Binnen ieder bedrijf is het van belang om zoveel mogelijk processen te standaardiseren en vaak ook te automatiseren.
Ook wanneer we Excel als hulpmiddel bij ons werk gebruiken is het belangrijk om zoveel mogelijk handmatige handelingen, die regelmatig terugkomen, te vermijden. Power Query, draaitabellen, en VBA kunnen daarbij een grote rol spelen.
Voor diegene, die vaak verschillende rapportages moeten maken, is een andere invalshoek belangrijk. Ga niet voor iedere nieuwe rapportage weer opnieuw het wiel uitvinden, maar gebruik een flexibel stramien. Hoe dat in zijn werk gaat zullen we in dit artikel aan de hand van een direct inzetbaar Voorbeeldbestand laten zien.
Bedrijf
Het eerste tabblad van het Voorbeeldbestand, Bedrijf, bevat diverse bedrijfsspecifieke gegevens, inclusief een logo.
NB1 wanneer je dit logo vervangt (door er rechts op te klikken) zorg dan dat het nieuwe plaatje een transparante achtergrond heeft.
NB2 diverse cellen in dit tabblad (en ook op andere plaatsen in de werkmap) hebben een naam gekregen, die in de rest van het rapportage-stramien gebruikt worden. Cel C2 bijvoorbeeld heeft de naam BedrNaam.
In cel C8 wordt de meest recente datum uit het Data-bestand (zie hierna) opgehaald met behulp van de functie MAX. De inhoud van cel C9 bepaalt of deze datum als referentie dient voor de rapportage of een andere (cel C10).
NB3 op diverse plaatsen in dit stramien zul je zien dat de invoer in cellen beperkt is met behulp van Gegevensvalidatie; zie bijvoorbeeld de cel C9 (alleen Ja en Nee zijn toegestaan).
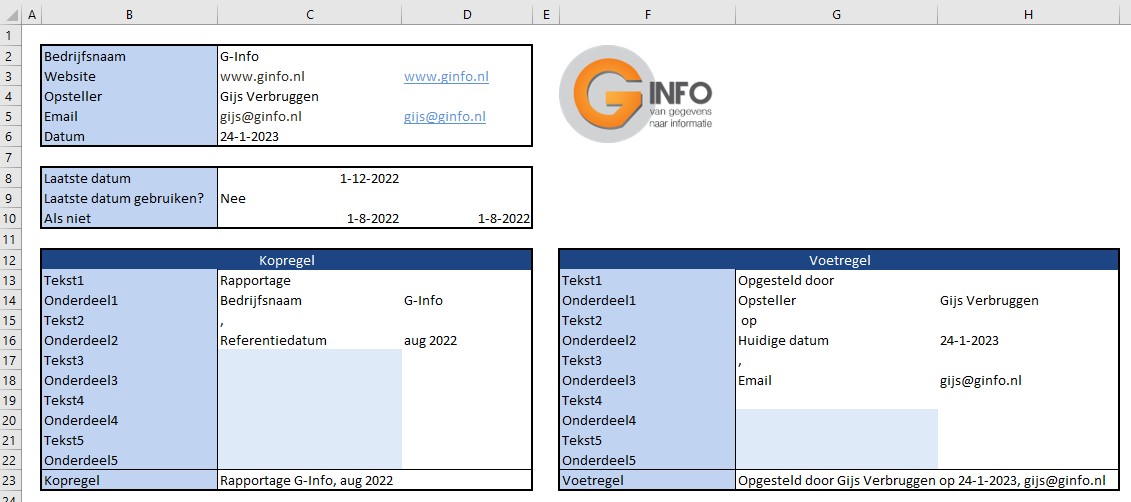
In de regels 13 tot en met 22 kun je zelf de diverse onderdelen (en teksten) kiezen die in de kop- en voetregel van een rapportage moeten komen.
NB4 in cel G19 staat een spatie om er voor te zorgen dat de voetregel aan de rechterkant niet tegen de rand aan komt.
Experimenteer met de mogelijkheden en beoordeel het effect op de rapportages in de tabbladen Ovz1 en Ovz2.
Basis-instellingen
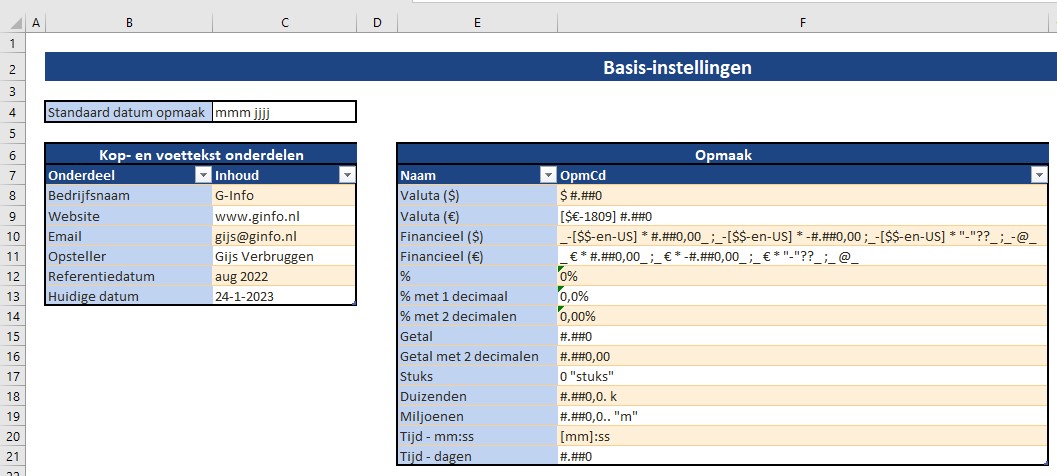
Het tabblad Basis van het Voorbeeldbestand begint met een standaardopmaak voor datums (in dit geval hebben we gekozen voor 3 letters voor de maand, een spatie en 4 cijfers voor het jaar). Daaronder staan 6 items die als onderdeel voor de kop- en voetregels kunnen dienen. In het blok in de kolommen E en F staan diverse opmaak-omschrijvingen en -codes die bij het weergeven van gegevens in de rapportage gebruikt kunnen worden.
NB aangezien alle keuze-items in Excel-tabellen zijn opgenomen zal een gewenste uitbreiding van de opties direct overal in de werkmap geëffectueerd worden.
Overige instellingen
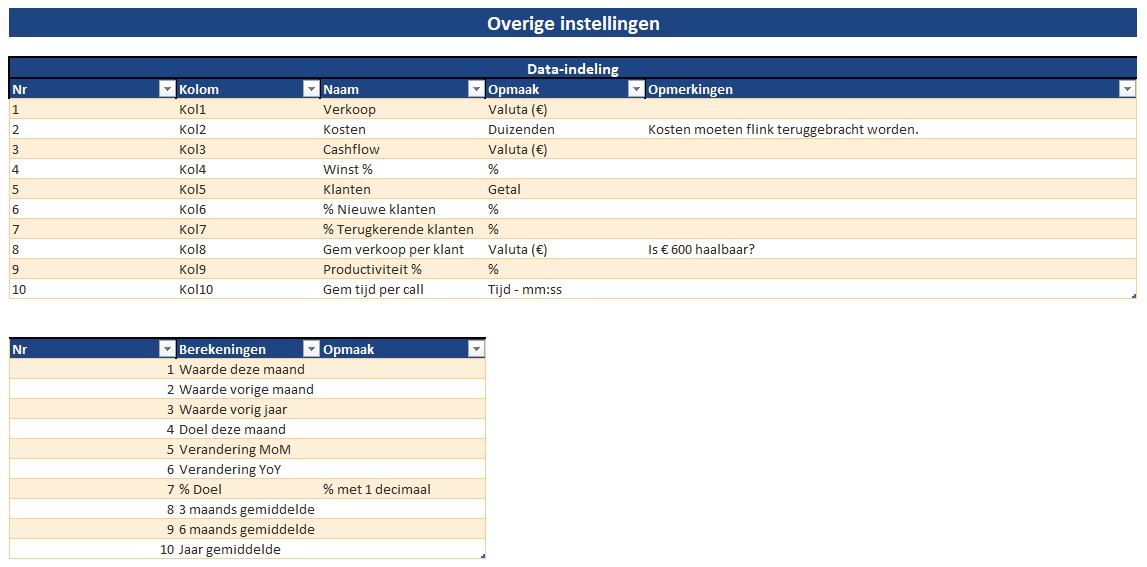
In het eerste blok van de Overige instellingen (zie het tabblad Instel van het Voorbeeldbestand) wordt van maximaal 10 items vastgelegd wat de inhoud is, welke opmaak uit de lijst van het tabblad Basis deze moeten hebben en eventuele opmerkingen er in de rapportage moeten worden weergegeven. Voor uw eigen rapportage moeten/kunnen de kolommen Naam, Opmaak en Opmerkingen aangepast worden.
Daaronder staat een Excel-tabel met daarin de omschrijvingen van de berekeningen die op de gegevens kunnen worden toegepast. De berekeningen zelf staan op het tabblad Berekeningen. Ook hier zult u voor uw eigen rapportage aanpassingen moeten doorvoeren en wel in de tweede en derde kolom.
NB in het voorbeeld-stramien staan 10 berekeningen, maar dit mogen er ook meer (of minder) zijn.
LET OP de opmaak van berekende items is standaard gelijk aan de opmaak van de onderliggende data; in het voorbeeld hierboven zal de opmaak van Waarde deze maand in het geval van Verkoop-cijfers gelijk zijn aan Valuta, maar die van Klanten heeft dus de opmaak Getal. Maar bij berekening 7 (in dit geval) geven we aan dat alle items hiervan de opmaak % met 1 decimaal zullen hebben.
Als laatste geven we nog aan wat voor een soort rapportage het hier betreft. Er zijn 2 mogelijkheden: alleen de data van het lopende jaar worden getoond (YtD = Year to Date) of altijd de laatste 12 maanden (YoY = Year on Year).
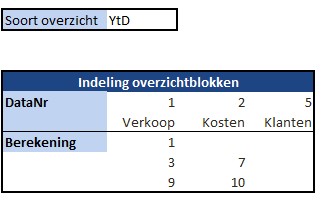
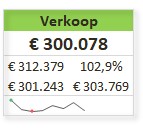
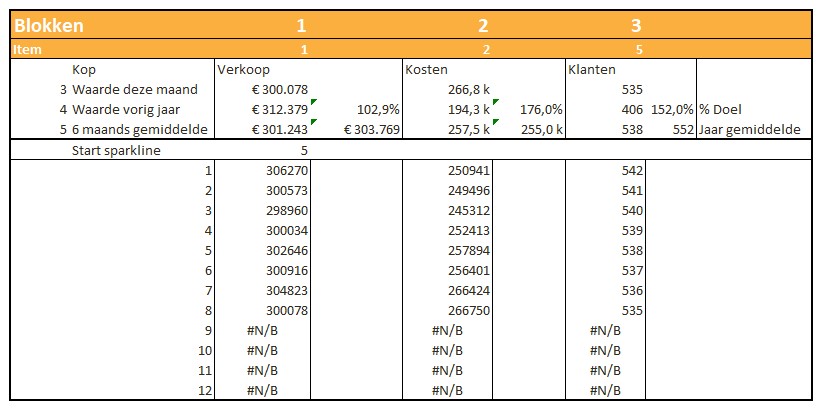
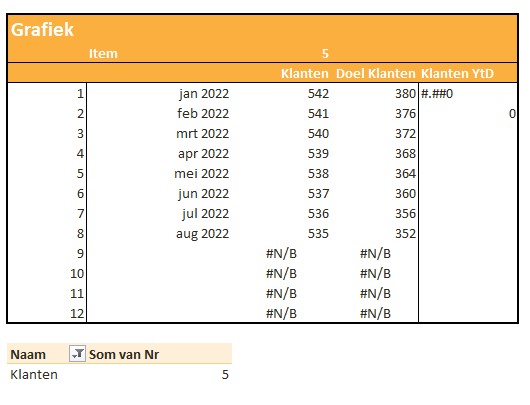
Iedere rapportage-pagina heeft bovenaan 3 blokjes met de belangrijkste gegevens/berekeningen. Bij Indeling overzichtsblokken wordt bij DataNr allereerst aangegeven welke 3 van de 10 items moeten worden getoond; bij Berekening kun je 5 opties kiezen die voor deze items moeten worden weergegeven.
