

Het komt regelmatig voor, dat je een ranking wilt aanbrengen in je gegevens: welke producten verkopen het beste, in welke maanden hebben we het beste resultaat gehaald, bij welke productiestraten is het minste uitval.
In dit artikel zal ik diverse methoden de revue laten passeren, waarmee dat mogelijk is, met hun voor- en nadelen. Het maakt dan niet uit of het over de beste 3 gaat, de hoogste 5 scores of de slechtste 10.
Methode 1: easy does it!
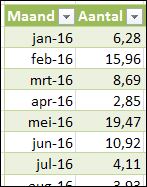 Stel je hebt een overzicht van verkochte aantallen per maand en je wilt weten welke maand het beste is geweest?
Stel je hebt een overzicht van verkochte aantallen per maand en je wilt weten welke maand het beste is geweest?
Sorteer op Aantal en je bent klaar!
Voordeel: heel snel resultaat.
Deze methode kent echter een paar nadelen:
- je past op deze manier de bron-gegevens aan en dat druist in tegen regel 1 van goed Excel-gebruik.
- wijzigen de gegevens of komen er maanden bij, dan moet de sortering opnieuw worden doorgevoerd
- resultaten moeten ‘met de hand’ overgenomen worden in een rapportage
Methode 2: maak een grafiek
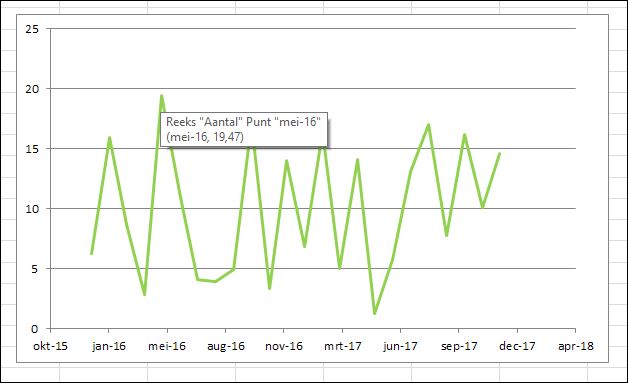 In het tabblad Top5 van het Voorbeeldbestand zijn de gegevens uitgezet in een grafiek; ik heb als type een Spreidingsgrafiek gekozen, zodat de datums op een juiste tijdschaal op de as worden weergegeven en niet ‘gewoon’ achter elkaar (wijzig de laatste datum maar eens in 1-12-18).
In het tabblad Top5 van het Voorbeeldbestand zijn de gegevens uitgezet in een grafiek; ik heb als type een Spreidingsgrafiek gekozen, zodat de datums op een juiste tijdschaal op de as worden weergegeven en niet ‘gewoon’ achter elkaar (wijzig de laatste datum maar eens in 1-12-18).
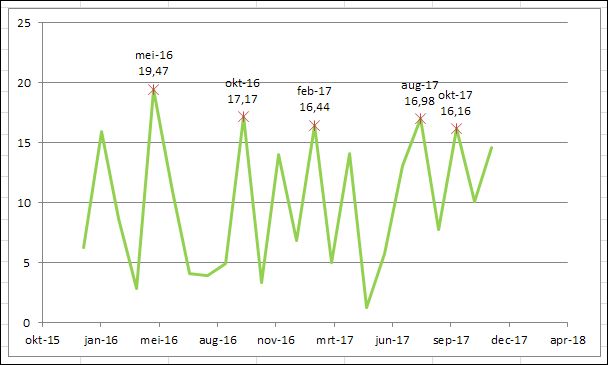
Ga met de muis naar de hoogste waarde en Excel zal de onderliggende gegevens van het punt van de grafiek laten zien.
Voordeel: snel resultaat, waarbij goed is te zien waar de hoogste (of laagste) resultaten zitten, wat (globaal) de verschillen zijn en of er veel vergelijkbare resultaten zijn. In het voorbeeld zijn er zes resultaten boven de 15 en nog drie anderen er vlak bij; of een top-3 (of top-5) hier veel zegt?
Nadeel: resultaten moeten ‘met de hand’ opgezocht en overgenomen worden in een rapportage.
