaren van de query’s is de optie Alleen verbinding maken gekozen en is de optie Toevoegen aan gegevensmodel aangevinkt. Die laatste optie zorgt er voor dat de query’s in het gegevensmodel van deze Excel-sheet worden opgeslagen.
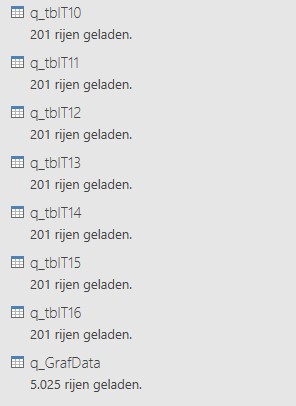
Het gegevensmodel bevat nog één extra query, q_GrafData. Deze combineert alle andere verbindingen tot één database. Deze database vormt de basis voor een draaitabel en een daarbij behorende grafiek. Ook deze query is opgeslagen met de eigenschappen Alleen verbinding en Toevoegen aan gegevensmodel.
Bekijk de query door dubbelklikken op de naam.
Tabblad GrafData
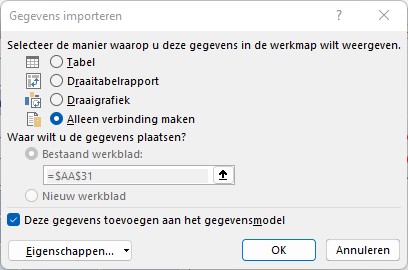
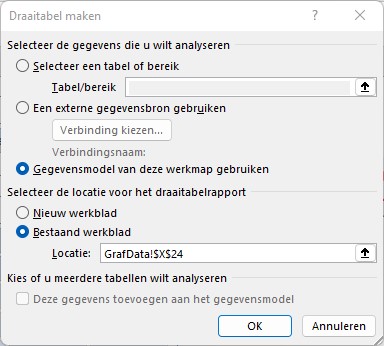
Op het tabblad GrafData van het Voorbeeldbestand staat een draaitabel, gebaseerd op de query q_GrafData. Hoe genereer je zo’n draaitabel?
selecteer een lege cel, waar de draaitabel moet komen
kies in de menutab Invoegen in het blok Tabellen de optie Draaitabel
in het pop-up scherm ziet u dat Excel het gegevensmodel zal gaan gebruiken:
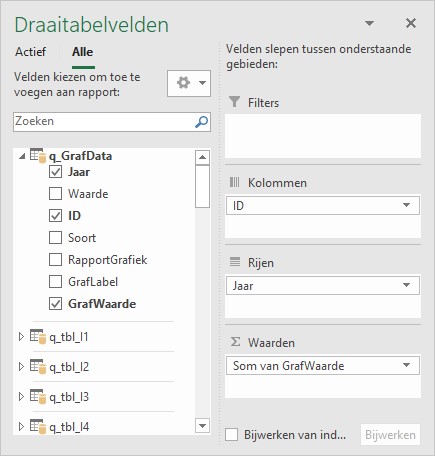
klik op het driehoekje vóór de gewenste query uit het gegevensmodel en sleep de benodigde velden naar de juiste plaats:
In het voorbeeld hebben we ook 3 slicers toegevoegd waarmee het maken van keuzes vergemakkelijkt wordt. Hierboven hebben we met een klik op Ja in de eerste slicer alleen die variabelen geselecteerd, die ook in het rapport van de Club van Rome in de standaard-grafieken voorkomen.
LET OP als er iets aan de parameters van het model wordt gewijzigd dan worden de gegevens op het betreffende tabblad direct gewijzigd. Ook resultaten van formules op andere tabbladen kunnen daardoor wijzigen. De query’s en de draaitabel wijzigen niet automatisch mee! Alles zal vernieuwd moeten worden. Op het tabblad GrafData wordt met één klik op de betreffende button een VBA-routine gestart die deze totale verversing van het Excel-systeem voor zijn rekening neemt. Dit kan wel enkele minuten duren!
Tabblad Grafiek
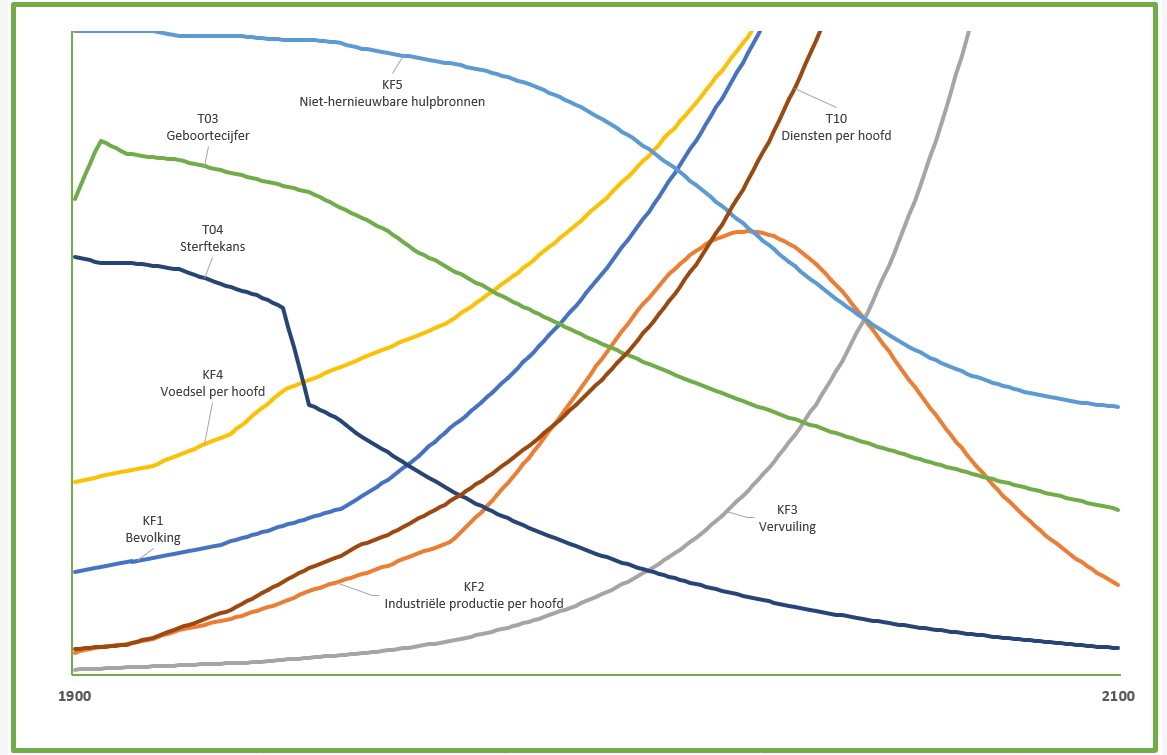
Het tabblad Grafiek van het Voorbeeldbestand bevat een draaitabelgrafiek. Dit is de grafische weergave van de gegevens van de draaitabel van het tabblad GrafData. Dus: ook keuzes gemaakt met de slicers worden in deze grafiek meegenomen.
Duidelijk is te zien dat de implementatie van het model nog lang niet klaar is. De industriële productie en de hulpbronnen geven bijvoorbeeld wel al een verwacht verloop, terwijl de blijvende toename van de bevolking of voedsel per hoofd niet reëel is. Het model in het Voorbeeldbestand is dan ook nog maar voor een klein gedeelte geïmplementeerd. Zoals gezegd: tijdgebrek noopt ons om de rest aan andere Excel-liefhebbers over te laten.
LET OP: na het downloaden de extensie wijzigen in xlsb
De oudere jongeren onder ons (of de jongere ouderen?) weten het nog wel: in 1972 (50 jaar geleden) verscheen het Rapport van de Club van Rome met als ondertitel De grenzen aan de groei.
Een pocketboekje dat een intensieve discussie op gang heeft gebracht: voor sommige mensen was het een eye-opener (we kunnen niet blijven doorgaan met het ongelimiteerd opsouperen van onze hulpbronnen, we moeten ‘de groei’ temperen), anderen wezen er op dat je met het onderliggende model alles kunt bewijzen (een Eindhovense professor formuleerde dat als ‘Met dit model kun je ook je eigen handtekening maken; een kwestie van de parameters aanpassen aan je wensen‘).
In het vorige artikel van G-Info is een voorbeeld uit het rapport langs gekomen om te laten zien hoe je Vergelijkingen/formules in Excel kunt schrijven. Een losse opmerking daarbij (‘Zou het model in Excel nagebouwd kunnen worden?“) is het begin van een zoektocht geworden. Gelukkig kwam daarbij al snel een vereenvoudigd model naar boven. Het begin van een uitdaging: kan dit model in Excel op een zodanige manier geïmplementeerd worden, dat in ieder geval de resultaten van de Club van Rome gereproduceerd worden?
In dit artikel eerst een korte achtergrond van het Rapport van de Club van Rome, een uitleg van het vereenvoudigde model en daarna wat vingeroefeningen om te laten zien hoe we denken dat de implementatie er uit kan gaan zien.
Rapport van de Club van Rome
Wikipedia: “De grenzen aan de groei is een rapport van de Club van Rome uit 1972 waarin de uitputtingsproblematiek centraal staat. Het rapport werd uitgewerkt door een team van het Massachusetts Institute of Technology (MIT) onder leiding van Dennis Meadows en Donella Meadows. Het rapport heeft grote invloed gehad op het milieubewustzijn.
Aan de basis van de studie ligt het gebruik van een systeemdynamisch model met computersimulatie van interacties tussen bevolking, industriële groei, voedselproductie en limieten in de ecosystemen van de aarde: het World3-model, mede ontwikkeld door Jay Forrester. Van deze variabelen werd de ontwikkeling van 1900 tot 1970 vastgesteld. Vervolgens werden de trends voortgezet, waarbij verschillende aannames werden gedaan. Ervan uitgaande dat geen belangrijke veranderingen plaats zouden vinden in de fysieke, economische en sociale relaties (het referentie scenario) waren de uitkomsten schokkend. De natuurlijke hulpbronnen zouden gaandeweg uitgeput raken en de industriële groei remmen. De bevolkingsomvang en vervuiling zouden nog enige tijd toenemen, maar de verslechtering van de voedselvoorziening en de gezondheidszorg leidden in eerste instantie tot stilstand en later tot terugloop in de bevolkingsgroei.“
Het rapport was niet zozeer bedoeld om kwantitatieve voorspellingen over de toekomst te doen (de leden van de Club en MIT’ers beseften terdege dat het model daarvoor veel te globaal en simpel was). Het diende als input voor de discussie over de groei van de wereldbevolking, ons consumptiepatroon en het gebruik van de natuurlijke grondstoffen en het effect van milieuvervuiling.