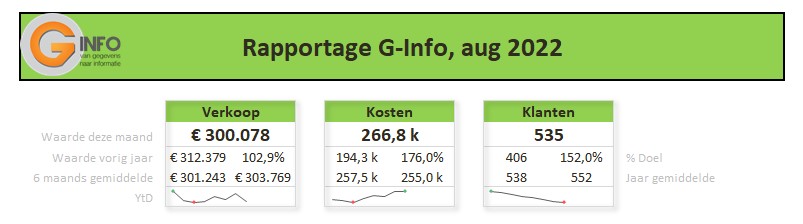
De sparkline daaronder geeft het verloop in de tijd weer van het betreffende item (YtD of YoY). Met de instellingen zoals hierboven is het resultaat:
Data
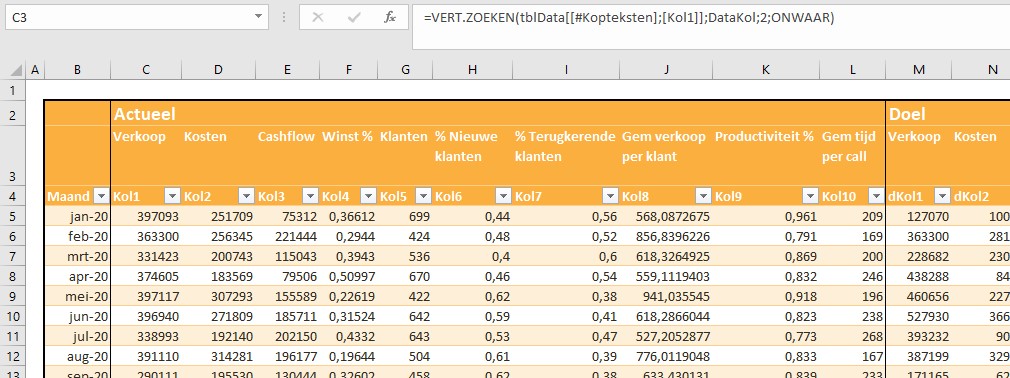
In het Voorbeeldbestand is het tabblad Data gevuld met fictieve gegevens. Het systeem is beperkt tot 10 kolommen met gegevens waarvan de namen vastliggen in het tabblad Instel.
Per maand dienen alle gewenste kolommen met de juiste data gevuld te worden. Gebruik je ook berekeningen waarbij de actuele gegevens afgezet worden tegen de beoogde resultaten dan dienen ook de Doel-kolommen gevuld te worden.
Berekeningen
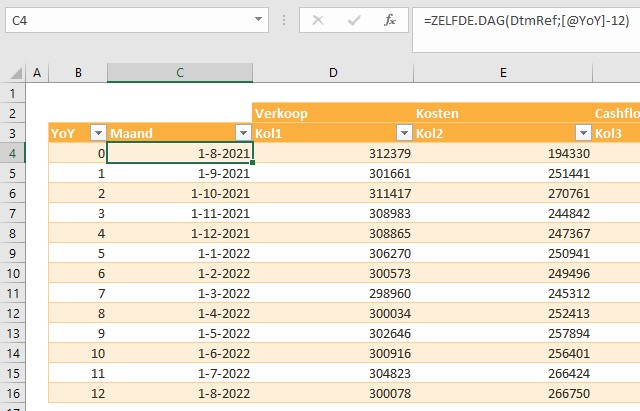
In het tabblad Berekeningen van het Voorbeeldbestand worden allereerst van alle 10 items (en de daarbij behorende doelen) de YoY-data opgehaald.
Daaronder wordt de opmaak van (nu) maximaal 16 berekeningen per item bepaald. De betreffende formule is uitdagend te noemen: =ALS(INDEX(tblBerekOpties[Opmaak];[@Nr])=0;INDEX(tblOpmaak[OpmCd];VERGELIJKEN(INDEX(tblDataInd[Opmaak];VERGELIJKEN(tblYoY[[#Kopteksten];[Kol1]];tblDataInd[Kolom];0));tblOpmaak[Naam];0));INDEX(tblOpmaak[OpmCd];VERGELIJKEN(INDEX(tblBerekOpties[Opmaak];[@Nr]);tblOpmaak[Naam];0)))
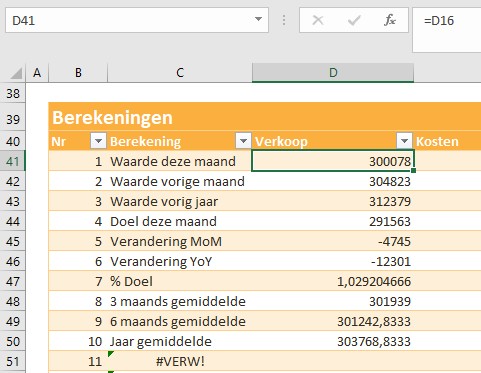
In het derde blok worden de benodigde berekeningen gedefinieerd. In cel D41 staat een simpele verwijzing naar een cel uit het eerste blok.
De formule waarmee berekening 8 (het gemiddelde van de laatste 3 maanden) wordt uitgevoerd, is: =GEMIDDELDE(VERSCHUIVING(D16;-2;0;3;1)) ofwel we gaan vanaf cel D16 2 regels omhoog en 0 kolommen naar rechts/links en kiezen dan een blok cellen, 3 hoog en 1 breed; van deze range wordt het gemiddelde bepaald.
Nog even de vorige 2 stappen combineren met (in cel D61) de formule: =ALS.FOUT(TEKST(D41;D21);0)
Dus met de functie TEKST wordt de inhoud van cel D41 opgemaakt met de inhoud van cel D21. Als dit onverhoopt een probleem oplevert, dan wordt de waarde 0 weergegeven.
Met al dat voorwerk kunnen we nu de blokjes in de kop van de rapportages samenstellen. Ook de cijfers voor de sparklines worden klaar gezet.
Omdat we ook een grafiek in de rapportage willen opnemen, moeten we de benodigde gegevens nog even klaar zetten.
Onderaan staat een draaitabel. Een Slicer in de rapportage bepaalt welk item we willen weergeven. Het betreffende nummer gebruiken we in het grafiekblok.
Rapportage-pagina’s
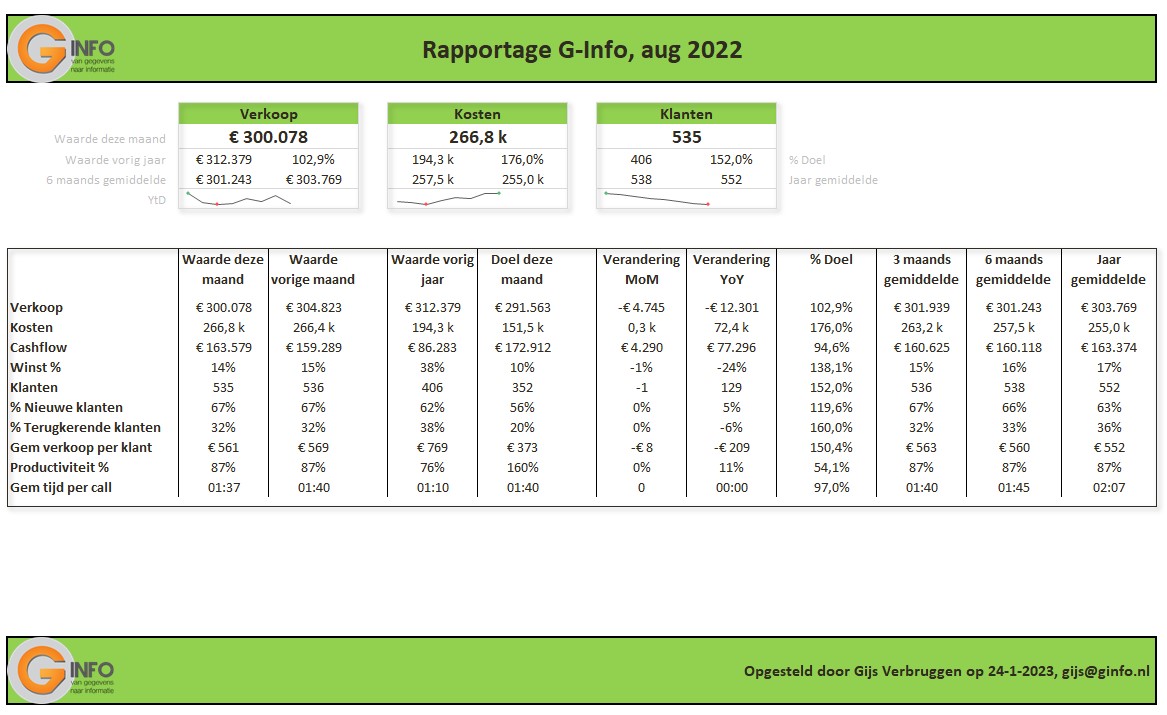
In het tabblad Ovz1 van het Voorbeeldbestand staat een eerste voorbeeld van een rapportage gebaseerd op alle berekeningen uit de rest van het werkblad. Wijzigingen in de diverse tabbladen hebben direct effect op het resultaat. Kies in de slicer aan de rechterkant van de grafiek een ander item en je krijgt de bijbehorende grafiek.
Wil je naast de drie belangrijkste items met de berekeningen in de blokjes aan de bovenkant van de pagina alle info in één oogopslag: zie het tabblad Ovz2 van het Voorbeeldbestand.
Uiteraard is dit nog geen totaal rapportage; ongetwijfeld kunt u nog andere invalshoeken vinden die van belang zijn. Kopieer een Ovz-tabblad en ga aan de slag!
Het vorige artikel ging over Voorspellen. We hebben daar laten zien hoe je op diverse manieren op basis van historische gegevens iets kunt zeggen over de toekomst. Dat daarbij veel ‘slagen om de arm’ gehouden moeten worden, mag duidelijk zijn: als er ook maar iets in de omgevingsfactoren verandert, kunnen de voorspellingen ver afwijken van de nog te behalen resultaten.
In dit artikel gaan we de zaak omdraaien: op basis van feiten/metingen én scenario’s voor omgevingsfactoren berekenen we de consequenties voor de toekomstige resultaten.
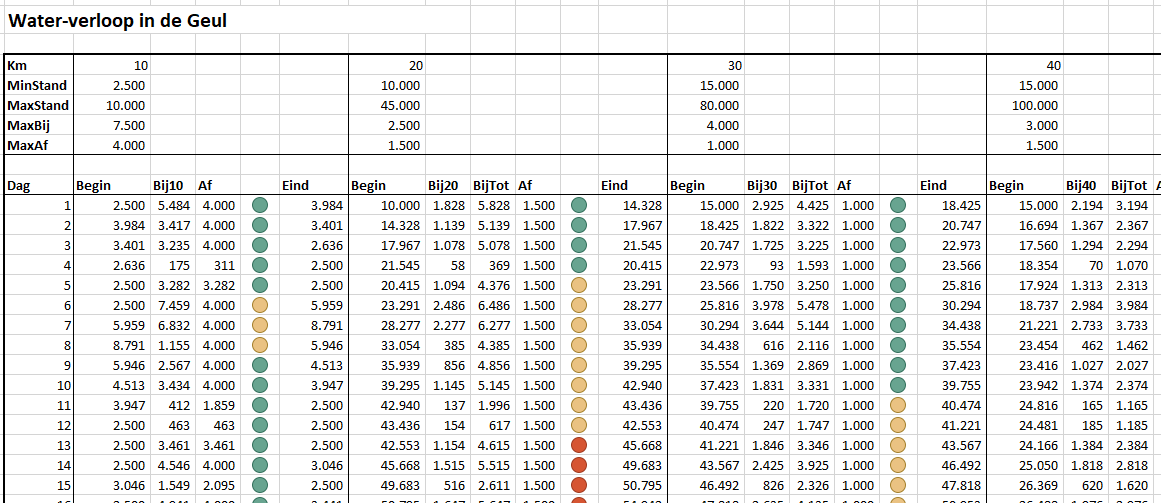
Als voorbeeld voor de werkwijze kijken we of we de waterstanden in de Geul (het gedeelte vanaf de bron tot aan Valkenburg) op deze manier zouden kunnen voorspellen. Alvast een disclaimer: het is nog een heel eenvoudig model, dus ik blijf nog even, 75 meter hoger, in Heerlen wonen!
In dit voorbeeld wordt gebruik gemaakt van enkele (minder bekende) Excel-technieken: kruispunt van reeksen en het toepassen van een zelf-gedefinieerde kansverdeling.
Probleem-beschrijving
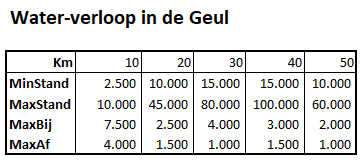
Zoals gezegd gaan we het probleem flink versimpelen zodat we het in een eenvoudig model kunnen gebruiken (zie het tabblad Data van het Voorbeeldbestand):
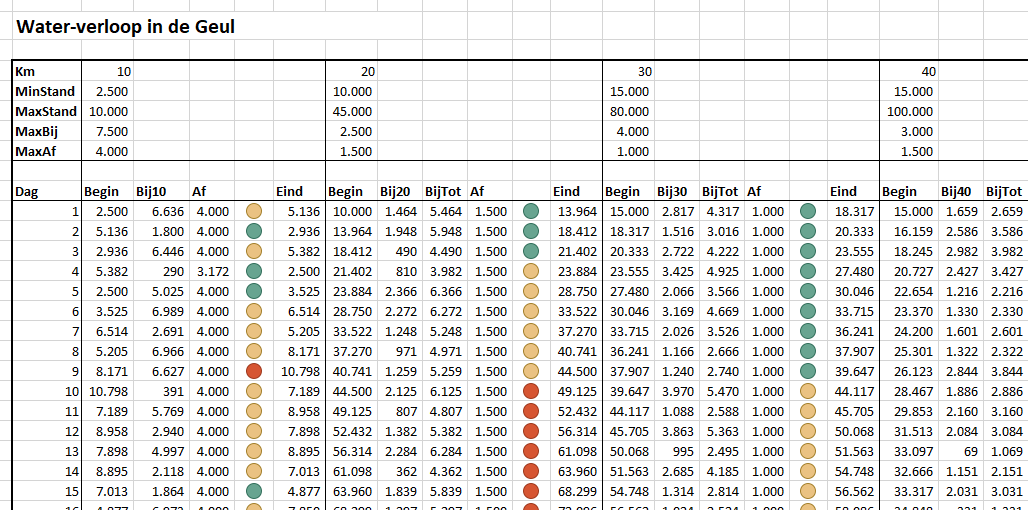
vanaf de bron slingert de Geul zich over ongeveer 50km naar Valkenburg
dit gedeelte van de rivier wordt in 5 gelijke delen verdeeld
per deel ligt vast hoeveel water er altijd blijft staan (MinStand). Vanaf de bron is de rivier gemiddeld 1m breed en er staat altijd minimaal 25cm water, dus dat is 2.500m3. In Valkenburg is de rivier maar 2m breed, maar is altijd minstens 50cm diep.
ook leggen we de hoeveelheid water vast (MaxStand) waarbij het gebied gaat overstromen. Vanaf de bron neemt deze maximale stand toe; net voor Valkenburg heeft de rivier de ruimte in de breedte, maar in het stadje wordt die over een flink stuk ingeperkt tot 2m.
door regenval komt er water bij. Per deel ramen we de maximale hoeveelheid water dat daar per dag in de rivier terecht komt (MaxBij).
als laatste hebben we nog nodig hoeveel water er dagelijks maximaal afgevoerd kan worden (MaxAf; vaak beperkt door het meanderen, versmallingen etcetera).