NB wil je kijken wat er met de grafiek gebeurt als je andere brongegevens hebt, kopieer dan de cellen uit kolom D en plak ze ‘hard’ in kolom C (via Plakken speciaal/Waarden).
In de kolom Random worden door Excel telkens nieuwe data gegenereerd mbv de formule: =ASELECTTUSSEN(1;2000)/100 ofwel een willekurig getal tussen 1 en 2000 (inclusief grenzen) en deel dat door 100, zodat een getal tussen 1 en 20 (met maximaal 2 decimalen) ontstaat.
Methode 3: gebruik een Draaitabel
- selecteer een willekeurige cel in de brondata; deze zijn vastgelegd in de vorm van een Excel-tabel met de naam tblData. Hoe dat moet en wat de voordelen zijn: kijk op 10 voordelen van tabellen en Tabellen (deel 2).
- kies in de menutab Invoegen in het blok Tabellen de optie Draaitabel en klik op het tussenscherm op OK.
- sleep in Lijst met draaitabelvelden het veld Maand naar Rijlabels en het veld Aantal naar het Waardegebied
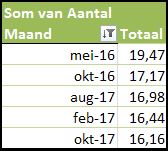 klik rechts op één van de getallen in de tweede kolom en kies de optie Sorteren en dan Sorteren van hoog naar laag
klik rechts op één van de getallen in de tweede kolom en kies de optie Sorteren en dan Sorteren van hoog naar laag- bijna klaar; Excel laat nu nog alle maanden zien, maar we willen alleen maar de beste 5 resultaten: klik rechts op één van de maanden, kies Filteren en dan de optie Top-tien.
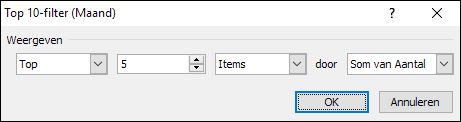 Zorg dat in het tweede veld in plaats van de standaard 10 een 5 komt, de rest is OK.
Zorg dat in het tweede veld in plaats van de standaard 10 een 5 komt, de rest is OK.
Bekijk het resultaat in het tabblad Top5 van het Voorbeeldbestand.
Voordeel: de resultaat-tabel kan zo in een standaard-rapportage worden overgenomen.
Nadeel: wijzigen de gegevens of komen er nieuwe maanden bij? Vergeet niet de draaitabel te Vernieuwen (door ergens in de tabel rechts te klikken).
NB1 doordat de gegevens in een Excel-tabel zijn vastgelegd, ‘weet’ Excel wanneer er nieuwe regels zijn toegevoegd, dus de bron van de draaitabel hoeft niet meer aangepast te worden.
NB2 het Top-10-filter kan ook ingesteld worden door op het blokje achter Maand te klikken. De Top-10 vindt u dan onder Waardefilters.
NB3 wilt u niet de 5 bovenste gegevens maar de onderste, wijzig dan Top in Onder.
Optie 2 van het Top-10-filter
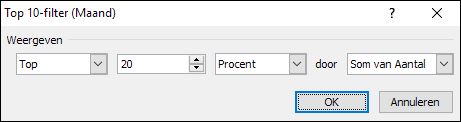
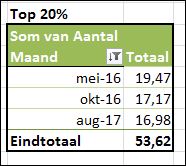 Dit Top-10-filter kent nog 2 andere opties. Wanneer u in plaats van Items kiest voor Procent dan zal Excel die maanden laten zien, die er samen voor zorgen, dat het ingestelde percentage minimaal wordt bereikt.
Dit Top-10-filter kent nog 2 andere opties. Wanneer u in plaats van Items kiest voor Procent dan zal Excel die maanden laten zien, die er samen voor zorgen, dat het ingestelde percentage minimaal wordt bereikt.
20% van 239,72 (het totaal Aantal uit het tabblad Top5 van het Voorbeeldbestand) is 47,944, dus aug-17 is nog nodig om dit Totaal te bereiken.
Optie 3 van het Top-10-filter
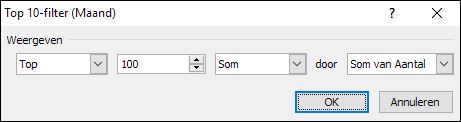
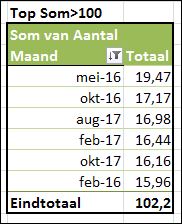 De derde mogelijkheid is om een harde grens meet te geven; in dit voorbeeld willen we die maanden zien die samen minimaal 100 opleveren.