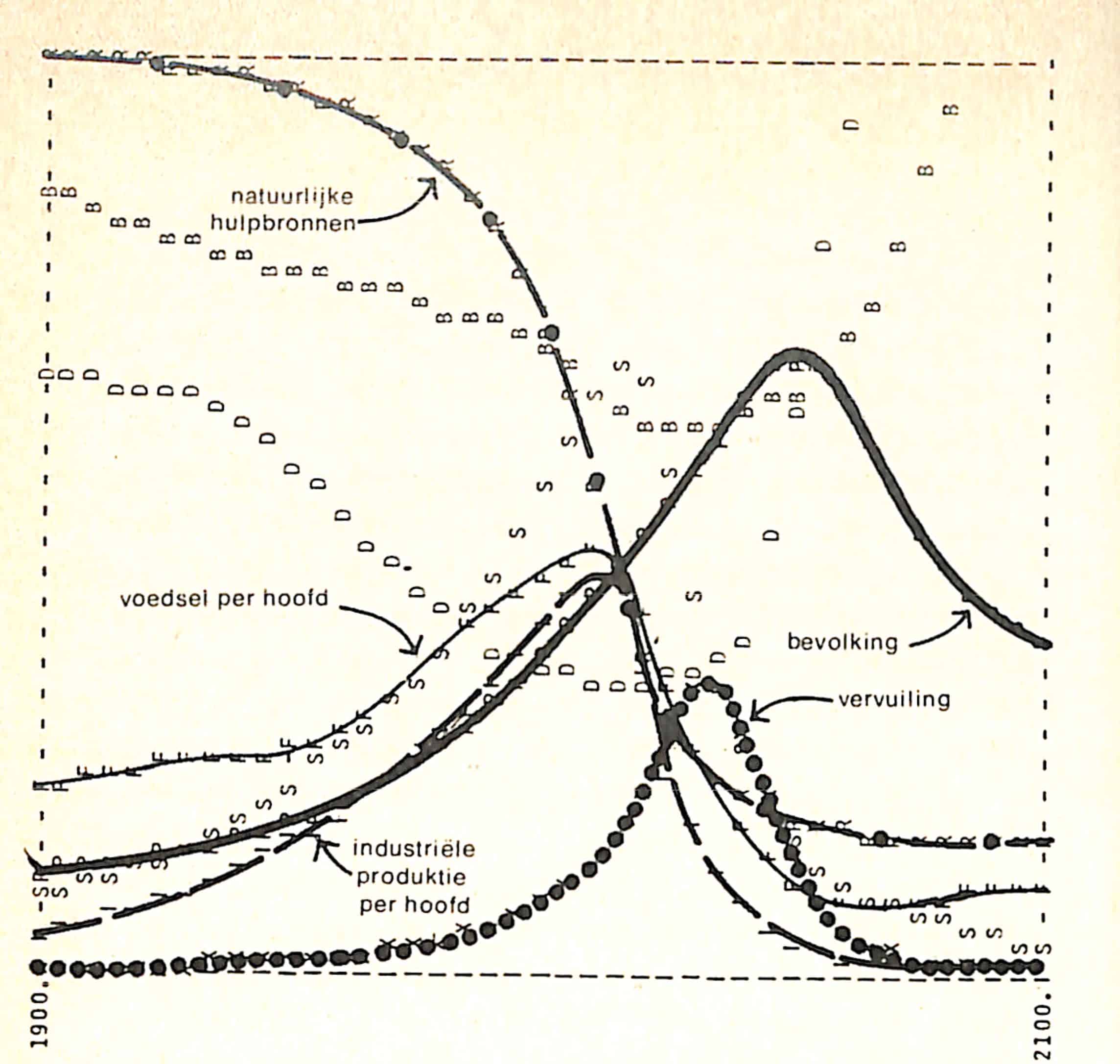
Het model is doorgerekend met diverse scenario’s. Hiernaast staat een grafische weergave van het resultaat van het standaard BAU-scenario (Bussiness As Usual). Daarin volgen alle variabelen van 1900 tot 1970 de historische waarden. De rest is door het model berekend op basis van de aanname dat “er geen belangrijke veranderingen plaatsvinden in de fysieke, economische of sociale relaties.“
De grafieken werden weergegeven door letters, waarna de belangrijkste variabelen met de hand werden ingetekend; B stelt het geboortecijfer voor, D het sterftecijfer en S de diensten per hoofd. Uit het rapport: “Elk van de variabelen is uitgezet op een verschillende schaalverdeling. We hebben met opzet de verticale schaalverdelingen weggelaten en de horizontale tijdas geen indeling gegeven, omdat we de nadruk willen leggen op de algemene gedragspatronen, niet op de numerieke waarden die slechts onnauwkeurig bekend zijn. Maar de schalen zijn in alle scenario’s gelijk, zodat de grafieken gemakkelijk vergeleken kunnen worden.“
Iedereen die geïnteresseerd is in de resultaten van de scenario’s moeten we doorverwijzen naar diverse publicaties. De Nederlandstalige versie van het rapport is nog te koop, de Engelstalige versie is in PDF-versie te downloaden.
Het idee om eens te kijken of we met Excel het BAU-scenario zouden kunnen reproduceren, leek bij bestudering van deze info niet haalbaar. Totdat ….
Een vereenvoudigd model
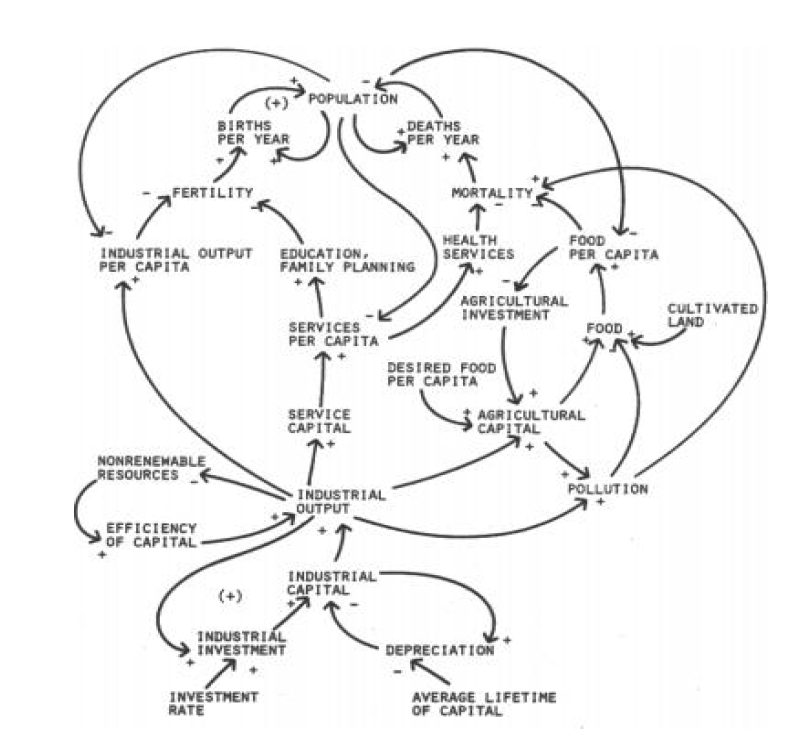
Bij de zoektocht op internet kwam ik een studie tegen waarin de resultaten van het oorspronkelijke model vergeleken werden met recente data. Ook is daar een vereenvoudigd model te vinden.
Dit model bestaat uit 25 variabelen. Dat moet te doen zijn en ook het aantal verbanden daartussen lijkt behapbaar.
Misschien dat het toch gaat lukken om de resultaten uit 1972 te reproduceren! En dat dan niet alleen: misschien kunnen we de diverse parameters in het model zodanig aanpassen, dat we weten hoe we de wereld de juiste kant op kunnen sturen 😉
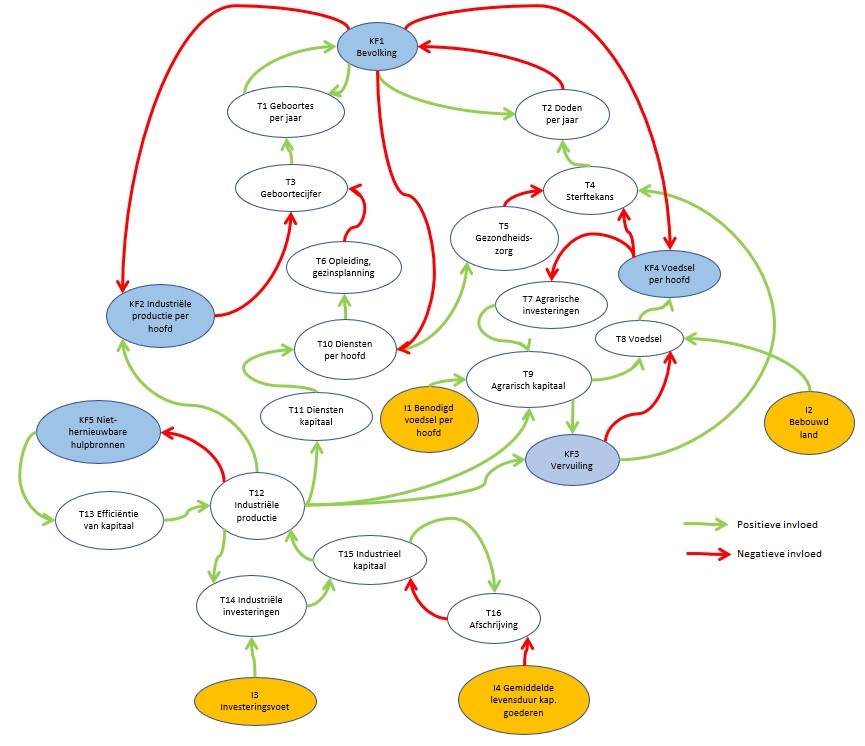
Op het tabblad SystemDynamics van het Voorbeeldbestand ziet u een aangepaste vorm van dit vereenvoudigde model:
Bovenstaand model is in Excel gemaakt met 2 soorten vormen: Ovalen en Gekromde pijlen.
Kies in de menutab Invoegen in het blok Illustraties de optie Vormen.
Selecteer de gewenste vorm en ’teken’ met de muis ongeveer op de plaats waar deze moet komen.
Pas in de menutab Hulpmiddelen voor tekenen de Opmaak aan.
De ovalen zijn gemakkelijk groter en kleiner te maken door middel van de rondjes aan de zijkanten. Bovenin zit een greep waarmee de vorm gedraaid kan worden.
De plaats en de vorm van de pijlen kunnen via de 3 bolletjes aangepast worden. Zorg wel dat de uiteinden van de pijl precies op één van de 8 rondjes van een ovaal terecht komen (het resultaat is dan een dicht zwart bolletje). Wanneer je achteraf een vorm verschuift zal de pijl meebewegen.
Je kunt een tekst in een ovaal plaatsen door daarin te dubbel-klikken en dan de tekst te tikken. Om de consistentie te bewaken hebben we alle codes en namen in een apart tabblad Beschr vastgelegd. Door nu eenmaal in/op een ovaal te klikken kan in de formulebalk een verwijzing naar een cel in dit tabblad gemaakt worden. De cellen in kolom D worden gebruikt in het model; afhankelijk van de grootte van de tekst plaatsen we tussen de Code en de Naam een spatie of een harde return (druk tussen de aanhalingstekens op Alt-Enter). Alle cellen in kolom D hebben een overeenkomende naam gekregen (bijvoorbeeld cel D4 heeft de naam KF1_; de underscore is nodig omdat Excel anders denkt dat we een verwijzing naar de cel in kolom KF en rij 1 bedoelen).
NB heb je een paar vormen (inclusief opmaak) die voldoen, dan kun je die natuurlijk ook kopiëren. De tekst (en misschien de grootte) aanpassen en je bent klaar.
Variabelen
We onderkennen in het model 3 soorten variabelen: de Inputs, de Kritische Factoren en de Tussen-variabelen. De Input-variabelen worden niet beïnvloed door de omgeving, maar kunnen wel in de loop van de jaren variëren. De KF’s zijn die 5 variabelen die in alle grafieken van het rapport terugkomen. Alle overige hebben de naam Tussen-variabelen gekregen.
Verbanden tussen variabelen
De pijlen in het model geven het verband tussen de diverse variabelen aan. De richting en kleur laten de soort beïnvloeding zien.