NB nog maar een keer: dit zijn heel simpele benaderingen; om het model te verbeteren zouden exactere metingen moeten worden uitgevoerd.
Kruispunt
Voordat we het eerste model gaan bekijken bespreken we eerst een Excel-techniek die in dat model gebruikt zal worden.
In het overzicht op het tabblad Data hebben diverse reeksen een naam gekregen: de gegevens achter MinStand, MaxStand et cetera krijgen de naam uit de eerste kolom. Voor de kolommen zouden we ook zoiets willen doen, maar de kolomkoppen bestaan uitsluitend uit getallen en Excel-namen moeten beginnen met een letter of speciaal teken. Ook één of twee letters er voor zetten is niet voldoende omdat er dan een verwijzing naar een kolomnaam ontstaat. We hebben er voor gekozen om de gegevens in de kolommen de naam _Km10, _Km20 et cetera te geven.
Om in een tabel gegevens op te zoeken gebruiken we vaak Vert.Zoeken of een combinatie van Index en Vergelijken.
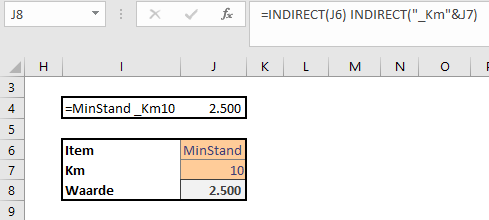
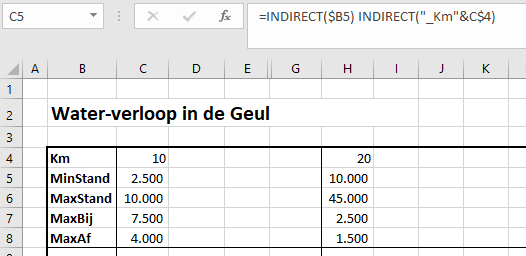
In het Voorbeeldbestand gebruiken we de kruispunt-techniek: in cel J4 van het tabblad Data staat de formule =MinStand _Km10.
LET OP de 2 namen moeten gescheiden zijn door een spatie.
Het resultaat van de formule is de inhoud van de cel op het kruispunt van de 2 reeksen.
We kunnen de formule dynamisch maken: in plaats van harde namen, willen we verwijzingen naar cellen gebruiken. Helaas: een gewone verwijzing werkt niet, we moeten de functie Indirect gebruiken (zie de formule in cel J8: =INDIRECT(J6) INDIRECT(“_Km”&J7)). Plaats wel een spatie tussen de 2 Indirect-functies!
Eerste model
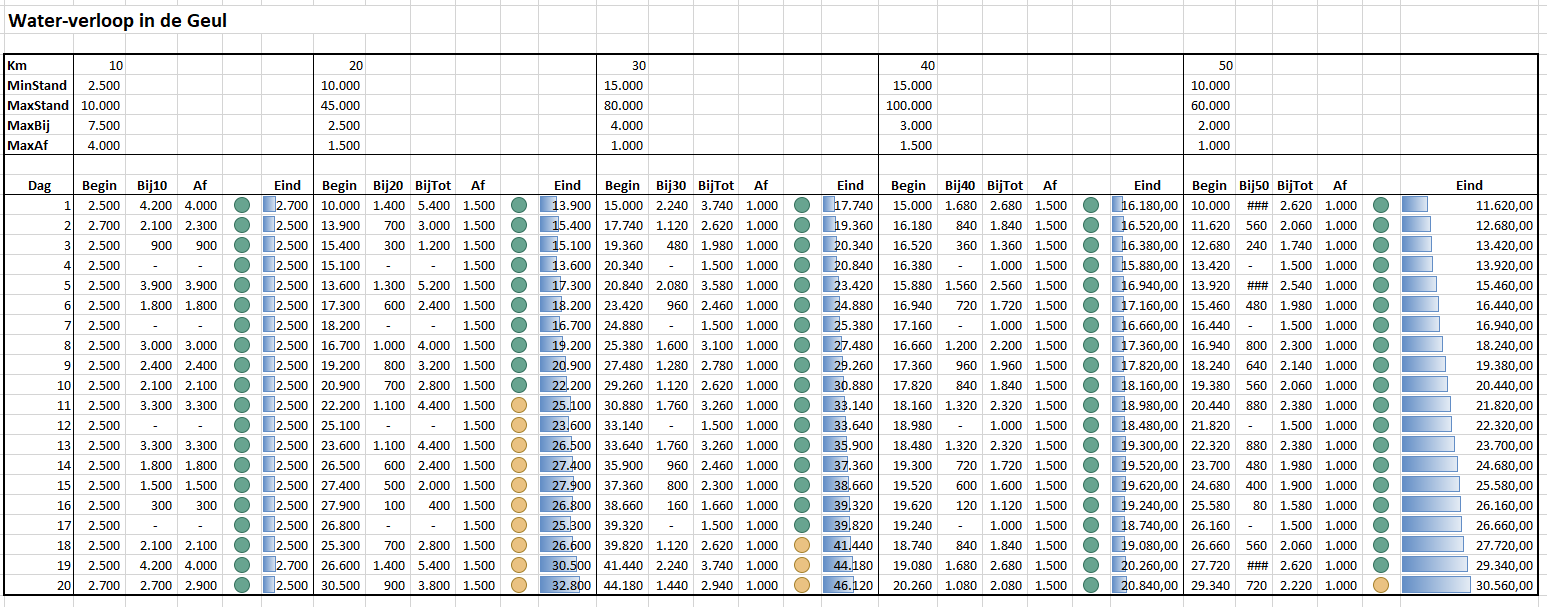
Op het tabblad Simpel van het Voorbeeldbestand nemen we allereerst met de kruispunt-techniek de gegevens uit het tabblad Data over. Door een juiste mix van absolute en relatieve verwijzingen kan de formule uit cel C5 overal gekopieerd worden.
Om te voorkomen dat per ongeluk basis-gegevens worden overschreven zijn de model-tabbladen beveiligd (wel zonder wachtwoord). Wil je gegevens wijzigen, doe dat dan in het tabblad Data.
De opbouw van het model:
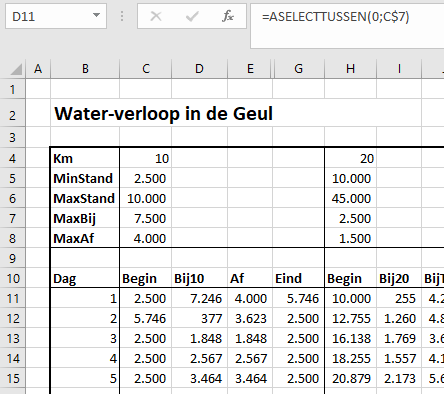
we gaan ervanuit dat op dag 1 de rivier overal de minimumstand heeft.
in de kolom daarnaast bepalen we de hoeveelheid water die er bij komt, door een willekeurig getal te kiezen tussen 0 en MaxBij voor dat deel van de rivier.
de hoeveelheid water, dat wordt afgevoerd, wordt bepaald door de formule (in cel E11) =ALS(C11+D11>C$5;MIN(C$8;C11+D11-C$5);0) Dus als de beginstand plus het water, dat er bij komt, meer is dan de minimumstand dan wordt er water afgevoerd, anders niets. De afvoer is gelijk aan de beginstand plus de toevoer minus de minimale stand. Maar als daarmee de MaxAf wordt overschreden, dan wordt de MaxAf afgevoerd.
de berekening van de eindstand (in cel G11) is dan makkelijk: =C11+D11-E11
de beginstand van de volgende dag is de eindstand van de dag er voor. De berekening van de overige gegevens van die dag is gelijk aan die van de eerste dag.
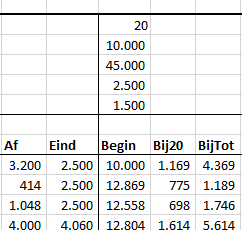
bij de volgende delen van de rivier is de berekening precies hetzelfde met één verschil: de hoeveelheid water dat er per dag bij komt is niet alleen de hoeveelheid regen maar ook de hoeveelheid die uit het vorige deel van de rivier komt (kolom Af).
Zo gaat het resultaat er dan uitzien (zie het tabblad Simpel van het Voorbeeldbestand):
Om snel te zien of de eindstanden per dag nog ‘behapbaar’ zijn, zijn er kolommen tussengevoegd met een voorwaardelijke opmaak (stoplichtmodel).
Druk op F9 (herberekenen) en u ziet wat de consequenties volgens dit model zijn voor de waterstromen in de Geul. Vanwege de willekeurige hoeveelheid regen, die gegenereerd wordt, wijzigen iedere keer alle resultaten. Hou F9 vast en u ziet snel waar de grootste problemen worden verwacht.
Aangepast model
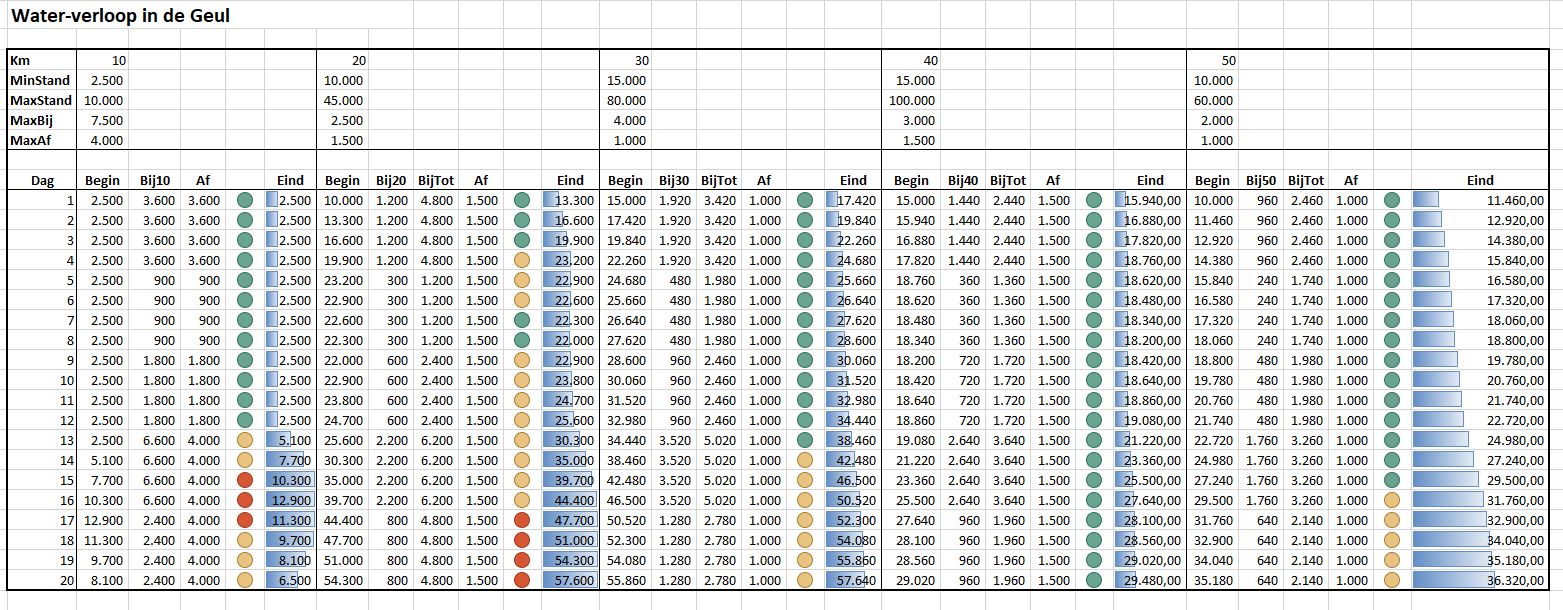
Eén van de gehanteerde aannames (los van de onderliggende ‘metingen’) rammelt nogal: als het in één deel hard regent, dan kan het in het volgende deel bijna droog zijn. Dat is natuurlijk op zo’n korte afstand helemaal niet reëel. Op het tabblad Afh van het Voorbeeldbestand vindt u dan ook een ander model. Daarbij krijgt het eerste deel van de rivier per dag nog steeds een willekeurige hoeveelheid regen, maar de andere delen krijgen op die dag een evenredige hoeveelheid. In cel I11 staat daartoe de formule: =H$7*D11/C$7 De maximaal verwachte regen in het tweede deel (H7) wordt vermenigvuldigd met de hoeveelheid regen in het eerste deel (D11) gedeeld door de maximaal verwachte regen in het tweede deel (C7) .