De derde mogelijkheid is om een harde grens meet te geven; in dit voorbeeld willen we die maanden zien die samen minimaal 100 opleveren.
Methode 4: gebruik de functie GROOTSTE
 De functie GROOTSTE kent 2 parameters:
De functie GROOTSTE kent 2 parameters:
* de Matrix (bereik), waarin het grootste getal moet worden gezocht
* K, het volgnummer; wil je de grootste waarde dan is K=1, wil je de één na grootste dan is K=2 etc.
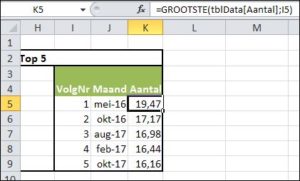
Dus de formule in cel K5
=GROOTSTE(tblData[Aantal];I5)
haalt uit de kolom Aantal van de tabel tblData het grootste getal op (cel I5 is gelijk aan 1).
Deze formule is naar beneden gekopieerd; zie het tabblad Top5 in het Voorbeeldbestand.
Nu moet nog kolom J met de bijbehorende maand gevuld worden. In cel J5 staat daartoe de volgende formule:
=INDEX(tblData[Maand];VERGELIJKEN(K5;tblData[Aantal];0))
De functie Index zoekt in de kolom Maand van de tabel tblData die rij op, die overeenkomt met het resultaat van de functie Vergelijken; deze functie beoordeelt op welke positie de inhoud van cel K5 staat in de kolom Aantal van de tabel tblData. De 0 geeft aan dat er een exacte match moet zijn (zie ook Alternatief voor vert.zoeken en Zoeken: Index en Vergelijken).
Voordelen: de resultaat-tabel kan zo in een standaard-rapportage worden overgenomen en de tabel past zich automatisch aan aan wijzigingen in de brongegevens en hoeft dus niet vernieuwd te worden zoals bij een draaitabel.
Nadelen: ‘ingewikkelde’ formules nodig en methode werkt niet altijd goed als getallen in de kolom Aantal gelijk zijn.
NB1 de resultaten van de GROOTSTE-tabel kunnen toegevoegd worden aan de grafiek.
NB2 wilt u niet de top-gegevens achterhalen maar de onderste, gebruik dan de functie KLEINSTE.
Methode 4: gebruik de functie GROOTSTE (bis)
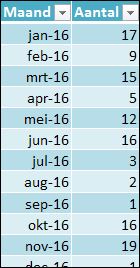 Op het tabblad Top5_2 van het Voorbeeldbestand staat een nieuw databestand, waarin ook dubbele aantallen voorkomen.
Op het tabblad Top5_2 van het Voorbeeldbestand staat een nieuw databestand, waarin ook dubbele aantallen voorkomen.
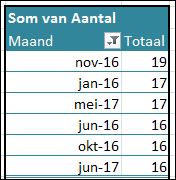 Maken we hierop een draaitabel met een Top-5, dan lost Excel het probleem voor ons simpel op: hij maakt automatisch een Top-6!
Maken we hierop een draaitabel met een Top-5, dan lost Excel het probleem voor ons simpel op: hij maakt automatisch een Top-6!
Er is natuurlijk wel een oplossing om het tweede nadeel van de vorige methode op te vangen.
Het opzoeken van het grootste aantal (en de één na grootste etc) is ook hier niet het probleem (zie kolom J), maar wel het opzoeken van de daarbij behorende maand (het Aantal 16 kan horen bij jun-16, okt-16 en jun-17).
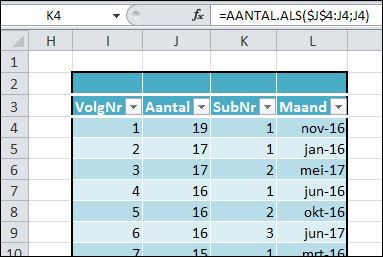 Ieder resultaat van de functie GROOTSTE krijgt in kolom K een SubNr mee. In cel K4 staat daartoe de formule:
Ieder resultaat van de functie GROOTSTE krijgt in kolom K een SubNr mee. In cel K4 staat daartoe de formule:
=AANTAL.ALS($J$4:J4;J4)
Hiermee wordt het aantal keren geturfd, dat de waarde van cel J4 (de laatste parameter) voorkomt in het bereik $J$4:J4. Tsja, dat is natuurlijk altijd 1!