1. Lineair of absoluut verband
Tussen sommige variabelen zit een lineair/absoluut verband: variabelen worden bij elkaar opgeteld of op elkaar gedeeld om de waarde van een andere variabele te berekenen.
Bijvoorbeeld, voor de bevolkingsomvang gebruiken we de volgende formule: KF1t=KF1t-1 + T1t -T2t De Bevolkingsgrootte KF1 in jaar t is de grootte in jaar t-1plus de Geboortes T1 in jaar tminus de Sterftes T2 in jaar t. In het model gaat er een groene pijl van T1 naar KF1, een rode van T2 naar KF1.
Een ander absoluut verband zien we bij KF4: KF4t=T8t/KF1t-1. Het Voedsel per hoofd KF4 in jaar t is gelijk aan de Hoeveelheid voedsel T8 in jaar t gedeeld door de Bevolkingsgrootte KF1 in jaar t-1. Hoe groter T8 hoe groter KF4 (dus een groene pijl in het model), hoe groter KF1 hoe kleiner KF4 (een rode pijl).
NB we kiezen er voor om te delen door de bevolkingsgrootte in het jaar t-1, omdat we anders het risico lopen op een kringverwijzing: KF4 heeft invloed op de sterftekans T4 en die bepaalt weer de bevolkingsgrootte.
2. Relatief verband
Maar de meeste pijlen in het model vertegenwoordigen een ingewikkelder verband tussen de variabelen. We kunnen bijvoorbeeld niet zeggen dat we de hoeveelheid gezondheidszorg ergens van af trekken om tot een sterftekans te komen.
Maar het is wel aannemelijk dat als de gezondheidszorg van jaar op jaar toeneemt dat dan de sterftekans afneemt (los van andere variabelen). In formulevorm: ofwel
NB1 Hoe sterk de invloed van de gezondheidszorg op de sterftekans is, wordt door α bepaald.
NB2 hadden we te maken met een positieve invloed (een groene pijl) dan hadden we de teller en noemer bij T5 omgewisseld.
LET OP We zullen hierna zien dat deze vorm meestal nog te eenvoudig is om het verband tussen variabelen goed te modelleren.
Zoals het er nu uitziet kunnen we het model op basis van deze 2 soorten verbanden gaan beschrijven. In een volgend artikel zal kolom F in het tabblad Beschr van het Voorbeeldbestand gevuld worden met alle gebruikte rekenregels.
Exponentiële groei
Eén van de belangrijkste oorzaken voor de schokkende resultaten van de MIT-studie is gelegen in het feit dat in onze wereld (in ieder geval in het gehanteerde wereld-model) diverse variabelen de neiging hebben tot een exponentiële groei. De belangrijkste daarvan is de bevolking. Hoe dat komt zullen we hierna bekijken.
Waarschijnlijk de bekendste vorm van exponentiële groei heeft te maken met onze financiën.
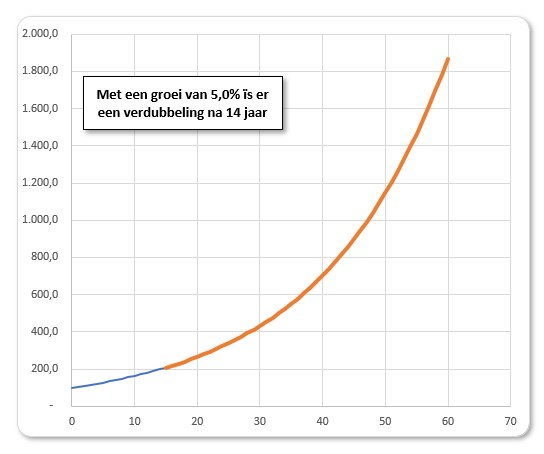
Stel we beginnen met € 100; wanneer we jaarlijks 5% rente krijgen (dat was ooit!) dan hoeven we niet 20 jaar te wachten tot het bedrag verdubbeld is, maar slechts 14 jaar. Dit door het effect van rente op rente. Wacht je dan nog eens 14 jaar dan heb je al 4 keer zoveel.
Op het tabblad ExpGroei van het Voorbeeldbestand kun je met het percentage ‘spelen’ om te zien wat het effect daarvan is. De bijbehorende grafiek past zich automatisch aan.
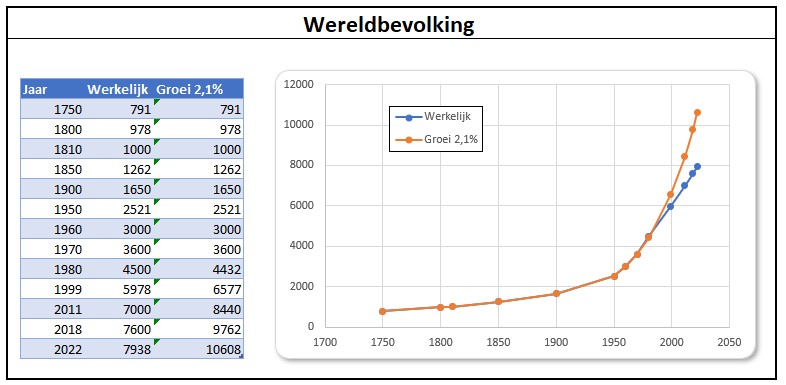
In 1970 was de groeivoet van de wereldbevolking 2,1%. Dit zou een verdubbeling betekenen na 33 jaar. In de grafiek op het tabblad ExpGroei staan de werkelijke groei en de groei met 2,1% vanaf 1970 naast elkaar. Daar valt uit af te leiden dat de groeivoet is gedaald in de loop van de tijd. De consequentie daarvan is dat de verdubbeling niet heeft plaats gevonden in 2003 maar ‘pas’ in 2013.
Bebouwbare grond
Eén van de vele consequenties van de exponentiële groei van de bevolking zien we terug bij de verwachting van de beschikbaarheid van voldoende landbouwgrond.
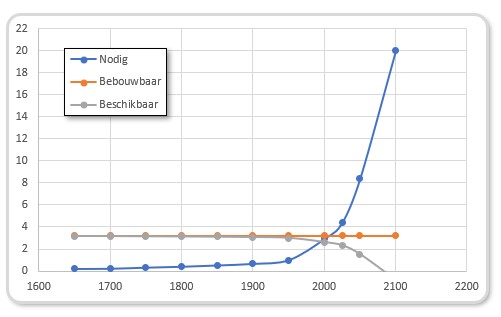
Volgens de Club van Rome was er in 1970 3,2 miljard ha grond beschikbaar voor landbouw. De verwachting was ook dat dat in de toekomst niet significant zou toenemen; dat zou economisch niet rendabel zijn. Op dat moment was er wereldwijd per persoon 0,4 ha nodig om voldoende voedsel te kunnen verbouwen (ter illustratie: in de US werd er toen 0,9 ha pp gebruikt). In het rapport is er ook rekening mee gehouden dat er per persoon 0,08 ha van de beschikbare bouwgrond nodig was voor bewoning en andere infrastructuur.
In het tabblad Bebouwbaar van het Voorbeeldbestand is in de grafiek te zien dat er lang (ruim) voldoende grond was om voedsel te verbouwen. Maar door de exponentiële groei van de bevolking stijgt de benodigde hoeveelheid grond na 1970 snel, terwijl de beschikbare hoeveelheid vanaf dat moment versneld gaat afnemen. De 2 lijnen snijden elkaar ongeveer in het jaar 2000.
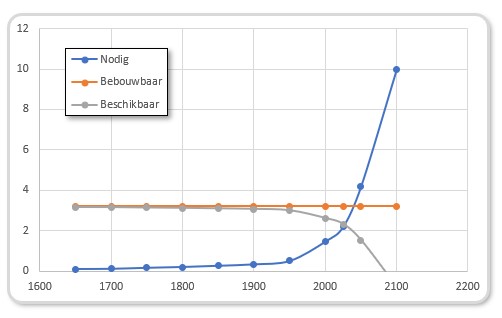
Gelukkig is die ‘voorspelling’ niet bewaarheid. Waarschijnlijk door een efficiënter gebruik van de grond en de lagere groei van de bevolking. In het tabblad Bebouwbaar kun je de productiviteit aanpassen. Hiernaast staat de grafiek bij een productiviteitsfactor van 2; ofwel er is maar 0,2 ha pp nodig. De 2 lijnen snijden elkaar nu pas in het jaar 2025.
Het mag duidelijk zijn dat een verdere verhoging van de productiviteit en/of verlaging van de groeivoet van de bevolking slechts uitstel betekent tot er niet voldoende landbouwgrond meer is. Gemiddeld over de wereld gaat het nu nog goed, maar mensen in Afrika kijken daar waarschijnlijk al anders tegen aan. Ook de oorlog in Oekraïne laat ons zien, dat een (relatief kleine) verstoring van de normale wereldorde een groot effect op onze voedselvoorziening tot gevolg heeft.
Bevolkingsgroei
In het model, dat we hier hanteren, wordt de grootte van de bevolking alleen bepaald door het aantal geboortes (T1) en doden (T2) per jaar. Zoals hiernaast te zien is bepaalt de grootte van de bevolking (KF1) echter ook weer de aantallen van T1 en T2. Dergelijke terugkoppelingen zien we meer terug in het model en deze zorgen vaak voor het exponentiele karakter van groei.
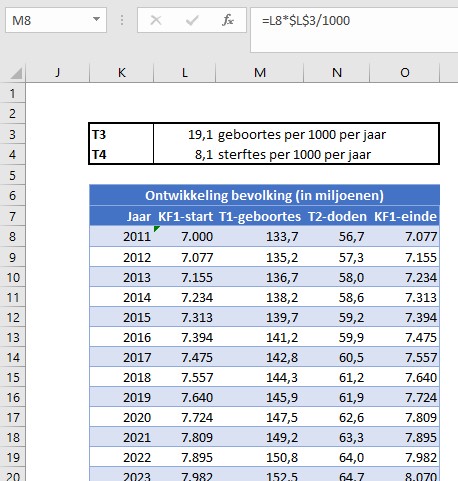
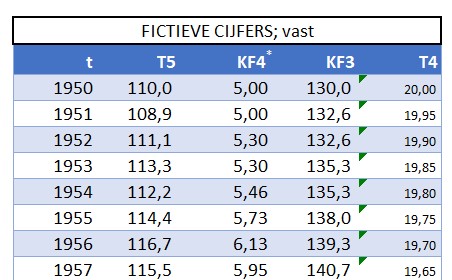
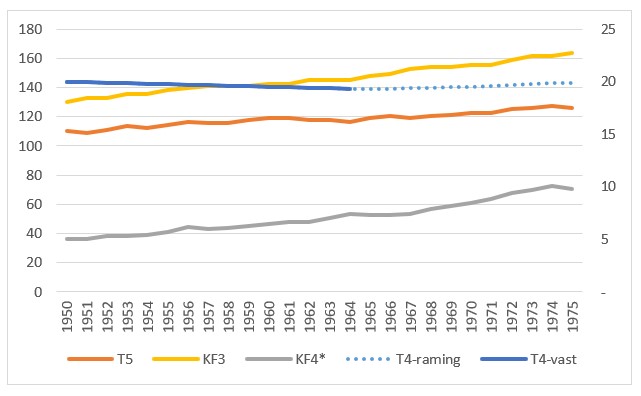
In het tabblad TerugKoppeling van het Voorbeeldbestand is dit te zien aan de hand van fictieve cijfers.