Maar als je nu F9 gebruikt, zul je zien dat deze aanpassing voor de resultaten nog niet zoveel uitmaakt. Ook nu ontstaan in het tweede gedeelte van de rivier al snel overstromingen.
Eigen kansverdeling
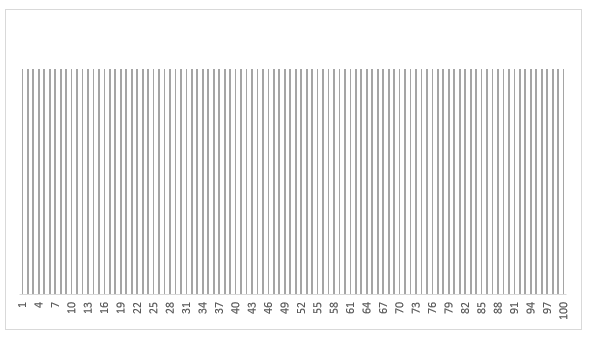
Bij de vorige modellen hebben we gebruik gemaakt van een zogenaamde discrete, uniforme verdeling (iedere hoeveelheid regen heeft even veel kans om voor te komen).
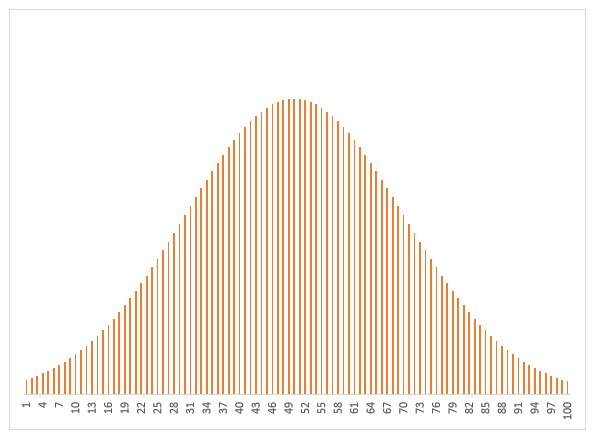
Een andere bekende verdeling is de normale distributie.
Maar allebei geven ze niet goed weer hoe de regen zich gedraagt in onze regio.
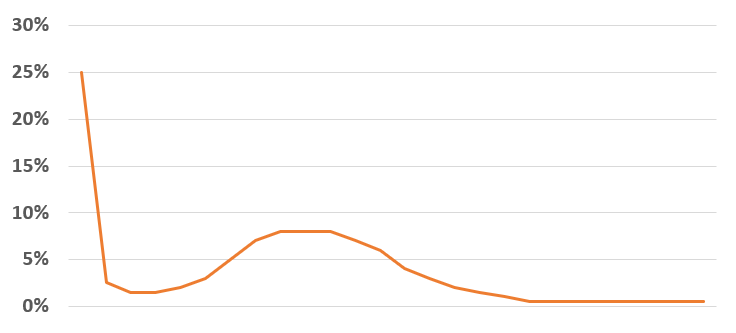
De kans dat het op een dag niet regent is (gelukkig) groter dan alle andere mogelijkheden. Maar als het regent dan komt er ook echt wel wat naar beneden.
Uniforme verdelingNormale verdeling
De volgende verdeling geeft dat idee weer:
De kans dat het niet regent is in dit voorbeeld 25%, kans op een heel klein beetje regen is klein, de kans op iets meer regen wordt groter en de kans op heel veel regen is heel klein. Deze verdeling zouden we in ons model willen gebruiken. Voordat we dat doen, kijken we even gedetailleerder naar deze verdeling.
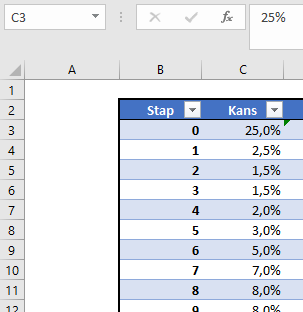
In het tabblad KansVerdeling van het Voorbeeldbestand is de gewenste verdeling ‘met de hand’ ingevuld. Stap 0 krijgt een kans van 25%, de volgende stap 2,5%, dan 1,5% et cetera tot en met stap 25 die een kans van 0,5% heeft.
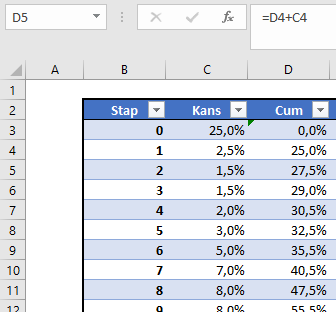
De tabel (met de naam Tabel1) heeft ook nog een cumulatieve kolom. LET OP in deze kolom staan de cumulatieven tot en met de VORIGE stap!
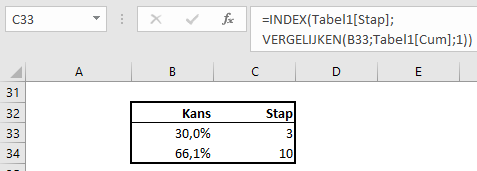
We gaan deze tabel gebruiken om vanuit een percentage in de cumulatieve kolom de daarbij behorende stap op te zoeken. Een combinatie van de functies Index en Vergelijken levert het gewenste resultaat:
NB de 3e parameter in de functie Vergelijken heeft de waarde 1. De functie zoekt dan naar de grootste waarde die kleiner dan of gelijk is aan de Zoekwaarde (de eerste parameter).
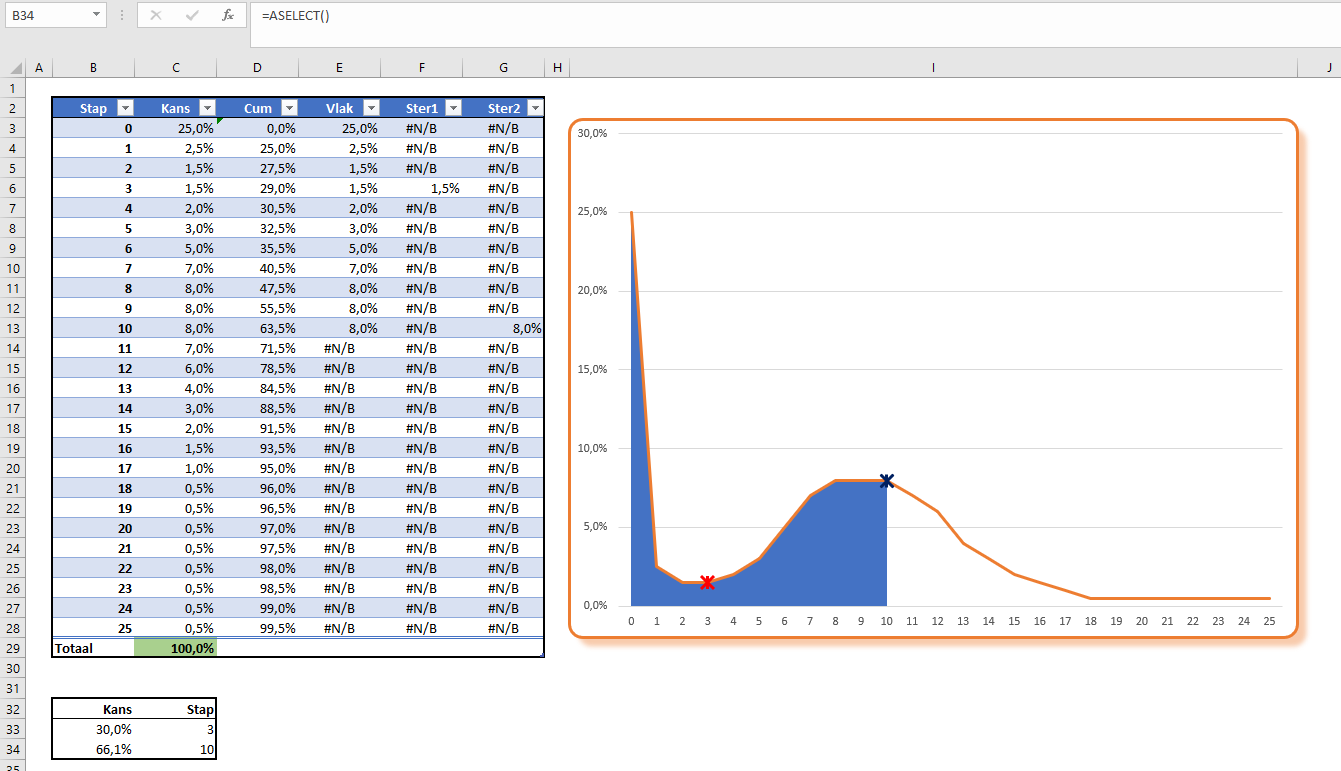
In cel B34 wordt telkens een willekeurig getal tussen 0 en 1 berekend, in C34 staat dan de bijbehorende stap. De rode ster in de grafiek geeft de positie aan van de 30%-kans, de zwarte ster die van de kans uit cel B34. Druk op F9 om in B34 een andere kans te genereren.
Met deze techniek vertalen we een continue, uniforme distributie naar een discrete, gewenste verdeling. 25% van de willekeurige getallen in cel B34 laten in cel C34 een stap=0 zien, 2,5% genereren een stap=1, 1,5% een stap=2 enzovoort.
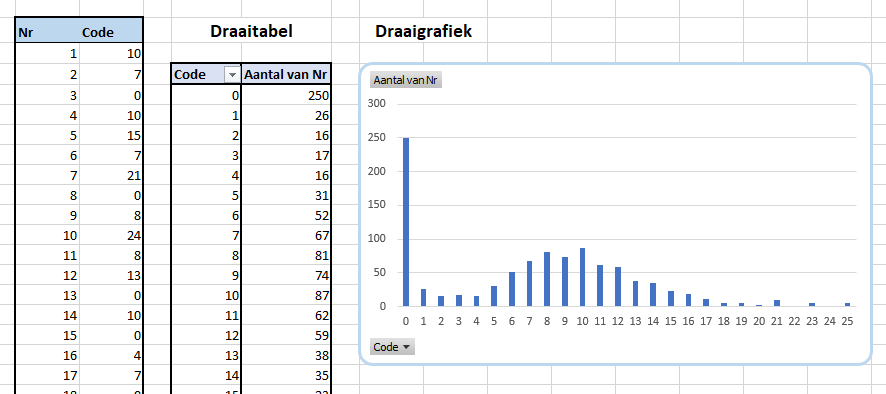
Ter controle worden in het tabblad VerdContr telkens 1.000 percentages gegeneerd, die op bovenstaande manier naar een Code worden vertaald. Wanneer deze codes in een draaitabel worden gezet, kunnen we daarop een draaigrafiek baseren. We zien dan onze gewenste verdeling terug.
NBVernieuw de draaitabel en alles wijzigt. Aangezien Excel automatisch alles opnieuw berekent (en dus ook nieuwe kansen bepaalt) hoeven we niet meer op F9 te drukken om nieuwe codes te krijgen.
Laatste model
In het tabblad Verdeling van het Voorbeeldbestand hebben we bovenstaande verdeling en techniek gebruikt om het model te verbeteren. In de Bij-kolom in het 10-km-deel van de Geul gebruiken we de formule: =INDEX(Tabel1[Stap];VERGELIJKEN(ASELECT();Tabel1[Cum];1))*C$7/MAX(Tabel1[Stap]) Dus de gevonden stap wordt geschaald naar een waarde tussen 0 en de maximaal verwachte regenval.
NB1 je kunt de gewenste verdeling verfijnen door meer stappen in te voegen; door MAX(Tabel1[Stap]) wordt de gevonden stap op de juiste manier gecorrigeerd. Zorg wel dat de som van de kansen in de gewenste verdeling precies 100% is.
NB2 aan de Eind-kolommen is nog een voorwaardelijke opmaak toegevoegd waardoor de ‘waterstand’ snel kan worden ingeschat.
Allerlaatste model
In het vorige model kan de hoeveelheid regen van dag op dag flink fluctueren; dat is natuurlijk niet helemaal de realiteit. In het tabblad Verdeling4gelijk van het Voorbeeldbestand hebben we er voor gezorgd dat er telkens 4 dagen op een rij ‘hetzelfde weer’ is, beter gezegd dat het telkens 4 dagen even veel regent.
En zo kunnen we nog wel even doorgaan. Iedere aanpassing aan het model roept weer vragen op en nodigt uit tot nieuwe aanpassingen. Wat te denken van de continue toename van het water in Valkenburg. Hoe zal de situatie daar zijn na 40 dagen???? Ergens zit nog iets geks in het model.
Maar goed, we laten de verdere verfijning over aan Rijkswaterstaat 😉
Overal kom je ze tegen, histogrammen: een grafische weergave van een frequentietabel.