Maar wat gebeurt er als we de formule naar beneden kopiëren? In cel K5 komt dan automatisch =AANTAL.ALS($J$4:J5;J5): er wordt gekeken hoe vaak J5 voorkomt in het bereik van J4 tot en met J5! Op deze manier krijgen dubbelen ieder een eigen volgnummer.
Het opzoeken van de corresponderende maand is een uitdaging. In cel L4 staat de formule:
={INDIRECT(“B”&KLEINSTE(((tblData2[Aantal]=J4)*RIJ(tblData2[Aantal]))+((tblData2[Aantal]<>J4)*10^8);K4))}
OEPS! Met dank aan Chandoo heb ik dit alternatief gevonden. Probeer de formule te begrijpen door in de menutab Formules in het blok Formules controleren de optie Formules evalueren te kiezen:
- Eerst zoeken we alle aantallen, die gelijk zijn aan J4 (tblData2[Aantal]=J4); dit levert een reeks op met Waar en Onwaar
- deze reeks vermenigvuldigen we met de overeenkomende rijnummers (*RIJ(tblData2[Aantal])), waardoor we een reeks overhouden met rijnummers, waarin J4 voorkomt, en nullen
- als J4 NIET in een rij voorkomt, dan tellen we daar een groot getal (1 met 8 nullen) bij op (+((tblData2[Aantal]<>J4)*10^8))
- dan nemen we de kleinste (of één na kleinste etc.; afhankelijk van K4) van die reeks (KLEINSTE)
- als laatste wordt met INDEX de waarde in die rij in kolom B opgehaald.
Komt u er niet uit? Neem contact op met G-Info.
LET OP de formule in L4 is ingevoerd door op Ctrl-Shift-Enter te drukken (CSE-methode); het is een zogenaamde matrix- of array-formule. De formule kan wel gewoon naar beneden gekopieerd worden.
Zie voor meer uitleg over de gehanteerde methode het artikel SOMPRODUCT: meer dan SOM en PRODUCT. Ook de voorbeelden uit de werkmap, die Ton Spies mij toestuurde, kunnen hiervoor gebruikt worden.
Voordelen: de resultaat-tabel kan zo in een standaard-rapportage worden overgenomen en de tabel past zich automatisch aan aan wijzigingen in de brongegevens en hoeft dus niet vernieuwd te worden zoals bij een draaitabel.
Nadeel: zeer ‘interessante’ formules zijn nodig.
 Excel kent 2 functies waarvan het nut niet helemaal duidelijk is: N() en T().
Excel kent 2 functies waarvan het nut niet helemaal duidelijk is: N() en T().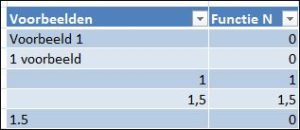 Uit de eerste 2 voorbeelden blijkt, dat de N-functie een combinatie van tekst en cijfers NIET kan omzetten naar een getal.
Uit de eerste 2 voorbeelden blijkt, dat de N-functie een combinatie van tekst en cijfers NIET kan omzetten naar een getal.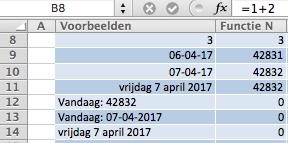 In cel B8 staat een formule, die als resultaat een getal oplevert; de N-functie neem deze waarde over.
In cel B8 staat een formule, die als resultaat een getal oplevert; de N-functie neem deze waarde over.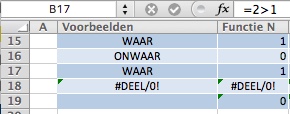 De teksten Waar en Onwaar worden door de N-functie vertaald naar 1, respectievelijk 0. Ook als het het resultaat is van een formule (zie cel B17 met de formule =2>1).
De teksten Waar en Onwaar worden door de N-functie vertaald naar 1, respectievelijk 0. Ook als het het resultaat is van een formule (zie cel B17 met de formule =2>1). De N-functie kan ook goed gebruikt worden ter vervanging van de ALS-functie. Dit levert een iets kortere en beter leesbare formule op.