Begin 2011 kende de wereld ongeveer 7 miljard inwoners. Het aantal geboortes per 1000 personen per jaar (Geboortecijfer T3) was toen ongeveer 19,1, terwijl het aantal doden circa 8,1 per 1000 was (Sterftekans T4); de groeivoet van de bevolking per jaar was dus ongeveer 11 per 1000 ofwel 1,1%. Onder de aanname dat T3 en T4 niet veranderen kunnen we gemakkelijk het verloop van de bevolking over de jaren berekenen.
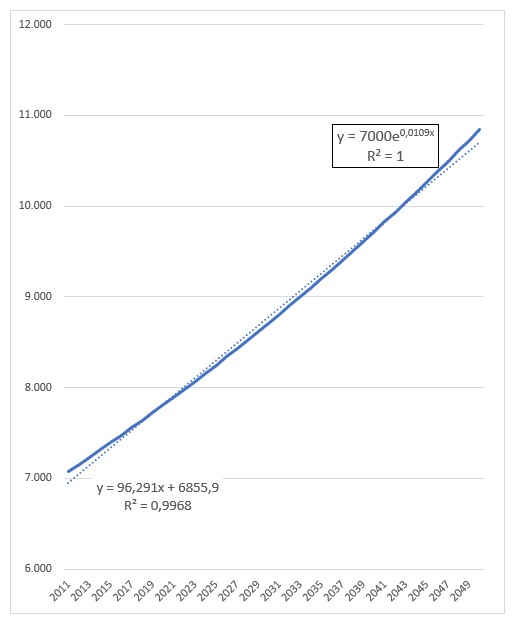
Het verloop is voor 40 jaren berekend en ook in een grafiek uitgezet. We hebben Excel 2 trendlijnen laten bepalen: een lineaire en een exponentiële. De lineaire voldoet met een R2 van 0,9968 (zie het artikel Trend-analyse) prima op het getekende stuk, maar wel is te zien dat als we deze trend zouden gebruiken om te voorspellen dat we al snel uit de pas zouden lopen. De andere trendlijn heeft een R2 van 1 en sluit dus exact aan bij de brongegevens (de trendlijn valt samen met de grafiek zelf). De bevolkingsgroei is dus exponentieel. Op het tabblad ExpGroei kunnen we zien dat een groeivoet van 1,1% betekent dat de bevolking iedere 60 jaar zal verdubbelen.
Vingeroefening 1
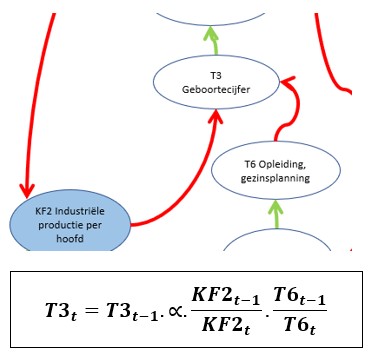
We gaan als eerste eens kijken hoe we de bepaling van het Geboortecijfer T3 kunnen modelleren (zie het tabblad GebCijfer in het Voorbeeldbestand). Zoals te zien is in het schema wordt T3 beïnvloed door de variabelen KF2 (Industriële productie per hoofd) en T6 (opleiding, gezinsplanning). Bij allebei staat een rode pijl. Dat betekent dat een grotere waarde voor KF2 en/of T6 er voor zorgt dat T3 kleiner wordt (in het Club-rapport wordt de achtergrond hiervan kort uitgelegd).
We hebben hier te maken met een relatief verband; hierboven staat de daarbij behorende formule. Maar daar zitten wel wat haken en ogen aan:
de formule bevat één α, waarmee we de gevoeligheid van T3 voor veranderingen in KF2 en T6 kunnen regelen. Maar de gevoeligheid per variabele kan verschillend zijn; dat zouden we zichtbaar willen hebben.
als het gemiddeld opleidingsniveau dit jaar is gestegen ten opzichte van vorig jaar, zal dat niet direct al dit jaar een verandering in T3 geven; daar zit natuurlijk een vertraging in.
een eenmalige grote wijziging in bijvoorbeeld KF2 hoeft niet ook een dergelijk effect te hebben op T3. Het is beter als we een langere periode dan 1 jaar hanteren om de gemiddelde relatieve wijziging te bepalen.
Wanneer we met deze 3 punten rekening houden wordt de formule ‘iets’ ingewikkelder:
iedere variabele heeft zijn eigen gevoeligheidsfactor GF. Omdat er in het model straks veel van dit soort factoren zijn, geven we iedere factor een aanduiding mee op welk verband deze betrekking heeft. Bijvoorbeeld GFKF2,T3 is de gevoeligheid van het verband tussen KF2 en T3. Om decimalen bij de invoer te vermijden schalen we de GF’s tussen 0 en 100. NB als het resultaat van een verband heel sterk wordt beïnvloed door de bron-variabele kan de GF ook groter dan 100 zijn.
de vertraging in het effect wordt door de V-variabelen in de formule bepaald
en de periode door de P’s. NB we bepalen op bovenstaande manier de gemiddelde wijziging tussen het begin en einde van de periode. Voorlopig lijkt dit een goede oplossing, maar misschien blijkt het straks nodig om een gemiddelde over alle wijzigingen in de periode te nemen. Of als het verloop in de periode sterk exponentieel is een nog wat ingewikkelder methode.
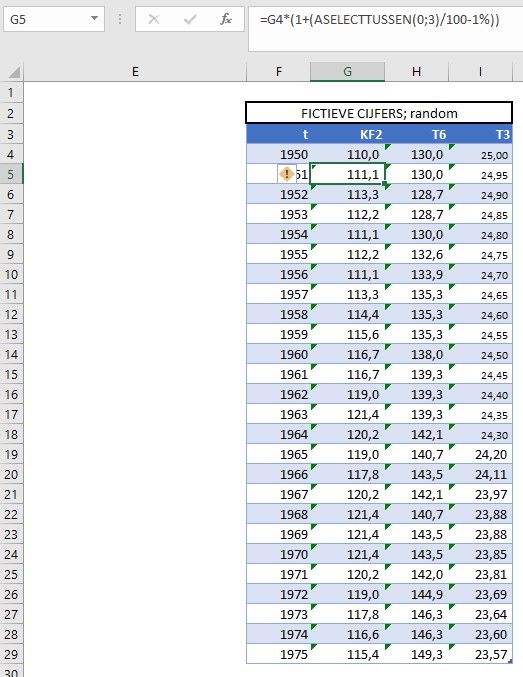
Om wat te kunnen experimenteren staat op het tabblad GebCijfer een tabel met fictieve cijfers over de jaren 1950-1975. De cijfers over 1950 zijn ‘hard’. Met de formule =G4*(1+(ASELECTTUSSEN(0;3)/100-1%)) in cel G5 zorgen we dat KF21951met een waarde tussen -1% en +2% wijzigt ten opzichte van 1950. Op dezelfde manier worden alle cellen in de kolommen G en H met willekeurige waarden gevuld. De waardes voor T3 zijn voor de jaren tot en met 1964 ‘hard’ ingevuld. De niet-harde cellen worden telkens opnieuw berekend wanneer op F9 wordt gedrukt.
In cel I19 staat het eerste resultaat van de berekening volgens bovenstaande systematiek:
de inhoud van cel I18 is de T3 van het vorige jaar
C41 is de waarde van GFKF2,T3
C39 is de VKF2,T3
en C40 is de PKF2,T3
De functie Verschuiving selecteert op basis van (in dit geval) 3 parameters een cel:
de eerste parameter is de start-positie van de selectie; hier de cel in de kolom met de naam T6, die in dezelfde regel staat als de formule ([T6] is de hele tabel-kolom, [@T6] alleen de cel in dezelfde regel).
de tweede is het aantal rijen naar beneden of naar boven voor de daadwerkelijke selectie
en de derde geeft aan of de selectie naar links of rechts ten opzichte van de start-positie moet plaats vinden
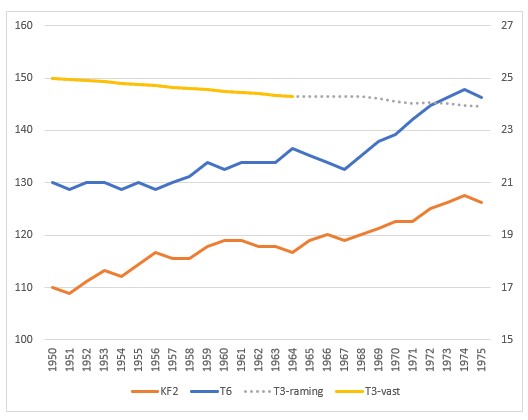
Op het tabblad GebCijfer staat naast de tabel met random-waarden ook een tabel waarin alle waarden in de kolommen KF2 en T6 vast zijn. Op deze manier kun je beter zien wat de consequenties van aanpassingen van de GF-, V– en P-parameters zijn voor het resultaat. De grafieken laten het effect goed zien. Het beoordelen van het resultaat voor wijzigingen in alleen KF2 of T6 kan eenvoudig door de andere GF op 0 in te stellen.
Vingeroefening 2
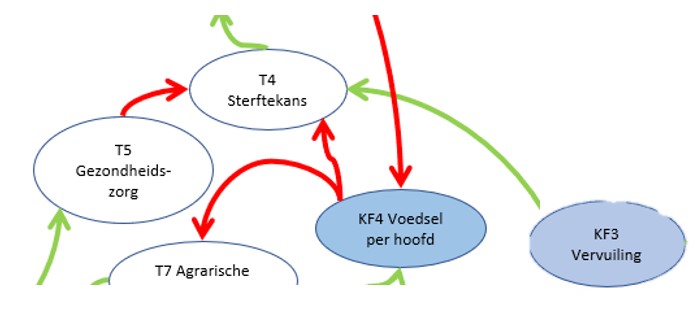
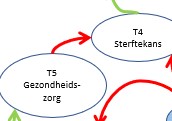
Het tabblad SterfteKans van het Voorbeeldbestand bevat een ander gedeelte van het vereenvoudigde model. We zien hier dat de Sterftekans T4 door 3 variabelen wordt beïnvloed: T5 Gezondheidszorg, KF4 Voedsel per hoofd en KF3 Vervuiling.
We zien 2 rode en 1 groene pijl: als T5 en/of KF4 stijgen zal de sterftekans dalen, maar wanneer de vervuiling toeneemt, neemt ook de T4 toe.
De verbanden tussen de variabelen T5-T4 en KF3-T4 kunnen we modelleren als in de vorige vingeroefening. De relatie tussen KF4 en T4 is ingewikkelder. Wanneer de hoeveelheid voedsel per hoofd blijft stijgen zal dat geen verdere daling van de sterftekans met zich meebrengen (misschien zelfs integendeel).