Iedereen die met Excel werkt, heeft wel eens zoiets gemaakt.
In dit artikel laten we diverse mogelijkheden de revue passeren om zo’n overzicht te maken. We zoomen daarbij vooral in op verschillende methoden om een frequentietabel te maken. Volgende keer komen diverse alternatieven voor het histogram aan bod.
Voor het maken van een frequentietabel is de functie INTERVAL heel erg handig. Maar ook enkele ‘vreemde’ eigenschappen daarvan komen aan bod (zoals beloofd in Excel en kaarten 2).
Basis
Zoals gezegd: je komt ze bijna dagelijks tegen, histogrammen (en dus ook frequentietabellen). Ieder krantenartikel, waarin aantallen voorkomen, wordt wel verduidelijkt (?) met een grafiekje. Maar ook HR-medewerkers zijn er verzot op (leeftijds-, functie- en salarisopbouw kunnen daar goed mee worden geïllustreerd) en ook leerkrachten in het onderwijs gebruiken het veel (om de verdeling van proefwerkpunten te bepalen bijvoorbeeld).
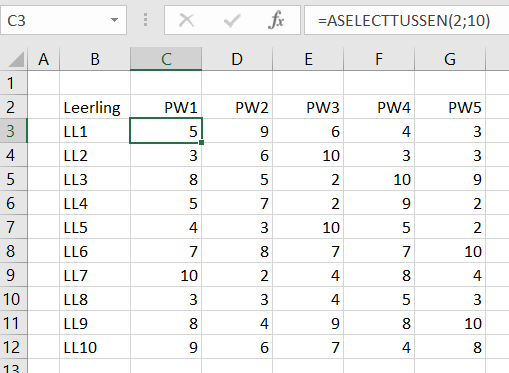
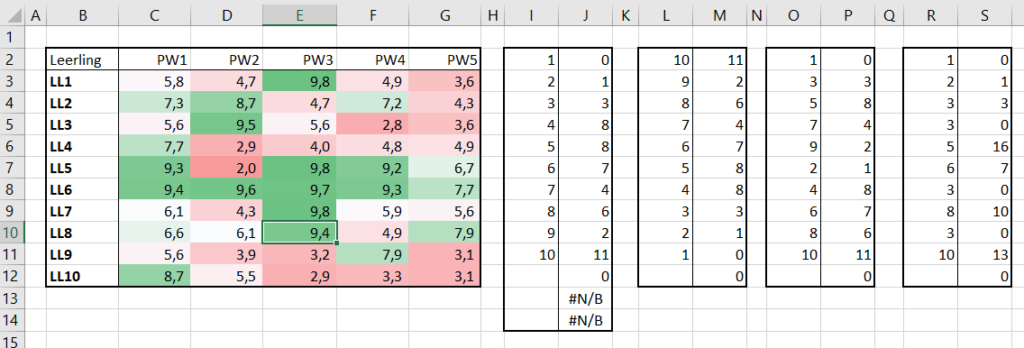
In het Voorbeeldbestand op het tabblad Basis staat een fictief overzicht van de resultaten van 5 proefwerken van 10 leerlingen. Met behulp van de functie ASELECTTUSSEN worden (bij een wijziging in Excel of het drukken op F9) iedere keer nieuwe resultaten tussen 2 en 10 gegeneerd (inclusief die 2 grenzen).
Op hetzelfde tabblad staat een vergelijkbaar overzicht maar daar krijgen de proefwerkresultaten 1 decimaal. De gebuikte formule wordt dan: =ASELECTTUSSEN(20;100)/10
Deze overzichten gebruiken we in het vervolg van het artikel als voorbeeld-input.
Frequentietabel 1
We beginnen met een proefwerkoverzicht zonder decimalen. Daarvan gaan we een frequentietabel maken: hoe vaak komt ieder cijfer voor.
NB direct is te zien dat het voorbeeld niet echt reëel is: het cijfer 10 komt wel heel vaak voor! Maar hoe de verdeling van de overige cijfers is, is zelfs met dit kleine aantal moeilijker te beoordelen.
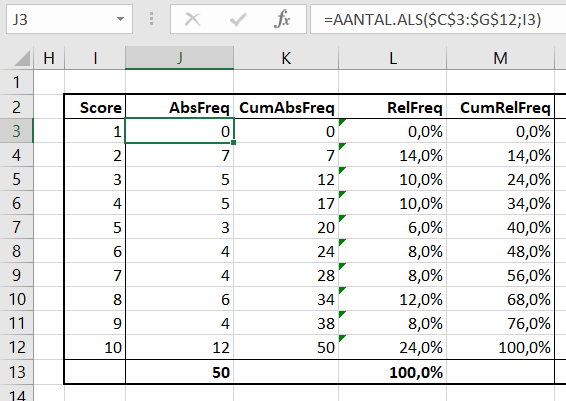
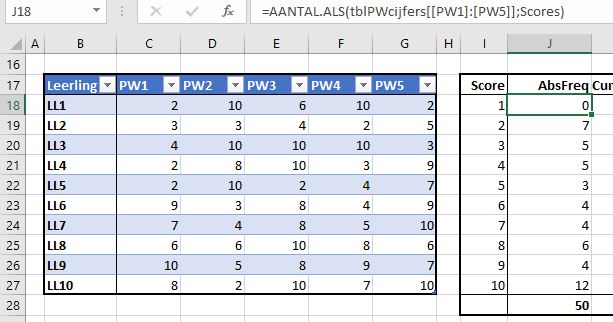
Op het tabblad FreqTabel1 van het Voorbeeldbestand staat ons eerste resultaat. In kolom J wordt de absolute frequentie van ieder mogelijk cijfer geturfd: =AANTAL.ALS($C$3:$G$12;I3)
In cel J3 tellen we het aantal keren, dat de waarde uit I3 voorkomt in het bereik C3:G12.
NB ter controle tellen we onderaan in kolom J de frequenties op, zodat we zeker weten dat alle cijfers zijn meegenomen. Selecteer de cel onder de frequenties en druk op Alt-= (dus de Alt-toets vasthouden en op = drukken). Deze sneltoets werkt ook als je getallen in een rij wilt optellen.
In kolom K bepalen we de cumulatieve absolute frequentie door bij het vorige resultaat in die kolom het resultaat uit kolom J op te tellen (in cel K4 staat de formule =K3+J4).
De formules in de kolommen L en M, waarin de relatieve en cumulatieve relatieve frequenties worden bepaald, spreken voor zich.
Absolute frequentie 2
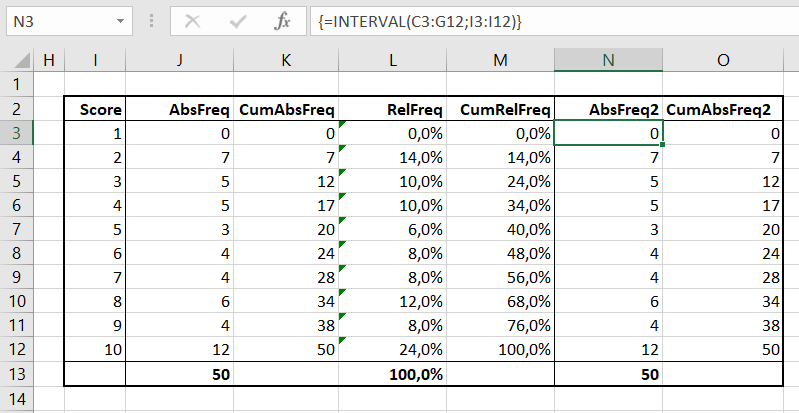
Een alternatieve methode voor het bepalen van de absolute frequentie is het gebruik van de Excel-functie Interval (zie het tabblad FreqTabel1 van het Voorbeeldbestand).
Allereerst de volgende waarschuwing: Interval is een ‘vreemde’ functie. Niet alleen de input wordt gevormd door een gebied/bereik van cellen (net als bij Som bijvoorbeeld) ook het resultaat bestaat uit meer dan één getal. Het is een zogenaamde matrix-functie.
selecteer eerst de cellen waar het resultaat moet komen. Interval levert de frequenties op, horend bij een gewenst interval. In dit geval bij de cijfers 1 t/m 10. Dus het resultaat moet uit 10 cellen bestaan. LET OP het resultaat van de functie Interval moet altijd in een kolom komen, dus selecteer cellen ONDER ELKAAR. In het voorbeeld de cellen N3:N12.
tik in =interval(
voer dan de eerste parameter van de functie in, de Gegevensmatrix. Dit zijn de brongegevens, in dit geval het bereik C3:G12.
tik in ;
dan komt de tweede parameter, de Interval_verw. Dit moeten cellen zijn die de gewenste intervallen aangeven; in het voorbeeld de cellen I3:I12.
tik in )
sluit de functie NIET af door op Enter te drukken, maar tegelijkertijd op Ctrl-Shift-Enter. Op deze manier wordt een matrix-formule ingevoerd, ook wel een CSE-formule genoemd. In de 10 cellen staat nu overal exact dezelfde formule: {=INTERVAL(C3:G12;I3:I12)} LET OP de accolades hebben we niet zelf ingevoerd; dit is een indicatie dat hier een matrix-formule staat. Onderdelen van een matrix-formule kunnen niet worden gewijzigd, er kunnen geen regels tussengevoegd worden etc. Wil je een wijziging doorvoeren: selecteer alle bij elkaar horende cellen, klik in de Formulebalk en druk op Ctrl-Enter. Nu wordt in alle cellen dezelfde formule ingevoerd, maar niet als matrix-formule en dus horen ze niet meer bij elkaar. NB in de Engelstalige Excel-versies heet deze functie Frequency; dit geeft beter de bedoeling van de functie aan dan Interval.
NB1 het is in een matrix-formule niet nodig om de bereiken absoluut (met $-tekens) in te voeren.
NB2 hiervoor hebben we net gedaan of de Interval-functie de frequenties van de diverse cijfers heeft geturfd, maar eigenlijk zijn de waardes in het bereik Interval_verw de te hanteren bovengrenzen van de diverse intervallen. Maar aangezien de proefwerkpunten geen decimalen bevatten, zijn de bovengrenzen ook de enige cijfers die in dat interval voorkomen.
Cumulatieve absolute frequentie 2
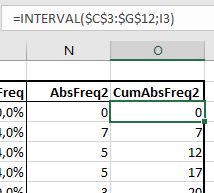
In cel O3 van het tabblad FreqTabel1 van het Voorbeeldbestand hebben we de formule =INTERVAL($C$3:$G$12;I3) geplaatst. Er is maar 1 bovengrens van een interval, dus ook maar 1 resultaat. De formule hoeft dan ook niet met CSE afgesloten te worden, een Enter volstaat.
Deze formule turft het aantal keren, dat een getal uit het bereik van de eerste parameter kleiner of gelijk is aan de waarde in cel I3. In dit geval dus <=1; dat komt in het voorbeeld niet voor. Wanneer deze formule naar beneden gekopieerd wordt krijgen we de gewenste cumulatieve resultaten.
Histogram
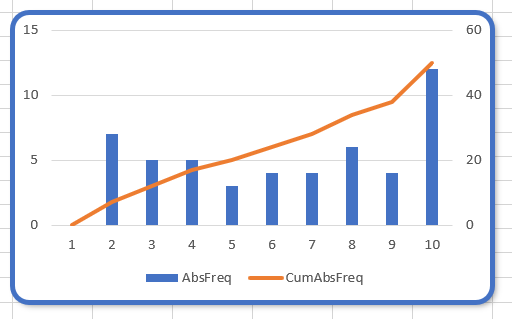
Bij een frequentietabel hoort ook de grafische weergave, een histogram.
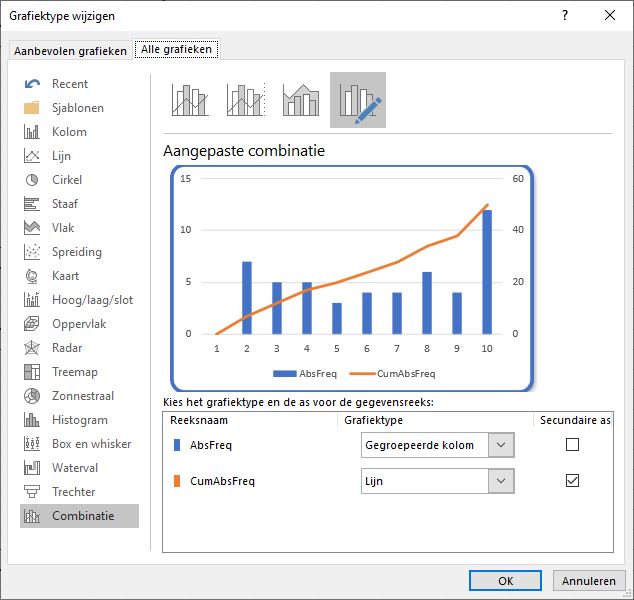
Maak een grafiek met daarin de absolute frequentie en de cumulatie daarvan, zorg dat op de x-as de intervalgrenzen komen (dus de cijfers 1 t/m 10) en zorg dat het een combinatiegrafiek wordt met de cumulatieve waarden uitgezet op de secundaire as.
LET OP kies bij het gebruik van een secundaire as de maximale waarden van de assen zodanig dat de horizontale rasterlijnen aan allebei de kanten bij weergegeven getallen uitkomen. In dit geval is het maximum rechts 4x groter dan links.