De N-functie kan ook goed gebruikt worden ter vervanging van de ALS-functie. Dit levert een iets kortere en beter leesbare formule op. selecteer de cellen F2 t/m G4
selecteer de cellen F2 t/m G4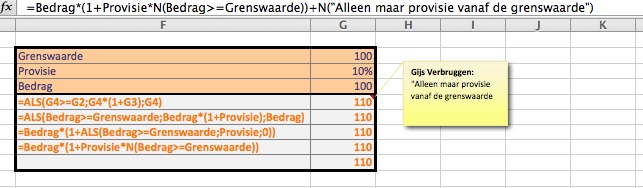 Die documentatie kan vastliggen in Word-files, in een apart tabblad en/of door cellen met formules van opmerkingen te voorzien (zie cel G5 in het tabblad Vb1 van het
Die documentatie kan vastliggen in Word-files, in een apart tabblad en/of door cellen met formules van opmerkingen te voorzien (zie cel G5 in het tabblad Vb1 van het 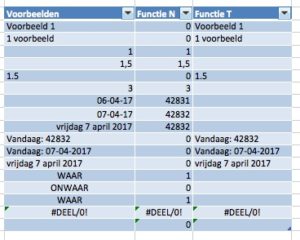 De T-functie zal nu weinig verrassingen meer opleveren: als de parameter een tekst is (of via een formule een tekst bevat) dan zal de T-functie de tekst terugleveren en anders niets (een lege tekst).
De T-functie zal nu weinig verrassingen meer opleveren: als de parameter een tekst is (of via een formule een tekst bevat) dan zal de T-functie de tekst terugleveren en anders niets (een lege tekst).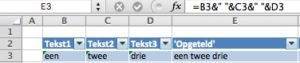 In een bepaalde toepassing wilt u teksten uit verschillende kolommen aan elkaar koppelen. Zoals we gezien hebben kan dat gemakkelijk met behulp van het &-teken. In het tabblad Vb2 van het
In een bepaalde toepassing wilt u teksten uit verschillende kolommen aan elkaar koppelen. Zoals we gezien hebben kan dat gemakkelijk met behulp van het &-teken. In het tabblad Vb2 van het 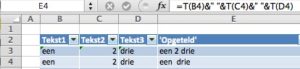 In deze toepassing mogen de cellen echter allen gekoppeld worden als het een tekst bevat; hier komt de T-tunctie om de hoek kijken (zie cel E4).
In deze toepassing mogen de cellen echter allen gekoppeld worden als het een tekst bevat; hier komt de T-tunctie om de hoek kijken (zie cel E4). In het
In het 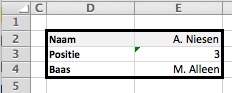 Wanneer we dus A. Niesen zoeken moeten we op regel 7 uitkomen; ofwel in het derde blokje van de medewerker/baas-combinatie.
Wanneer we dus A. Niesen zoeken moeten we op regel 7 uitkomen; ofwel in het derde blokje van de medewerker/baas-combinatie.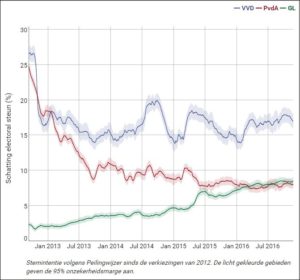 Binnenkort (nou ja, over een paar maanden) hebben we weer verkiezingen. In de aanloop daar naartoe zien we in de media steeds vaker de resultaten van diverse peilingen.