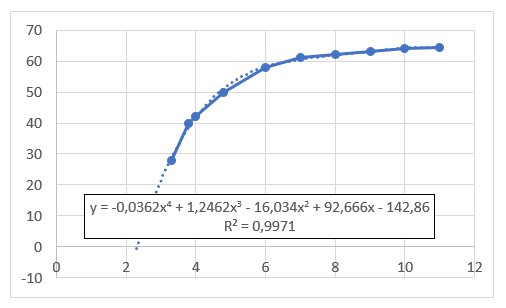
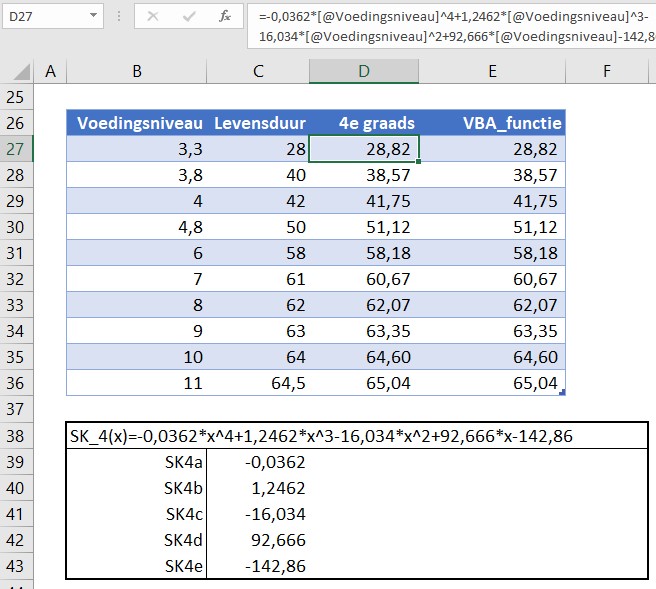
In het Club-rapport is wel een verband gevonden tussen het voedingsniveau (uitgedrukt in groente calorie-equivalenten) en de gemiddelde verwachte levensduur (situatie 1953). Een trendanalyse laat zien, dat dit verband zich goed laat benaderen door een 4e graadsfunctie (tenminste op het relevante stuk met een voedingsniveau tussen 3 en 12). Deze functie zullen we hierna SK_4 noemen.
De formule (zie het tabblad StefteKans) wordt er niet simpeler op! In het tweede blok gebruiken we dus niet de verhouding tussen twee waardes van KF4, maar de verhouding tussen twee uitkomsten van SK_4(KF4*). NB we moeten straks bij de implementatie van het model de waardes van KF4 schalen naar een waarde tussen 3 en 12.
In een tabel op het tabblad SterfteKans hebben we de gegevens uit het Club-rapport overgenomen. In kolom D staat de berekening volgens de 4e graadsfunctie; de verschillen zijn marginaal. Onder de tabel zijn de 5 benodigde parameters voor de functie opgenomen; de cellen hebben overeenstemmende namen gekregen.
Deze namen gebruiken we in de eigen functie SK_4; deze functie zullen we straks in de modelberekeningen gebruiken in plaats van formules met cel-verwijzingen. NB1 voor uitleg over eigen functies, zie het betreffende artikel. NB2 de functie bevat ook een underscore, omdat Excel anders denkt dat het een verwijzing is naar de cel in kolom SK en rij 4.
Ook nu hebben we een overzicht gemaakt met fictieve gegevens. Door met de diverse parameters te spelen krijg je gevoel voor de samenhang tussen de diverse variabelen. De bijbehorende grafiek ondersteunt daarbij.
Het volgende artikel van G-Info zal gewijd zijn aan de implementatie van het vereenvoudigde model. Daar liggen wel wat uitdagingen; technisch maar zeker ook bij het vullen van de diverse parameters. Er zullen heel wat aannames gedaan moeten worden. En of de resultaten van het model dan lijken op de uitkomsten van de Club van Rome? We zullen het zien.
In andere artikelen op deze site is al regelmatig gebruik gemaakt van Gegevensvalidatie. Meestal om er voor te zorgen dat er bij het invoeren van gegevens geen ‘vervuiling’ ontstaat (is de plaatsnaam nu Wanroy of Wanroij, moet de afdeling aangeduid worden met Marketing of met Verkoop, heet die medewerker nu Eric Jansen of Erik Janssen?)
Bij iedere Excel-sheet, waarin gegevens worden ingevoerd, is consistentie van groot belang om te zorgen dat bij analyses of rapporten de juiste zaken bij elkaar worden genomen.
In dit artikel kijken we naar de mogelijkheden van Gegevensvalidatie. Daarbij maken we gebruik van keuzelijsten. Niet echt ingewikkeld, maar het wordt wel leuk als we gebruik gaan maken van ‘meervoudige’ of afhankelijke keuzelijsten.
Gegevensvalidatie
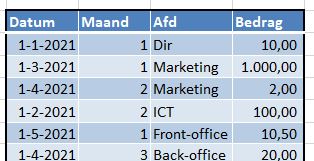
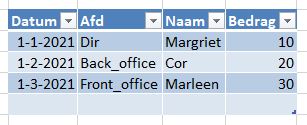
In het Voorbeeldbestand op het tabblad Decl staat een ‘systeem’ waarmee binnen een bedrijf declaraties kunnen worden vastgelegd.
Niet alle invoer is toegestaan; aan alle 4 kolommen worden bepaalde eisen gesteld.
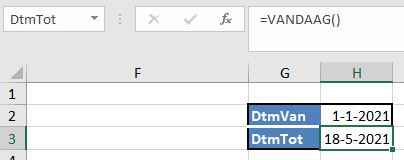
Datum: in de cellen H2 en H3 (met de namen DtmVan en DtmTot) liggen een onder- en bovengrens vast. De ondergrens is een harde datum, de bovengrens is de datum van vandaag.
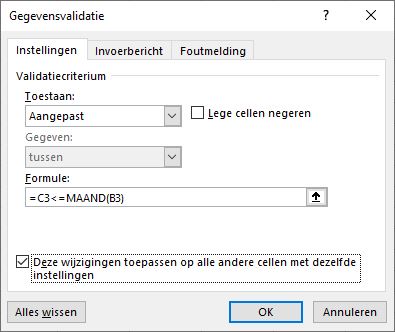
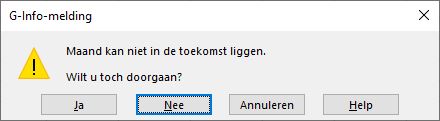
Maand: dit is de maand waarop de declaratie betrekking heeft. Deze moet altijd kleiner of gelijk zijn aan de declaratiedatum
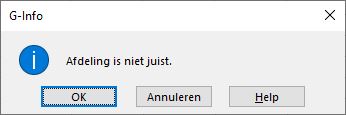
voor Afd zijn maar 6 verschillende namen toegestaan
het Bedrag moet altijd groter zijn dan 0 en kleiner dan 1000
Datum
selecteer alle cellen uit de eerste kolom (behalve de kop natuurlijk)
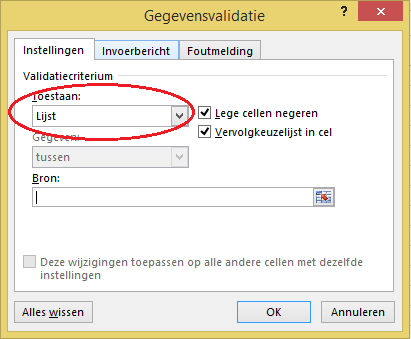
kies in de menutab Gegevens in het blok Hulpmiddelen voor gegevens de optie Gegevensvalidatie
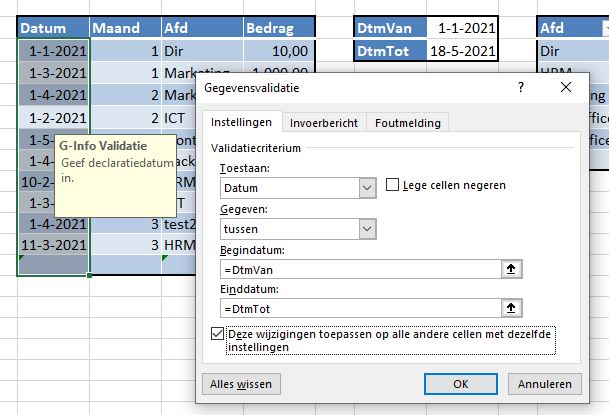
In de tab Instellingen zorgen we dat er alleen een datum is toegestaan. Bij Begindatum vullen we de naam van de betreffende cel in (druk op F3 en kies de naam), bij Einddatum verwijzen we uiteraard naar de betreffende cel. LET OP bij de validatie worden de twee grenzen als toegestaan gerekend NB1 vul je de naam handmatig in, vergeet dan het =-teken niet! NB2 in ons voorbeeld is het onderste vinkje niet nodig (we hebben alle betreffende cellen geselecteerd). Wil je later een wijziging aanbrengen, kies dan één cel en plaats het vinkje. NB3 de datum zal altijd ingevuld moeten worden; verwijder dus het vinkje bij Lege cellen negeren.
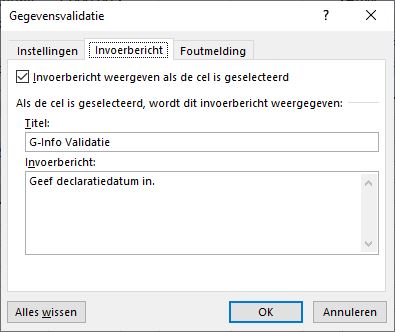
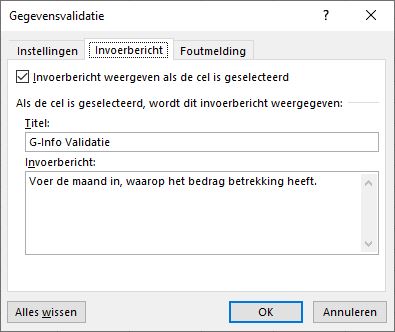
Op de tweede tab kun je een Invoerbericht maken. Deze info wordt zichtbaar wanneer de betreffende cel is geselecteerd.
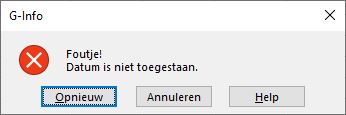
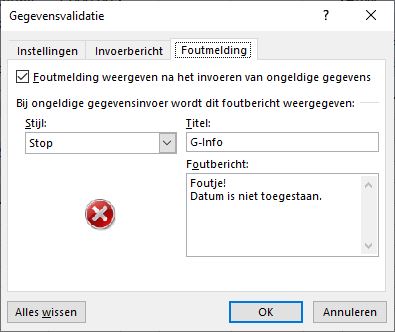
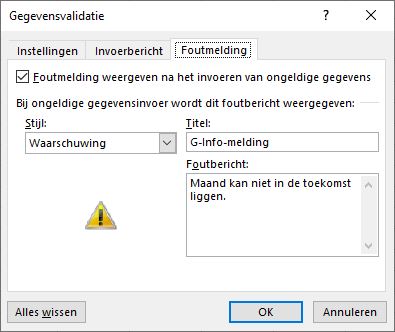
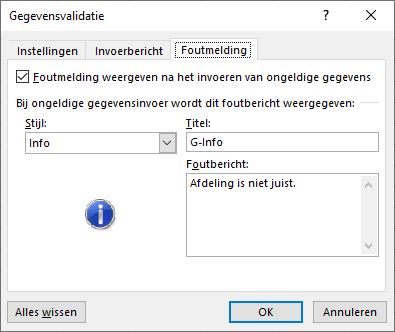
Het is ook mogelijk om een eigen foutmelding te genereren die getoond wordt wanneer de invoer niet overeenkomt met de aangegeven grenzen. Wanneer je als Stijl de optie Stop kiest, zal Excel een juiste invoer afdwingen:
Maand
selecteer alle cellen uit de tweede kolom
kies in de menutab Gegevens in het blok Hulpmiddelen voor gegevens de optie Gegevensvalidatie
Bij Toestaan kiezen we de optie Aangepast. Excel biedt dan de mogelijkheid om een formule in te tikken: =C3<=MAAND(B3) LET OP deze formule gaat er van uit dat een cel in regel 3 actief/geselecteerd is; anders een verwijzing naar de betreffende regel gebruiken.
Ook voor deze kolom is een Invoerbericht aangemaakt.