In een volgend artikel zullen we diverse andere methoden voor het maken van een histogram de revue laten passeren met daarbij de voor- en nadelen van de diverse alternatieven.
NB wanneer de brongegevens in de loop van de tijd nog uitgebreid worden, plaats deze dan in een Excel-tabel. Na uitbreiding hiervan wordt automatisch de frequentietabel geactualiseerd (zie het tweede blok op het tabblad FreqTabel1 van het Voorbeeldbestand). In het voorbeeld was het dan wel logischer geweest als ik de proefwerken in de rijen had geplaatst en de leerlingen in de kolommen! Maar in mijn-tijd-als-docent was dit wel de indeling in de lerarenagenda:
Frequentietabel 2
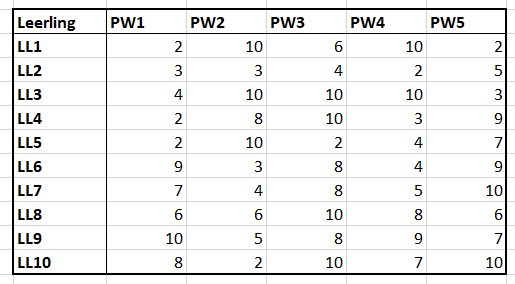
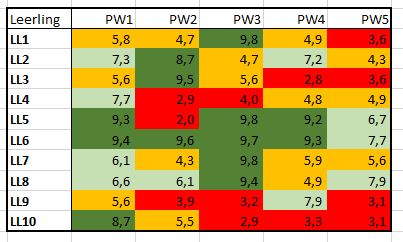
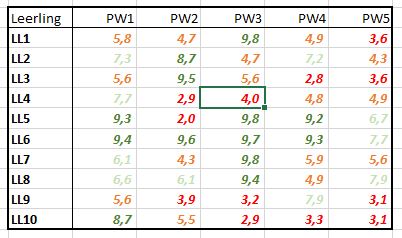
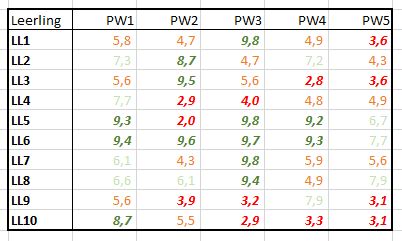
We gebruiken hetzelfde soort proefwerkoverzicht als in het vorige hoofdstuk, maar nu met 1 decimaal (zie het tabblad FreqTabel2 van het Voorbeeldbestand). Dankzij de voorwaardelijke opmaak van Excel zien we snel waar de hoge en lage punten zitten.
Hadden we dat vroeger in de lerarenagenda ook maar zo makkelijk gehad. Toen gebruikten we gekleurde pennen (exacter uitgedrukt: pennen met gekleurde inkt) met alle problemen van dien, als een cijfer achteraf nog aangepast moest worden.
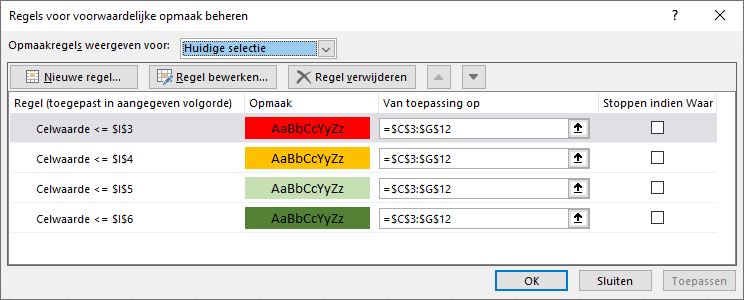
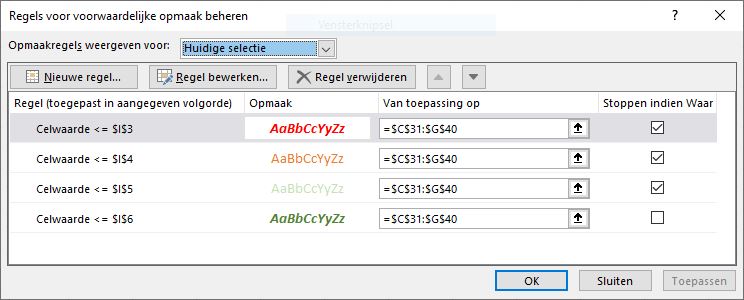
Om de voorwaardelijke opmaak te kunnen toepassen gebruiken we een hulpkolom I; in de cellen I3:I6 staan de cijfers 4, 6, 8 en 10. De regels voor de voorwaardelijke opmaak zien er als volgt uit:
De vorige opmaak leverde wel een bonte kermis op. Het mag wel wat subtieler. Maar daardoor is het iets moelijker om te zien in welke categorie een cijfer valt.
De gebruikte regels:
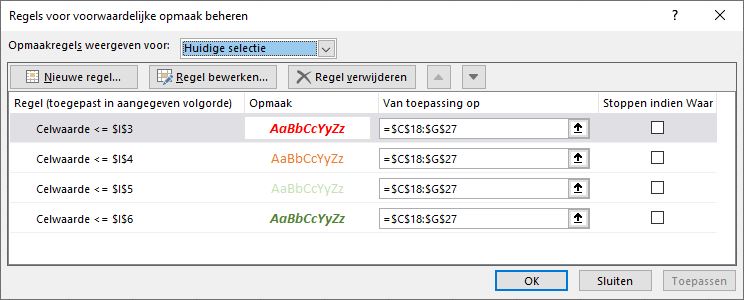
Hé, wat vreemd. Alle cijfers krijgen de goede kleur maar zijn allemaal cursief en vet, terwijl dat in de opmaakregels alleen voor de laagste en hoogste punten is ingesteld. Als deskundige Excel-ler hebt u natuurlijk al gezien hoe dat komt. We nemen als voorbeeld het cijfer 5,6 : dit voldoet niet aan de eerste regel maar wel aan de tweede, dus krijgt het een oranje opmaak. Maar hij voldoet ook aan de derde regel! Dus zou het cijfer een licht-groene opmaak moeten krijgen, maar dat kan Excel niet: én oranje én licht-groen. Het cijfer krijgt de eerste kleur. 5,6 voldoet ook aan regel 4. Donker-groen maken kan Excel niet meer, maar wel cursief en vet.
We moeten ook de laatste kolom binnen de opmaak-regels gebruiken (Stoppen indien Waar). Als een cijfer aan een regel voldoet dan worden de volgende regels niet meer uitgevoerd.
NB1 Het laatste vinkje hoeft niet meer; de opmaak-routine stopt toch al
NB2 bij het opmaken van het ‘kermis-overzicht’ is de stop-optie niet nodig omdat ook hier geldt dat Excel maar één opvulkleur aan een cel kan toewijzen.
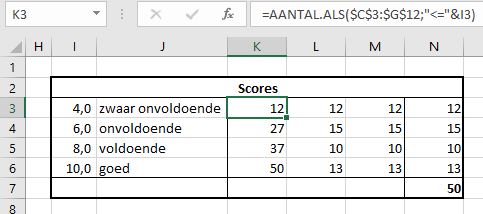
Even genoeg over de opmaak; dit artikel gaat over frequentietabellen. Om de proefwerkresultaten met decimalen in de juiste categorie onder te brengen gebruiken we weer de functie Aantal.Als.
Maar wel iets ingewikkelder dan hierboven: in cel K3 staat de formule =AANTAL.ALS($C$3:$G$12;”<=”&I3) Turf het aantal getallen in het bereik C3:G12, die voldoen aan de voorwaarde dat ze kleiner of gelijk zijn aan de waarde in cel I3.
LET OP de voorwaarde moet een tekst-vorm hebben: dus de tekst <= (zie de “-tekens) wordt met behulp van & samengevoegd met de inhoud van cel I3.
Deze is formule is naar beneden gekopieerd. Helaas, nu hebben we niet de frequenties maar de cumulatieven. Geen nood, in kolom L gaan we de frequenties bepalen. De eerste berekening is oké. Dus cel L3 is hetzelfde als K3. In cel L4 plaatsen we de formule =AANTAL.ALS($C$3:$G$12;”<=”&I4)-L3. Maar die voldoet niet als we die “naar beneden kopiëren”: we hadden =AANTAL.ALS($C$3:$G$12;”<=”&I5)-SOM($L$3:L3) moeten gebruiken.
In kolom M hebben we nog een alternatieve berekening voor de frequenties: M3 is weer gelijk aan K3, in M4 staat de formule =AANTALLEN.ALS($C$3:$G$12;”<=”&I4;$C$3:$G$12;”>”&I3) Dus een Als met 2 voorwaarden, dat kan alleen met de functie AantalLEN.als. Deze formule kan naar beneden gekopieerd worden.
NB wil je toch Aantal.Als gebruiken: in cel M4 had ook de formule =AANTAL.ALS($C$3:$G$12;EN(“<=”&I4;”>”&I3)) kunnen staan. Hierbij zijn met behulp van de functie EN 2 voorwaarden gecombineerd tot 1.
Zoals uit de vorige alinea’s mag blijken is het maken van een frequentietabel met behulp van Aantal.Als niet altijd even makkelijk. We mogen blij zijn dat Excel de functie Interval kent:
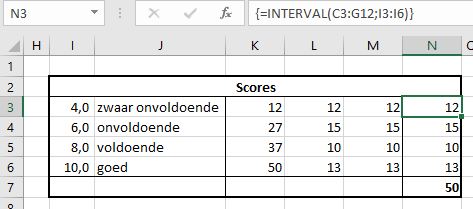
selecteer de cellen N3:N6
tik in de de formulebalk in: =INTERVAL(C3:G12;I3:I6)
druk op Ctrl-Shift-Enter
klaar!
NB1 niet tevreden met de grenzen van de intervallen? Is alles boven 5,5 een voldoende? Wijzig de inhoud van cel I4 in 5,5 en de hele sheet wordt automatisch aangepast. Niet alleen de frequentietabellen maar ook de voorwaardelijke opmaak.
Maar wat gebeurt er als je de 10 in cel I6 wijzigt in 9? Dan worden niet alle punten in de frequentietabel meegeteld; dat is niet de bedoeling. Gelukkig heeft Microsoft daar rekening mee gehouden.
Ter verduidelijking bevat het tabblad FreqTabel2 nog een ander overzicht:
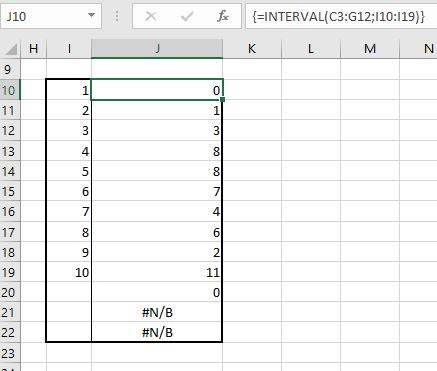
selecteer de cellen J10:J22
tik in de de formulebalk in: =INTERVAL(C3:G12;I10:I19)
druk op Ctrl-Shift-Enter
Bewust is het resultaatbereik groter gekozen dan we gewend zijn; de eerste 10 regels zijn logisch: eerst wordt het aantal proefwerkresultaten kleiner of gelijk aan 1 geturfd (0 dus), dan hoeveel groter dan 1 en kleiner of gelijk aan 2 etc. Maar dan komt er nog een resultaat; in dit geval 0. Excel levert via de Interval-functie altijd één waarde meer dan het aantal gedefinieerde intervallen. Hier wordt geteld hoeveel brongegevens groter zijn dan de hoogst gedefnieerde intervalgrens. Wijzig de 10 in bijvoorbeeld 9,5 en je ziet het volgende resultaat:
De laatste 2 regels laten zien, dat de Interval-functie geen resultaat meer oplevert, dus we hadden hiervoor bij punt 1 beter de cellen J10:J20 kunnen kiezen.
Interval-functie
Laten we de Interval-functie nog eens even verder onder de loep nemen. In het tabblad Interval van het Voorbeeldbestand ziet u weer dezelfde brongegevens staan. Op basis van de 10 intervalgrenzen in kolom I zijn de bijbehorende frequenties in kolom J met behulp van de Interval-functie bepaald, inclusief 1 extra cel (en 2 niet-nuttige cellen).
De frequentietabel in de kolommen L en M laat zien dat de Interval-functie ook werkt wanneer de grenzen in de volgorde hoog-laag staan (in de kolom M staat de formule .
En nog mooier: de intervalgrenzen mogen ook willekeurig door elkaar staan (zie de kolommen O en P)! Maar wanneer zou je zoiets nu doen?
De kolommen R en S laten nog een andere eigenschap van de functie zien: wanneer een interval een tweede keer voorkomt dan wordt de bijbehorende frequentie 0, zodat we geen dubbeltelling krijgen (dit geldt ook als zo’n grens nog vaker voorkomt). Consequentie is wel dat de frequenties van andere intervallen veranderen. En dat is natuurlijk terecht omdat de getallen in kolom R de bovengrens van een interval aanduiden.
Interval-functie 2
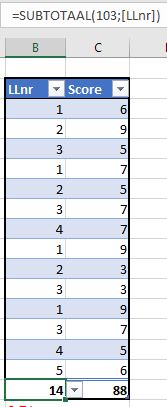
Hiervoor hebben we al regelmatig de functie Interval gebruikt, waarbij de werking (na wat oefening) ‘normaal’ begint aan te voelen.