Binnenkort (nou ja, over een paar maanden) hebben we weer verkiezingen. In de aanloop daar naartoe zien we in de media steeds vaker de resultaten van diverse peilingen.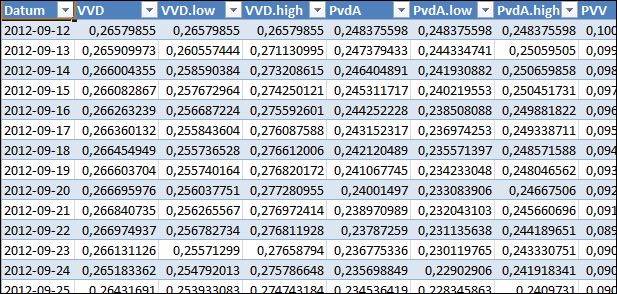
 Hierna gaan we een grafiek maken van de peiling-resultaten. Hierbij kan echter maar één partij tegelijkertijd worden weergegeven. Om de invoer daarvan straks te vergemakkelijken leggen we de keuzemogelijkheden in een aparte tabel vast (zie tabblad Param in het
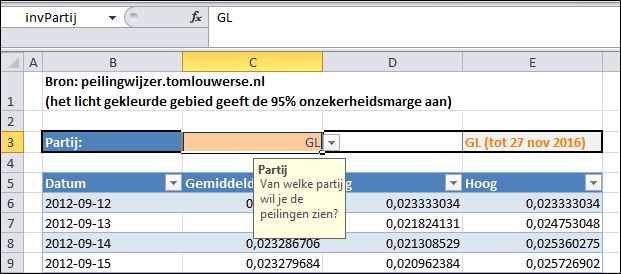
Hierna gaan we een grafiek maken van de peiling-resultaten. Hierbij kan echter maar één partij tegelijkertijd worden weergegeven. Om de invoer daarvan straks te vergemakkelijken leggen we de keuzemogelijkheden in een aparte tabel vast (zie tabblad Param in het  In cel E2 van het tabblad Param uit het
In cel E2 van het tabblad Param uit het 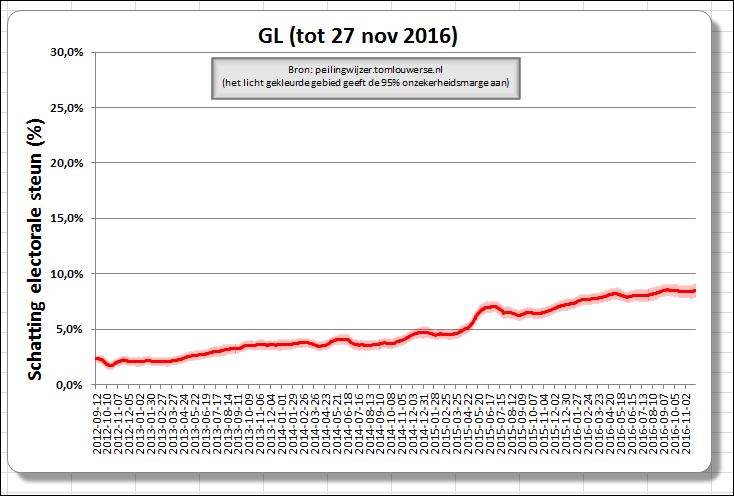
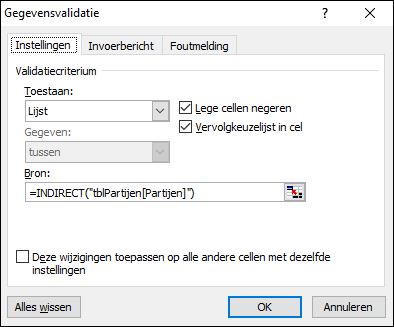 kies in de menutab Gegevens de optie Gegevensvalidatie
kies in de menutab Gegevens de optie Gegevensvalidatie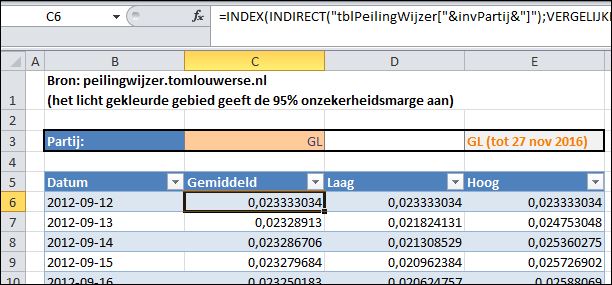 De voorbereidingen zijn klaar, nu nog de gegevens ophalen van de gekozen partij:
De voorbereidingen zijn klaar, nu nog de gegevens ophalen van de gekozen partij: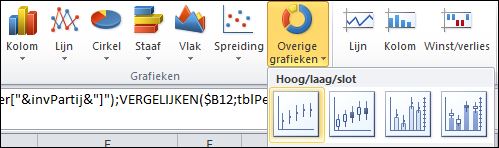 in de menutab Invoegen kiest u in het blok Grafieken de optie Overige grafieken.
in de menutab Invoegen kiest u in het blok Grafieken de optie Overige grafieken.