Een foutmelding geeft de gebruiker houvast wanneer de invoer niet juist is. Hier hebben we bij Stijl gekozen voor Waarschuwing; de gebruiker kan er dan altijd voor kiezen om toch door te gaan:
Afd
selecteer alle cellen uit de derde kolom
kies in de menutab Gegevens in het blok Hulpmiddelen voor gegevens de optie Gegevensvalidatie
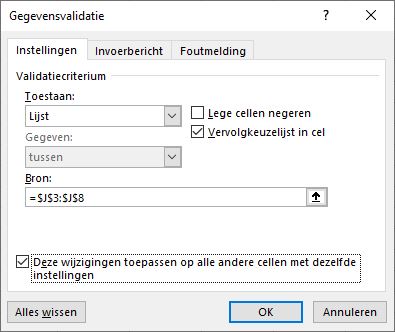
de toegestane afdelingsnamen staan in de cellen J3:J8. NB Zorg dat het vinkje aanstaat bij Vervolgkeuzelijst; de gebruiker kan dan kiezen uit de lijst en hoeft niets handmatig in te tikken.
Op de tab Foutmelding is de Stijl Info gekozen. Dat betekent dat bij een ‘verkeerde’ invoer wel een waarschuwing op het scherm komt: maar door het klikken op OK, wordt de invoer toch geaccepteerd.
Bedrag
selecteer alle cellen uit de vierde kolom
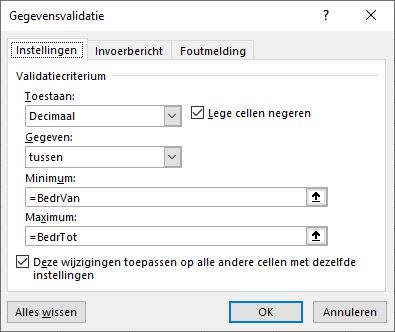
kies in de menutab Gegevens in het blok Hulpmiddelen voor gegevens de optie Gegevensvalidatie
voor het bedrag kiezen we bij Toestaan de optie Decimaal. Als grenzen wordt verwezen naar 2 cellen met de namen BedrVan en BedrTot. LET OP de waardes van de grenzen zijn allebei toegestaan.
Controle
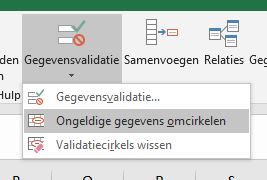
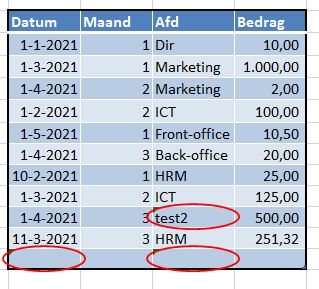
Wil je achteraf weten of er toch nog fouten zitten in de invoer, kies dan in de menutab Gegevens in het blok Hulpmiddelen voor gegevens het vinkje onder de optie Gegevensvalidatie:
Excel omcirkelt alle foute invoer. De naam test2 hoort uiteraard daar niet thuis.
In de lege regel van de tabel tblDeclaraties wordt aangegeven, dat de Datum en de Afd verplicht zijn.
Wil je de ovalen rond de fouten weer verwijderen: kies de derde optie bij Gegevensvalidatie.
Afhankelijke keuzelijst
In het vorige voorbeeld hebben we gebruik gemaakt van Namen om te verwijzen naar bepaalde cellen. Bij de Afd bestaat de toegestane Lijst uit een bereik/range van cellen. Ook die hadden we met behulp van een naam kunnen aangeven.
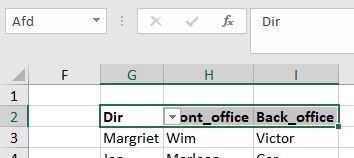
Op het tabblad AfhKeuze van het Voorbeeldbestand is de kolom Afd van een gegevensvalidatie voorzien door als Bron te kiezen voor de naam Afd. Dit is een verwijzing naar het bereik G2:I2
Maar ook de bereiken met persoonsnamen in de kolommen hebben een Naam gekregen; exact gelijk aan de omschrijvingen in regel 2.
NB dat is ook de reden dat er een underscore is gebruikt in plaats van een afbreek-streepje. In een Naam is dat laatste teken niet toegestaan. Maar ook een spatie, een /, een \ enzovoort kun je niet gebruiken in de definitie van een naam.
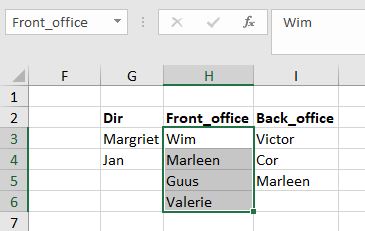
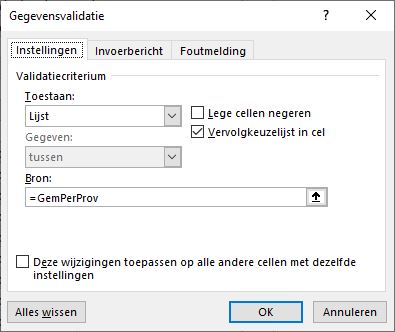
De cellen in de kolom Naam krijgen ook een gegevensvalidatie. Maar het zou natuurlijk mooi zijn als de reeks toegestane namen afhankelijk is van de invoer in de kolom Afd.
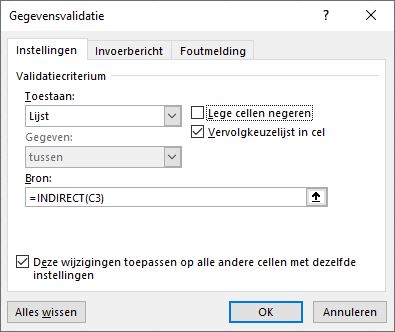
Uitgaande van cel D3 willen we dus alleen maar de namen zien die bij de afdeling Dir voorkomen. Wanneer we bij de Bron van de gegevensvalidatie rechtstreeks zouden verwijzen naar cel C3, dan gaat het niet werken; dan is de naam Dir als enige toegestaan. Gebruiken we echter de functie Indirect dan zijn alle namen uit het bereik Dir toegestaan.
LET OP wanneer achteraf de afdeling wordt gewijzigd dan krijg je niet automatisch een foutmelding dat de persoonsnaam niet is toegestaan. Gebruik dus regelmatig de optie Ongeldige gegevens omcirkelen. Met behulp van een klein beetje VBA is het makkelijk te regelen dat bij een wijziging van afdeling automatisch de persoon gewist wordt.
Afhankelijke keuzelijst 2
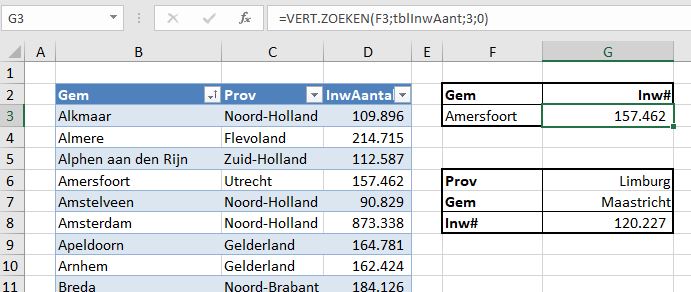
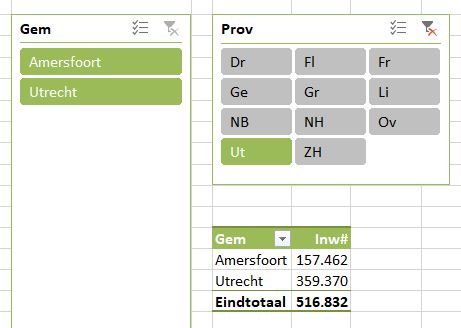
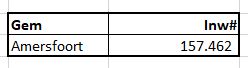
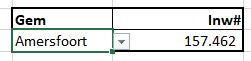
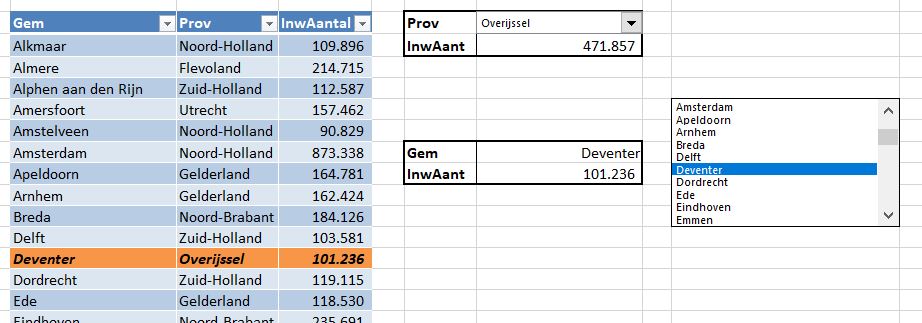
Er zijn (natuurlijk) nog wel meer manieren om een afhankelijke lijst te maken. In het tabblad Afh2 van het Voorbeeldbestand hebben we een meer dynamische methode geïmplementeerd. Daar is een overzicht te vinden van de 50 gemeentes van Nederland met het grootste inwoner-aantal (op 1 jan 2021). In plaats van dat een gebruiker in de lijst moet gaan zoeken (dat is met 50 namen nog wel te doen, maar bij meer dan 300 is het wat lastiger) kan hij een keuze maken in cel F3, waarna in cel G3 het bijbehorende aantal inwoners wordt getoond. De mogelijkheden voor de keuze in cel F3 zijn via Gegevensvalidatie beperkt; de toegestane lijst zijn alle namen uit kolom B.
Maar het is natuurlijk handiger om eerst de provincie te kiezen en afhankelijk daarvan pas de gemeentenaam; het aantal mogelijkheden is dan een stuk beperkter.
De validatie in cel G6 is recht toe recht aan.
Ook die van cel G7 komt bekend voor (zie hiernaast): we beperken de gemeentekeuze tot het bereik GemPerProv.
Maar in dat laatste zit nu net de crux: deze naam verwijst niet naar een bereik van cellen maar is via Formules/Namen beheren ingevoerd: =VERSCHUIVING( tblProvGem[[#Kopteksten];[Gem]]; VERGELIJKEN(ProvZoek;tblProvGem[Prov];0); 0; AANTAL.ALS(tblProvGem[Prov];ProvZoek); 1)
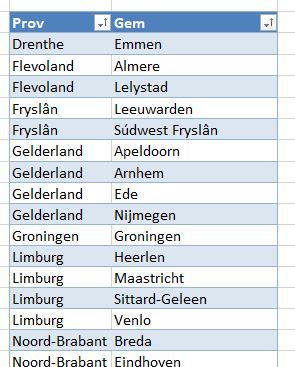
In het tabblad Afh2 van het Voorbeeldbestand staat een Excel-tabel (met de naam tblProvGem) met alle betreffende provincies en bijbehorende gemeentes; gesorteerd eerst op Prov en dan op Gem.
Met behulp van de functie Verschuiving bepalen we de cellen met de gemeentes die bij een bepaalde provincie (in de cel met de naam ProvZoek) horen.
de functie Verschuiving start in de cel met de koptekst van de kolom Gem
maar het resultaat begint net zoveel regels lager als door de functie Vergelijken wordt gegenereerd
en 0 kolommen naar rechts of naar links, dus het resultaat staat in de kolom Gem
het resultaat bestaat uit zoveel regels als dat de gezochte provincie in de kolom Prov voor komt
en de breedte van het resultaat is 1 kolom
NB Wat een gedoe eigenlijk voor iets wat je met een draaitabel met een paar slicers in 1 minuut kunt bouwen. 😉 Zie het tabblad Afh2 in het Voorbeeldbestand.