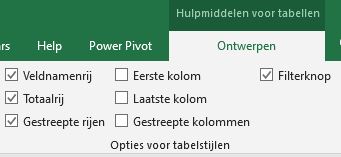
We oefenen nog even met een nieuw voorbeeld (zie het tabblad Interval2 van het Voorbeeldbestand): van enkele leerlingen hebben we scores verzameld. De data zijn vastgelegd in een Excel-tabel met de naam tblLLscore. Het aantal records staat onder de kolom LLnr, daarnaast is het totaal van de scores bepaald met de formule . De twee totalen zijn (bijna) automatisch gegenereerd door in de menutab Hulpmiddelen voor tabellen de Totaalrij te activeren:
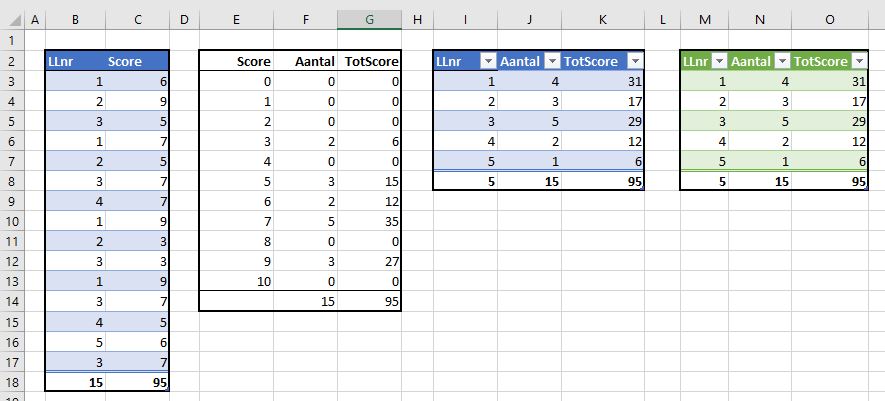
Een overzicht van de verdeling van de scores is nu snel gemaakt:
plaats de scores 0 tot en met 10 in een kolom (hier kolom E)
selecteer daarnaast de cellen in kolom F, tik in de formule =INTERVAL(tblLLscore[Score];E3:E13) en druk op Ctrl-Shift-Enter
in kolom G sommeren we de scores als de score overeenkomt met cel E3, E4 etc.
onderaan sommeren we de resultaten van de kolommen F en G
LET OP de resultaat-tabel in de kolommen E:G kan niet de vorm van een Excel-tabel krijgen; Excel staat een combinatie van zo’n tabel en een matrix-formule niet toe!
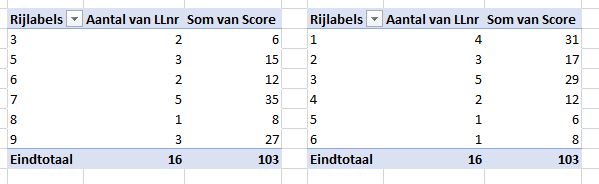
We weten nu hoe de verdeling over de verschillende scores is, maar hoe is de verdeling over de leerlingen? In het voorbeeld is het aantal leerlingen beperkt; we zien in één oogopslag dat alleen de nummers 1 tot en met 5 voorkomen. Maar hoe weet je dat wanneer de bron veel uitgebreider is? Een oplossing is het gebruik van Filter:
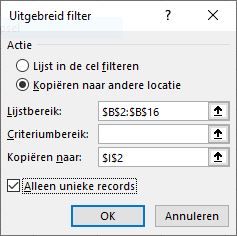
kies in de menutab Gegevens in het blok Sorteren en filteren de optie Geavanceerd
vul het scherm van het Uitgebreid filter in zoals hiernaast
klik op OK
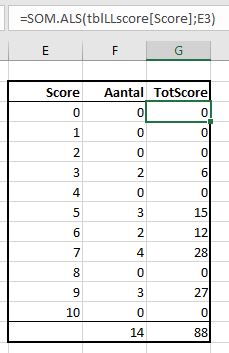
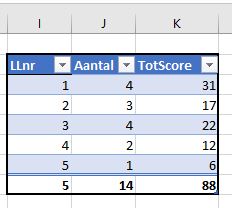
Het klopt, er zijn 5 verschillende leerlingennummers. We hebben de kolom I aangevuld met J en K en daar de Excel-tabel tblLLresult van gemaakt. In kolom J staat de formule =AANTAL.ALS(tblLLscore[LLnr];[@LLnr]) en in K: =SOM.ALS(tblLLscore[LLnr];[@LLnr];tblLLscore[Score])
En de tabel heeft ook een Totaalrij gekregen.
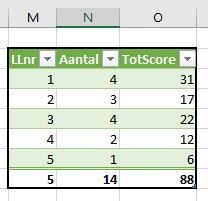
Een andere methode om vanuit de basis tot een leerlingen-overzicht te komen is door het gebruik van Power Query. In de kolommen M:O staat het resultaat daarvan.
Wat gebeurt er als er nieuwe scores bij komen?
selecteer met de cursor cel C16 (de laatste score)
druk op de Tab-toets
de Totaalrij van de tabel verschuift automatisch naar beneden
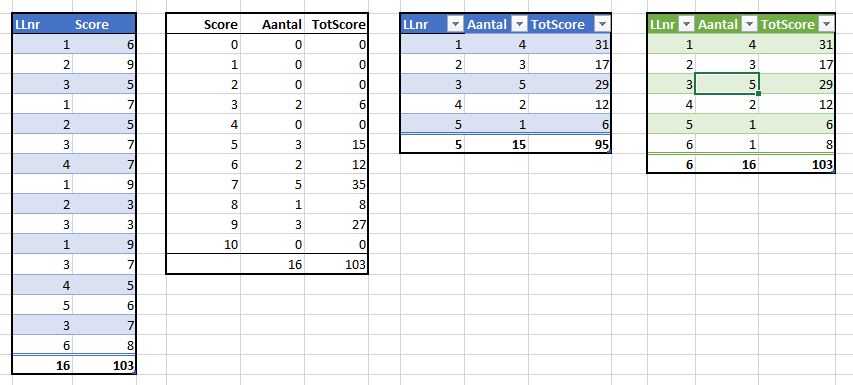
voeg nu nieuwe gegevens toe: leerling 3 heeft een 7 gescoord.
Alle overzichten zijn overeenkomstig aangepast. Het resultaat van Power Query hebben we wel moeten Vernieuwen (rechts klikken op één van de cellen in M:O).
Voeg op dezelfde manier voor leerlingnummer 6 de score 8 toe:
Helaas: ons leerlingenoverzicht is niet meer compleet. We zullen handmatig het leerlingnummer 6 moeten toevoegen om alles weer kloppend te maken. Fijn dat we controle-totalen hebben toegevoegd!
NB misschien toch handiger om voor dit soort overzichten draaitabellen te gebruiken?
Interval-functie-3a
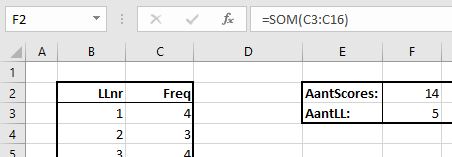
Maar de functie heeft een speciale eigenschap, die goed gebruikt kan worden bij het turven van het aantal unieke gegevens (en dat was uiteindelijk de aanleiding voor dit artikel).
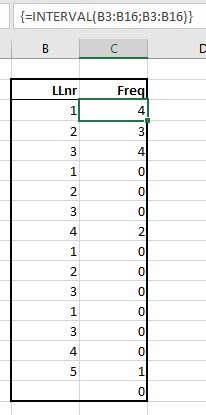
Op het tabblad Uniek van het Voorbeeldbestand hebben we de kolom met leerlingnummers gekopieerd naar kolom B.
Daarnaast hebben we met behulp van de Interval-functie een frequentieoverzicht voor deze leerlingen gemaakt door de Gegevensmatrix en Interval_verw gelijk te maken.
Leerling 1 komt 4 keer voor, de volgende 3 keer etc. Komt het leerlingnummer nogmaals voor dan is de bijbehorende frequentie 0; we krijgen dus geen dubbeltellingen!
Door alle frequenties in kolom C op te tellen weten we dus ook het totaal aantal vastgelegde scores.
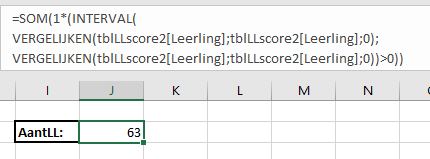
Maar hoe bepalen we nu het aantal unieke leerlingnummers? Met de volgende formule is dit eenvoudig: LET OP om Excel te ‘dwingen’ om de ALS uit te voeren voor alle cellen in C3:C16 moet de formule afgesloten worden met Ctrl-Shift-Enter.
We hebben de frequenties van kolom C niet per se nodig. In cel G3 staat de formule =SOM(ALS(INTERVAL(B3:B16;B3:B16)>0;1;0)) die ook het juiste aantal unieke leerlingen oplevert. NB deze formule kan met Enter afgesloten worden; blijkbaar snapt Excel door het gebruik van Interval dat hij/zij de ALS vaker moet uitvoeren.
Nog korter (in cel H3): =SOM(1*(INTERVAL(B3:B16;B3:B16)>0))
NB1 denk aan de extra haakjes na 1*.
NB2 wil je kijken hoe deze formules werken? Gebruik de optie Formules/Formules evalueren.
Interval-functie-3b
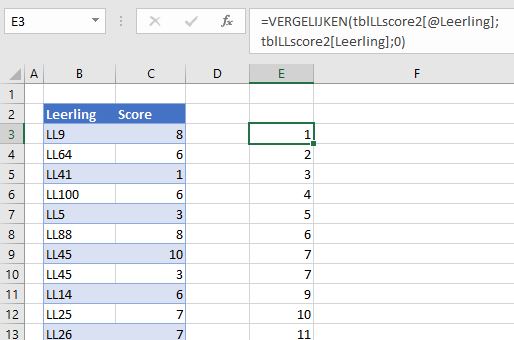
Maar de weg van een Excel-ler is niet altijd even geplaveid, dat weet u ongetwijfeld. Wanneer we niet te maken hebben met leerlingnummers maar met namen (zoals in het tabblad Uniek2 van het Voorbeeldbestand) dan werkt de Interval-functie niet meer!
Gelukkig is daar wat op te vinden. Ter verduidelijking hebben we in kolom E een formule staan met de functie Vergelijken: vergelijk de naam van de leerling in dezelfde regel (zie de @) met ALLE namen in de Leerling-kolom. Als die te vinden is (en dat is hier natuurlijk altijd zo!) dan levert de functie de positie op van deze naam; komt de naam vaker voor dan wordt telkens dezelfde positie opgeleverd. Op deze manier vertalen we de namen dus naar getallen, waarbij dezelfde namen dezelfde getallen opleveren. U voelt het al aankomen: op deze hulpkolom kunnen we wel de Interval-functie loslaten!
We hebben de hulpkolom E niet nodig: zoals te zien is levert de formule in cel J3 direct de juiste informatie.
“Een grafiek zegt meer dan 1000 getallen“. Met deze parafrasering van een bekende zegswijze ben ik het meestal eens, maar soms valt de uitwerking tegen.
In dit artikel wil ik (aan de hand van cijfers over gemiddelde geboortegewichten) met enkele voorbeelden laten zien hoe je een grafiek aan duidelijkheid kunt laten winnen.
Basis-gegevens
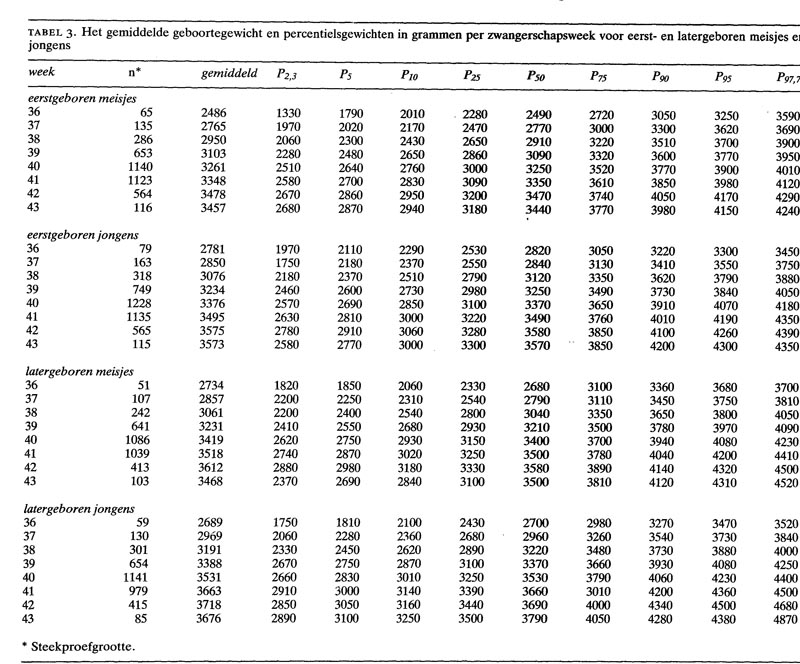
Op zoek naar gegevens over de spreiding van gewichten van baby’s bij hun geboorte kon ik bij het CBS niet veel vinden dat bruikbaar was voor dit artikel. Wel zag ik op de website van het Nederlands Tijdschrift Voor Geneeskunde een onderzoek, waarvan de resultaten wel geschikt waren:
LET OP dit onderzoek stamt uit 1990 (over geboortes in de jaren 70-80); we weten dat het gemiddeld geboortegewicht in de loop van de tijd is gestegen. Volgens het CBS was dit gemiddelde in 2005 ongeveer 60 gram hoger dan in 1990. Wanneer we dit doortrekken zullen de gemiddelde gewichten nu zeker 100 tot 150 gram hoger uitvallen dan de cijfers in bovenstaand onderzoek.