 Op ieder Excel-forum zie je regelmatig de opmerking, dat het gebruik van de standaard-functie VERT.ZOEKEN (verticaal zoeken) niet flexibel is en foutgevoelig (en dat geldt ook voor de horizontale variant). Meestal wordt er dan als alternatief verwezen naar het gebruik van INDEX, gecombineerd met VERGELIJKEN.
Op ieder Excel-forum zie je regelmatig de opmerking, dat het gebruik van de standaard-functie VERT.ZOEKEN (verticaal zoeken) niet flexibel is en foutgevoelig (en dat geldt ook voor de horizontale variant). Meestal wordt er dan als alternatief verwezen naar het gebruik van INDEX, gecombineerd met VERGELIJKEN.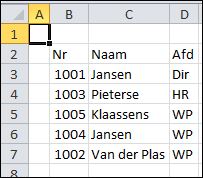 Hiernaast zie je een simpel voorbeeld van een werknemersadministratie: naast een personeelsnummer staat de naam en de afdeling.
Hiernaast zie je een simpel voorbeeld van een werknemersadministratie: naast een personeelsnummer staat de naam en de afdeling. In cel F3 staat het personeelsnummer waarvan we de naam en afdeling willen weten. In G3 staat de formule
In cel F3 staat het personeelsnummer waarvan we de naam en afdeling willen weten. In G3 staat de formule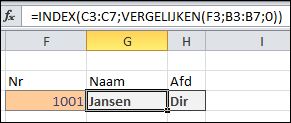 In het tabblad IndVerg van het
In het tabblad IndVerg van het 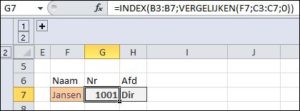 Ook de NB2 kunnen we hiermee omzeilen: in cel G7 zoeken we het nummer op in B3:B7, dat hoort bij de naam in cel F7 door die waarde te vergelijken met de inhoud van C3:C7.
Ook de NB2 kunnen we hiermee omzeilen: in cel G7 zoeken we het nummer op in B3:B7, dat hoort bij de naam in cel F7 door die waarde te vergelijken met de inhoud van C3:C7. Het eerste wat we doen is van het personeelsbestand een tabel maken:
Het eerste wat we doen is van het personeelsbestand een tabel maken: In het
In het  In cel G3 gaan we opnieuw de alternatieve opzoek-formule maken om de naam bij een nummer te vinden:
In cel G3 gaan we opnieuw de alternatieve opzoek-formule maken om de naam bij een nummer te vinden: Kies in Excel de menutab Bestand
Kies in Excel de menutab Bestand Er is al veel over geschreven: Nederland is er niet bij!
Er is al veel over geschreven: Nederland is er niet bij!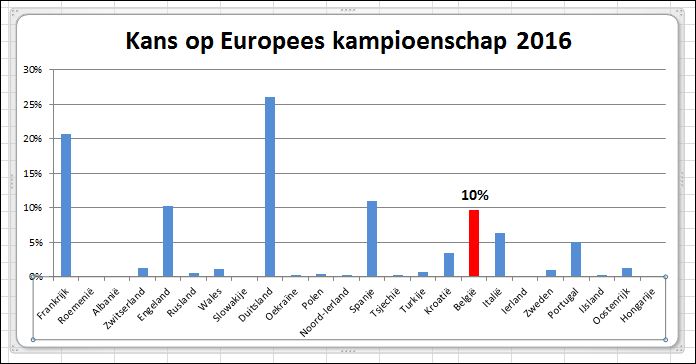 O ja, België heeft volgens dit Excel-model trouwens ongeveer 10% kans om kampioen te worden!
O ja, België heeft volgens dit Excel-model trouwens ongeveer 10% kans om kampioen te worden! Voor de indeling van deze 4 is een ingewikkeld schema bedacht (zie hiernaast; bron is WIKIPEDIA)).
Voor de indeling van deze 4 is een ingewikkeld schema bedacht (zie hiernaast; bron is WIKIPEDIA)).