Maar het gaat om het principe; op een ander moment is deze methode misschien dé oplossing voor uw probleem.
Alternatieve keuzelijsten
cel NIET geselecteerd
Een groot nadeel van gegevensvalidatie is dat je pas weet dat je een keuze kunt maken wanneer de betreffende cel is geselecteerd.
cel WEL gesecteerd
Gelukkig kent Excel nog andersoortige keuzelijsten (zie het tabblad KzLijst van het Voorbeeldbestand). Het kost wel wat meer moeite om dit te implementeren.
Keuzelijst met invoervak
We gaan eerst een Keuzelijst met invoervak maken:
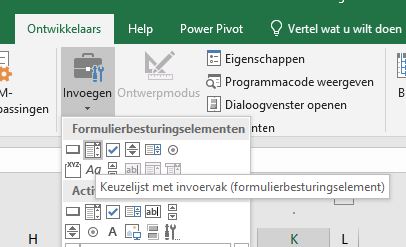
kies in de menutab Ontwikkelaars in het blok Besturingselementen de optie Invoegen NB ziet u de menutab niet: klik met de rechtermuisknop ergens in het lint, kies de optie Lint aanpassen en zet bij Hoofdtabbladen het vinkje aan bij Ontwikkelaars
kies binnen de Formulierbesturingselementen de optie Keuzelijst met invoervak NB binnen de ActiveX-elementen vindt u een vergelijkbare keuzelijst. Deze is nog iets ingewikkelder te implementeren. Daar krijg je dan wel meer flexibiliteit voor terug. Bijvoorbeeld kan de inhoud qua lettertype en -grootte aangepast worden.
’teken met de muis’ waar je het invoervak wilt hebben en hoe groot deze moet zijn
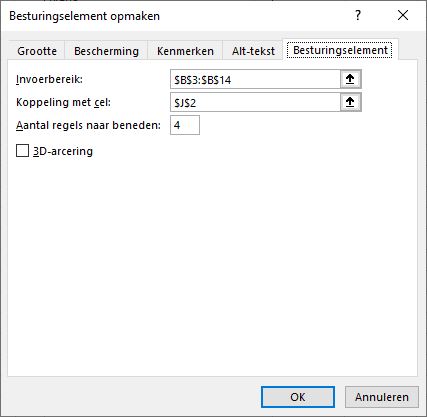
geef bij Invoerbereik de cellen op met de toegestane gegevens (in het voorbeeld de cellen B3:B14)
kies bij Koppeling een lege cel (bijvoorbeeld J2)
geef aan hoeveel regels er zichtbaar moeten worden wanneer het invoervak wordt geactiveerd
Maar we zijn nog niet klaar. Wanneer je een keuze maakt in de lijst wordt het overeenkomende volgnummer in de gekoppelde cel geplaatst (hier dus J2). In het voorbeeld op het tabblad KzLijst hebben we de naam van de gekozen provincie nodig; die halen we in cel K2 op met de formule: =INDEX(tblProv2[Prov];J2)
In cel I3 halen we dan het totaal van het aantal inwoners van de gekozen provincie op: =SOM.ALS(tblProvGem2[Prov];K2;tblProvGem2[InwAantal])
LET OP: het overzicht bevat alleen de 50 grootste steden, dus het totaal is niet echt het totaal van de provincie!
Keuzelijst
Als laatste kijken we nog naar een andere keuzelijst (zie tabblad KzLijst van het Voorbeeldbestand):
kies in de menutab Ontwikkelaars in het blok Besturingselementen de optie Invoegen
kies binnen de Formulierbesturingselementen de optie Keuzelijst
’teken met de muis’ waar je de lijst wilt hebben en hoe groot deze moet zijn
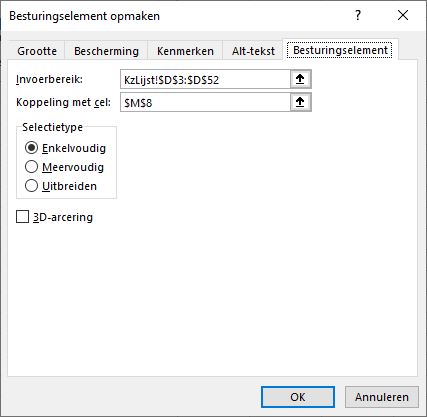
geef bij Invoerbereik de cellen op met de toegestane gegevens (in het voorbeeld de cellen D3:D52)
kies bij Koppeling een lege cel (bijvoorbeeld M8)
zorg dat als Selectietype de optie Enkelvoudig is geselecteerd NB de andere 2 opties zijn alleen interessant als u deze keuzelijst met behulp van VBA wilt gebruiken
NB in het voorbeeld hebben we de gekoppelde cel ‘verstopt’ achter de keuzelijst.
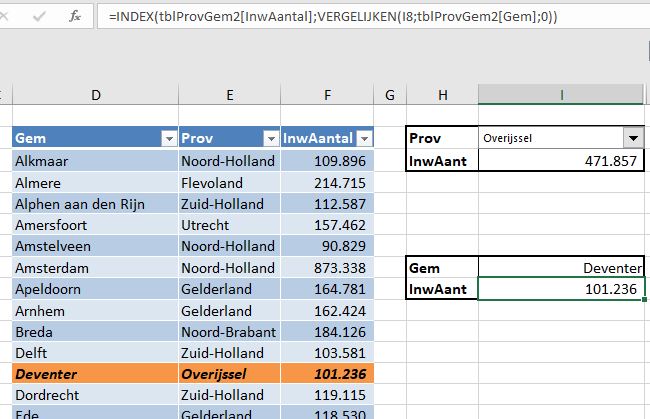
In cel I8 zoeken we de gemeentenaam op die hoort bij het getal in cel M8.
Het ophalen van het inwoneraantal van die gemeente kan het handigst met de avz-methode (zie Zoeken: Index en vergelijken).
Om het resultaat van de keuze ook snel in de tabel te kunnen terugvinden hebben we daar een Voorwaardelijke opmaak aan toegevoegd.
LET OP: na het downloaden de extensie wijzigen in xlsb
Excel wordt steeds vaker gebruikt om het management via dashboards van actuele informatie te voorzien. Maar ook in dit soort rapportages is de ruimte beperkt. Daarnaast is niet iedere manager geïnteresseerd in dezelfde informatie.
Dit soort problemen is handig op te lossen door gebruikers in de digitale rapportages door de overzichten te laten scrollen.
In dit artikel komen enkele methoden aan bod hoe dit te realiseren. En als we toch bezig zijn: met een beetje VBA kunnen we de overzichten ook makkelijk sorteren.
Basis-materiaal
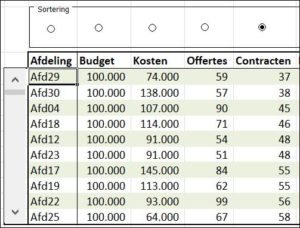
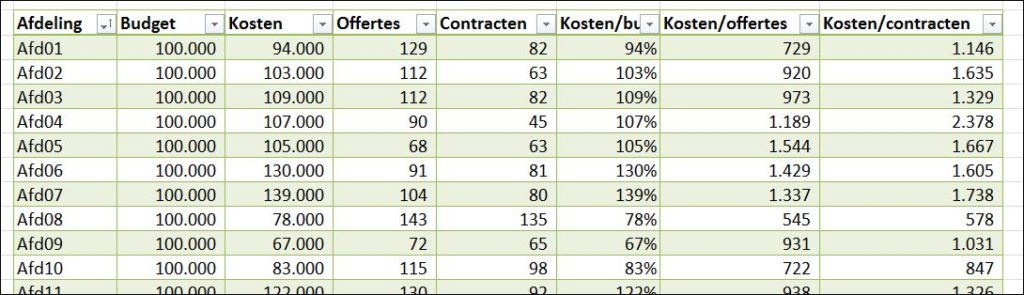
We hebben een overzicht van afdelingen (het tabblad Data in het Voorbeeldbestand bevat 30 regels) met per afdeling het toegekende kosten-budget (altijd 100.000), de werkelijk gemaakte kosten, het aantal uitgebrachte offertes en het gerealiseerde aantal contracten. Daarnaast bevat het overzicht nog enkele KPI’s: kosten/budget, kosten/offertes en kosten/contracten.
De gegevens zijn opgeslagen in de vorm van een Excel-tabel met de naam tblAfd. In cel L2 (met de naam AantAfd) wordt het aantal afdelingen in de tabel geteld: =AANTALARG(tblAfd[Afdeling]) Dit aantal kunnen we later goed gebruiken om bepaalde zaken te automatiseren.
NB de nummering van de afdelingen is zodanig dat er altijd 2 cijfers gebruikt worden; dit om een juiste sortering te krijgen. Anders krijg je Afd1, Afd10, Afd11, … , Afd2, Afd20 etc.
Overzicht 1
Wanneer nou blijkt, dat we in een bepaalde rapportage slechts ruimte voor 10 regels hebben; welke afdelingen (van de 30) moeten we dan laten zien? Dat hangt natuurlijk af van de wensen van de ontvangers en die kunnen wel eens tegenstrijdig zijn. Daarom gaan we nu het overzicht met 10 regels zo aanpassen, dat hierbij gekozen kan worden welke regels zichtbaar zijn.
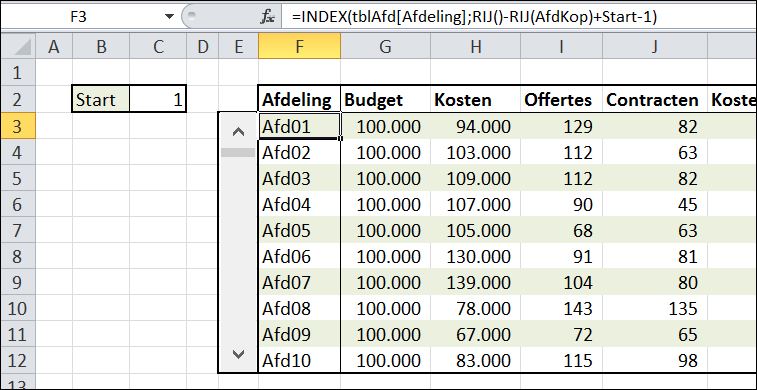
In het tabblad SelIndex van het Voorbeeldbestand geven we in cel C2 (met de naam Start) aan, welke regel van de 30 als bovenste moet worden weergegeven; de volgende 9 worden ook getoond.
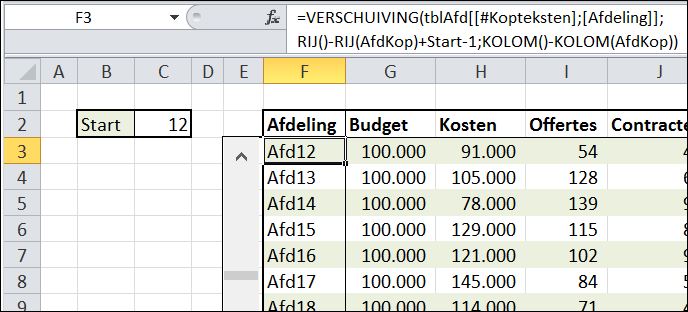
In cel F3 staat de formule: =INDEX(tblAfd[Afdeling];RIJ()-RIJ(AfdKop)+Start-1) Ofwel: zoek met de functie INDEX in de kolom Afdeling van de tabel tblAfd die rij op die overeenkomt met de RIJ() van (in dit geval) cel F3, minus het rij-nummer van de kop van het overzicht plus de waarde van de cel Start.
NB1 cel F2 heeft de naam AfdKop gekregen.
NB2 voor het bepalen van de juiste regel hadden we natuurlijk ook een hulpkolom kunnen gebruiken met daarin de waardes 1 t/m 10. De gebruikte berekening maakt het mogelijk om de hulpkolom weg te laten en is flexibel genoeg om het overzicht eventueel later nog te verplaatsen. Ook kunnen we deze formule zonder verdere aanpassingen naar beneden kopiëren.
NB3 de formule kan ook naar rechts gekopieerd worden; Excel wijzigt de kolom-verwijzing Afdeling automatisch naar Budget etc.
NB4 om de juiste regel te selecteren moeten we de berekening nog corrigeren met -1.
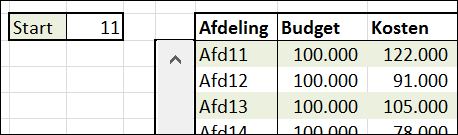
Wanneer nu de waarde in de cel Start wordt gewijzigd zal het overzicht zich automatisch aanpassen.
Dat aanpassen kan natuurlijk nog veel mooier en makkelijker met behulp van een schuifbalk:
kies in de menutab Ontwikkelaars in het blok Besturingselementen de optie Invoegen
in het vervolgmenu kiest u binnen het blok Formulierbesturingselementen de optie Schuifbalk
de cursor wordt dan een kruisje; teken, met de linkerknop ingedrukt, de gewenste vorm van de schuifbalk op de gewenste plaats (dit kan allemaal later nog aangepast worden).
klik met de rechtermuisknop op de nieuwe schuifbalk en kies Besturingselement opmaken
zorg dat een koppeling met cel C2 wordt gemaakt (u kunt hier ook de naam Start gebruiken), de minimumwaarde wordt 1 en het maximum 21.
LET OP kies NIET een ActiveX-besturingselement; deze leveren in de praktijk nogal eens crashes van Excel op.
NB als je de schuifbalk wilt verplaatsen of de grootte corrigeren, klik dan eerst rechts op de schuifbalk.
Overzicht 2
Een andere methode om zo’n overzicht met de juiste gegevens te vullen is door gebruik te maken van de functie VERSCHUIVING.
In het tabblad SelVersch1 van het Voorbeeldbestand ziet u in cel F3 de formule: =VERSCHUIVING(tblAfd[[#Kopteksten];[Afdeling]]; RIJ()-RIJ(AfdKop)+Start-1; KOLOM()-KOLOM(AfdKop)) ofwel: haal de waarde op uit de cel, die gevonden wordt door vanuit de Afdelings-koptekst van de tabel tblAfd een aantal rijen naar beneden te gaan en een aantal kolommen naar rechts.
NB1 de constructie na het eerste (-haakje hoeft u niet zelf in te tikken; klik gewoon op de betreffende cel en Excel vult de formule vanzelf aan.
NB2 de ingegeven minimum- en maximumwaardes voor de schuifbalk zorgen er voor dat het overzicht geen blanco regels zal bevatten. Helaas is dat niet het geval als in de cel Start een te grote of te kleine waarde wordt ingevoerd.
Overzicht 3
De functie VERSCHUIVING kent nog meer parameters/argumenten. Daar hebben we in het overzicht op het tabblad SelVersch2 van het Voorbeeldbestand gebruik van gemaakt. Cel F3 bevat de formule: =VERSCHUIVING(tblAfd[[#Kopteksten];[Afdeling]];Start;0;10;8) Ofwel: selecteer een bereik van cellen, die, gerekend vanaf de koptekst Afdeling, een aantal rijen gelijk aan Start lager begint. Het begin is 0 kolommen verschoven. Het resulterende bereik moet 10 regels hoog en 8 kolommen breed zijn.
LET OP deze formule levert een blok van 80 cellen op. Daarom moet de formule op een speciale manier worden ingevoerd:
selecteer eerst met de muis alle cellen waar het overzicht moet komen (in het voorbeeld de cellen F3 tot en met M12)
voer dan bovenstaande formule in
druk in plaats van op Enter tegelijkertijd op Ctrl-Shift-Enter (de zogenaamde CSE-methode).
Excel plaats dan accolades rond de formule
We willen er ook voor zorgen, dat er geen lege regels komen. De cel Start heeft daartoe een gegevens-validatie gekregen: bij Toestaan is de optie Aangepast ingevuld en bij Formule: =EN(Start>0;Start<=AantAfd-9) Dus de waarde in de cel Start moet aan 2 voorwaarden voldoen: groter dan nul EN kleiner of gelijk aan het aantal regels in de bron (minus 9).
LET OP vergeet het eerste =-teken niet
Maximum in schuifbalk
Maar wat als er nu een afdeling bij komt? De tabel tblAfd wordt automatisch aangepast, de teller van het aantal afdelingen zal ook direct opgehoogd worden, de gegevensvalidatie uit het vorige overzicht zal daarom ook goed werken. Maar … de schuifbalken hebben nog steeds een maximum van 21.
Alleen met behulp van een (kleine) VBA-routine kunnen we het maximum van de schuifbalk automatisch laten meelopen met het aantal regels in de bron-gegevens.
In het overzicht van tabblad SelVersch3 van het Voorbeeldbestand is deze routine geïmplementeerd. Probeer maar eens uit: voeg een regel in het tabblad Data toe en beweeg de schuifbalk op en neer.
Hoe kun je de eigenschappen van de schuifbalk door VBA laten aanpassen?
klik rechts op de schuifbalk
kies de optie Macro toewijzen
als er nog geen macro aan de schuifbalk gekoppeld is dan kiest u Nieuw, anders Bewerken
vul onderstaande programmacode in en sluit de Visual Basic-editor
NB1 afhankelijk van de Excel-versie kan de omschrijving van de subroutine iets anders zijn, bijvoorbeeld Sub Schuifbalk1_BijWijzigen. Laat de naam staan zoals die door Excel is gegenereerd.
NB2 afhankelijk van de situatie kan er ook sprake zijn van Schuifbalk2 etc.
NB3 VBA is altijd Engelstalig. Dus binnen de subroutine is sprake van een ‘shape’ met de naam Scroll Bar 1.
NB4 met de constructie Range(“AantAfd”).Value wordt de waarde uit de cel met de naam AantAfd opgehaald.
‘Automatisch’ sorteren
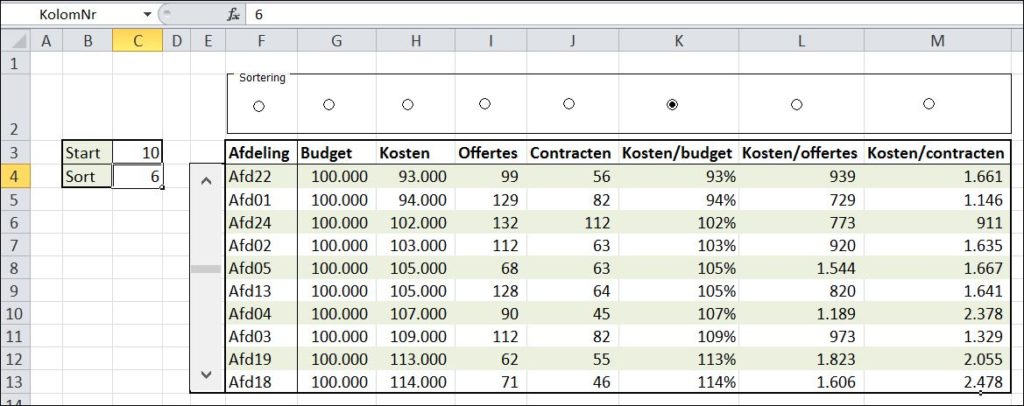
Zoals al eerder aangegeven zal niet ieder ontvanger van de rapportage de focus op dezelfde KPI leggen. We maken de rapportage zodanig dat de gebruiker zelf kan aangeven welke sortering de gegevens moeten hebben.
Klik op één van de keuzerondjes en de gegevens worden op de betreffende kolom gesorteerd (zie het tabblad Sortering in het Voorbeeldbestand).
keuzerondjes worden op een vergelijkbare manier als schuifbalken aan het tabblad toegevoegd.
klik rechts op één van de keuzerondjes en kies de optie Besturingselement opmaken
koppel het besturingselement aan een cel in Excel; in het voorbeeld C4 ofwel KolomNr
klik rechts op het eerste keuzerondje en kies de optie Macro toewijzen en zorg dat de volgende routine gekoppeld wordt:
NB in dit geval heeft het eerste rondje al het volgnummer 2.
De macro-toewijzing moet voor ieder keuzerondje apart worden uitgevoerd.
Bovenstaand subroutine roept een andere routine aan, Sortering. Deze ziet er als volgt uit (de basis is gemaakt door een macro op te nemen terwijl de sortering handmatig wordt uitgevoerd):
als eerste wordt de variabele Kolom gevuld: op basis van de waarde in cel KolomNr wordt één van de kolomkoppen gekozen
met het commando With wordt er voor gezorgd dat alle volgende opdrachten betrekking hebben op een Sort van de tabel (ListObject) tblAfd
vorige sorteringen verwijderen
nieuwe sortering toevoegen
het te sorteren bereik heeft een Header/kop
de sortering is niet gevoelig voor hoofd- en kleine letters
de sortering-orientatie is verticaal (inhoud van een kolom is bepalend)
de PinYin-regel mag ook weggelaten worden; alleen interessant bij Chinese tekens

 Voorbeeldbestand: RapportageStramien.xlsx
Voorbeeldbestand: RapportageStramien.xlsx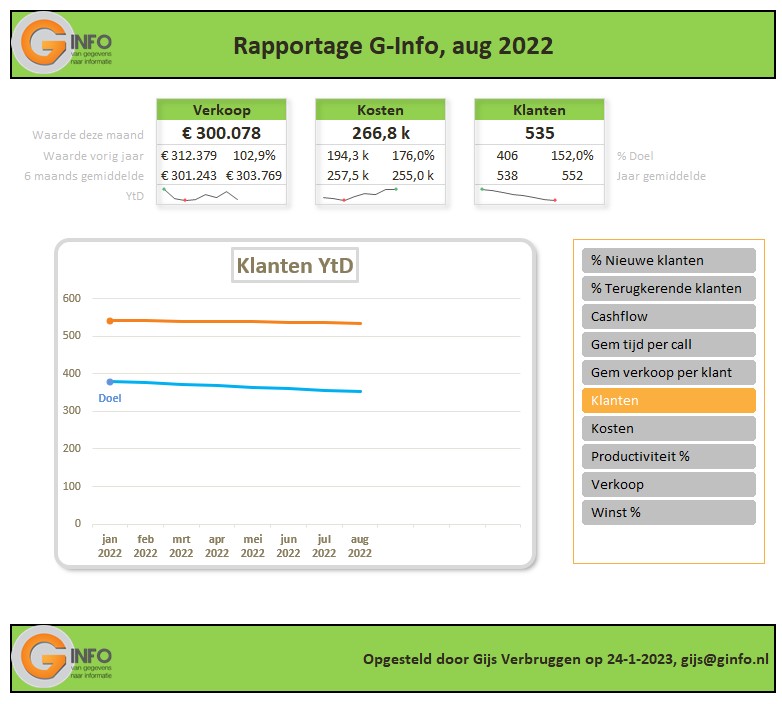





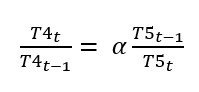 ofwel
ofwel