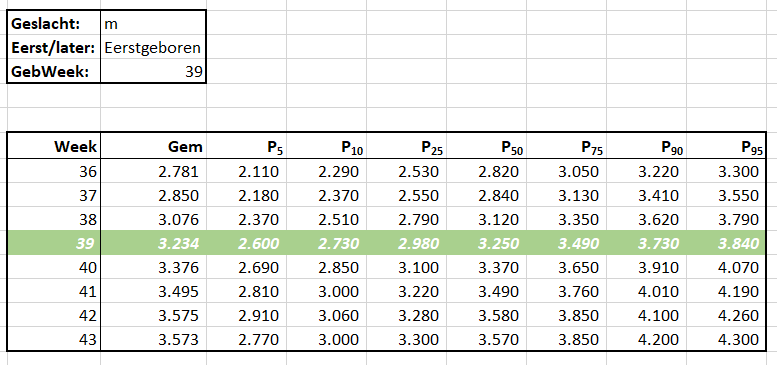
In het tabblad Data van het Voorbeeldbestand zijn deze cijfers overgenomen:
NB1 de cijfers zijn iets anders gerubriceerd, zodat we daar makkelijker een grafiek van kunnen maken.
NB2Week geeft de zwangerschapsduur aan, n het aantal waarnemingen in de betreffende categorie en de percentielkolommen (P5, P10 etc) dat gewicht waarbij 5%, 10% etc van de geboortegewichten kleiner zijn. Dus in de eerste regel: van de 65 meisjes (het eerste kind, geboren in de 36e week) is het gemiddelde gewicht 2486 gram, is 5% lichter dan 1790 gram en 95% lichter dan 3250 gram.
De gegevens zijn opgenomen in de Excel-tabel met de naam tblData.
Grafiek 1
Door de combinatie van 2 soorten geslacht en 2 soorten geborenen kent het onderzoek dus 4 verschillende categorieën.
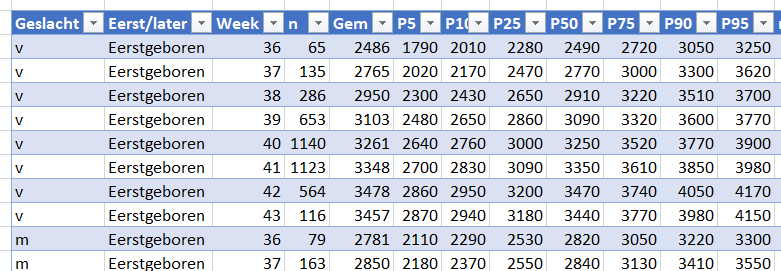
Per categorie kunnen we een grafiek maken, maar in het tabblad Selectie van het Voorbeeldbestand staat een interactieve variant: afhankelijk van de keuze voor Geslacht en Eerst/later wordt de grafiek automatisch aangepast.
NB de cellen C2 en C3 zijn met behulp van Gegevensvalidatie afgeschermd, zodat alleen zinvolle invoer mogelijk is.
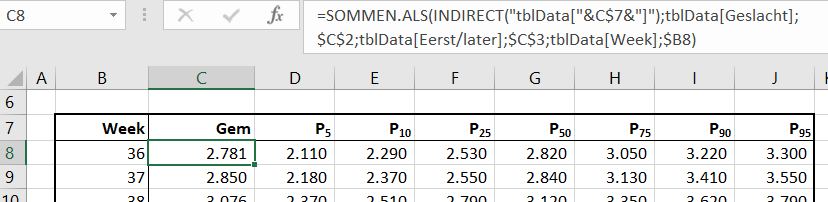
Op basis van deze cellen (C2 en C3) wordt een hulptabel ingevuld. Hierbij wordt de functie SOMMEN.ALS gebruikt:
in de eerste parameter wordt aangegeven waar de gegevens kunnen worden gevonden. In dit geval gebruiken we de functie INDIRECT om de juiste kolom in de tabel tblData te benaderen.
de tweede en derde parameter bepalen het eerste criterium waaraan de gegevens, die we willen ophalen, moeten voldoen (alle regels in de tabel tblData waar in de kolom Geslacht de waarde van cel C2 staat)
via het vierde en vijfde argument wordt de soort geboorte (al dan niet Eerstgeborene) geselecteerd
en het zesde en zevende argument bepalen de juiste week
NB door de 3 criteria voldoet altijd maar 1 cel uit de basis-tabel. Het resultaat is dus geen echte som, maar slechts die ene waarde.
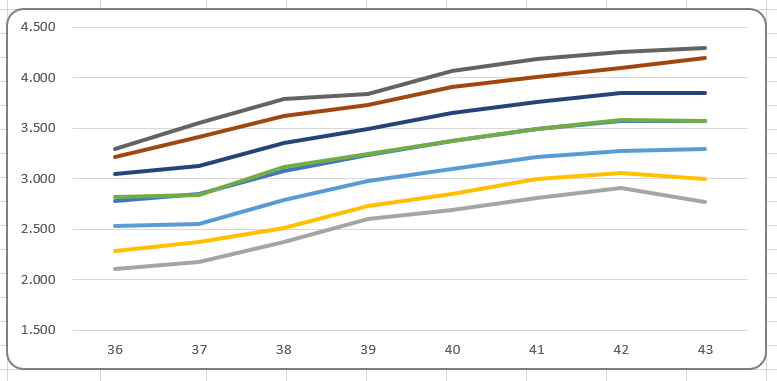
Op basis van deze hulptabel kunnen we snel een grafiek genereren:
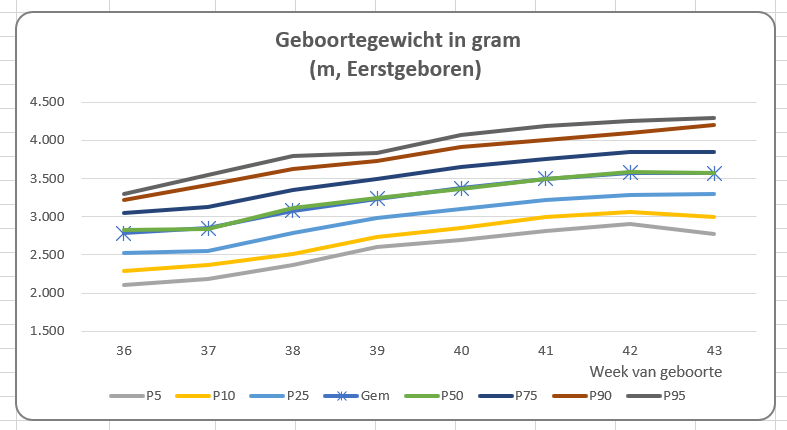
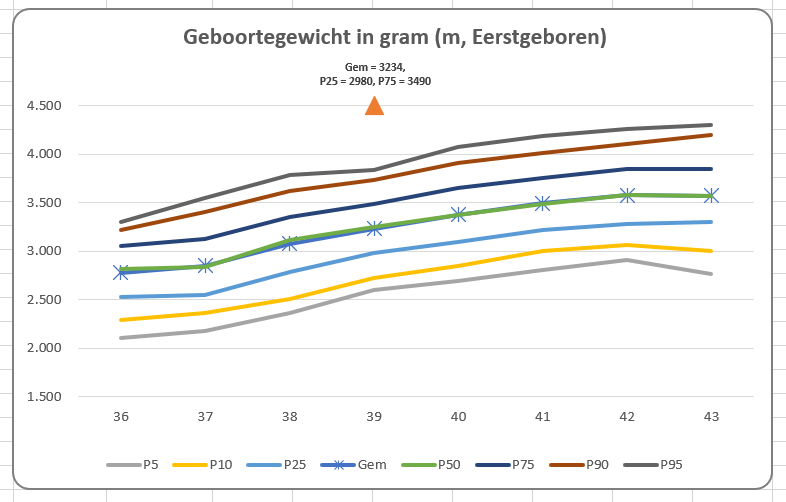
Maar wat zien we hier nu eigenlijk? Met enkele aanpassingen krijgen we een grafiek die beter te begrijpen is:
NB misschien moet de betekenis van P5 etc nog toegelicht worden; dit is afhankelijk van de doelgroep.
Wat is er toegevoegd:
uiteraard een legenda
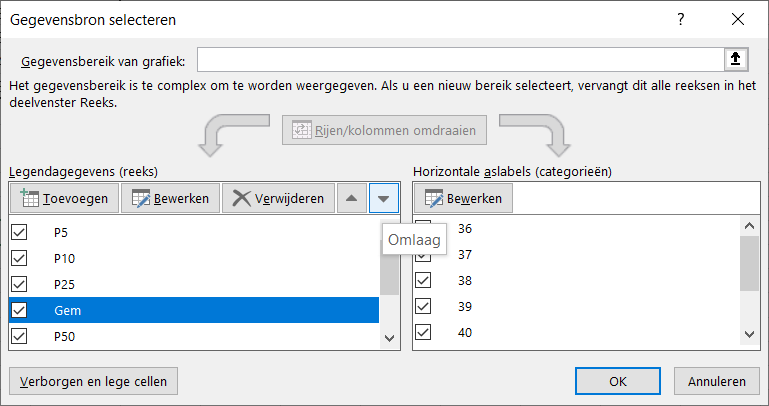
de reeks Gem is naast de P50 gezet: klik rechts in de grafiek, kies de optie Gegevens selecteren en gebruik in het vervolgscherm de pijltjes: NB het gemiddelde en de 50-percentiel zijn in de meeste gevallen ongeveer gelijk aan elkaar
om duidelijker te maken welke lijn het gemiddelde is, heeft deze lijn markeringen gekregen
bij de horizontale as is aangegeven wat de getallen voorstellen
en misschien wel het belangrijkste: de grafiektitel, die aangeeft wat er in de grafiek staat en welke selectie daarbij is gemaakt. In cel L17 van het tabblad Selectie wordt de tekst voor de titel gemaakt: Tussen de &-tekens staan verwijzingen naar de cellen met de namen Geslacht (C2) en Eerst_later (C3). Achter het woord gram staat een ‘harde return’, druk bij het invoeren op Alt-Enter. Maak dan een willekeurige grafiektitel, klik daarin en zet in de formulebalk : =Selectie!L17 LET OP vergeet niet ook de naam van het werkblad in te voeren; je kunt ook na het intikken van het =-teken met de muis op de cel met de tekst klikken.
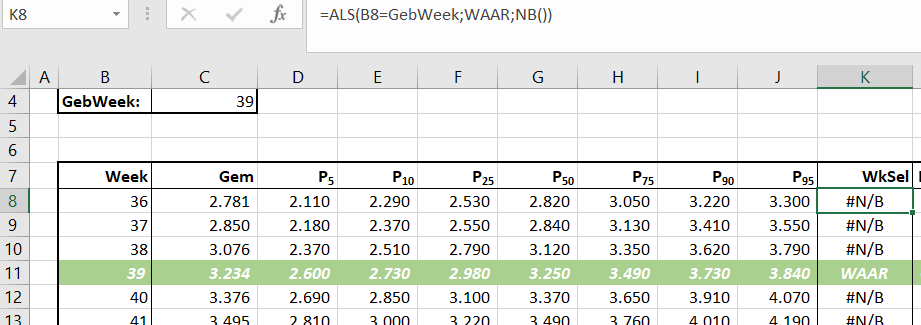
Om de gegevens van een pasgeborene makkelijk te kunnen vergelijken is de invoer nog uitgebreid met een geboorteweek en in de hulptabel wordt dan met Voorwaardelijke opmaak de overeenkomende regel geaccentueerd:
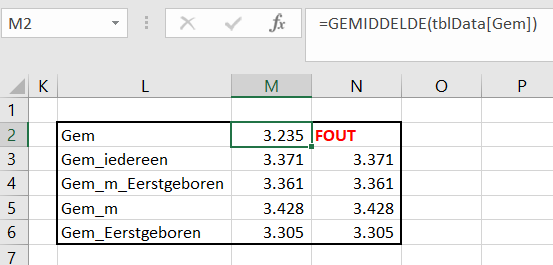
Op het tabblad Selectie van het Voorbeeldbestand worden ook diverse gemiddeldes berekend:
In M2 wordt het gemiddelde bepaald van alle gemiddelde gewichten uit het onderzoek. Maar …. dit is niet juist! Per geboorteweek is het aantal baby’s niet gelijk. De betreffende gemiddelde gewichten moeten gewogen worden met deze aantallen.
Om deze ‘weging’ makkelijk te kunnen uitvoeren is aan de brongegevens een berekende kolom toegevoegd, n*Gem (zie het tabblad Data).
In cel M3 wordt op de juiste manier het gemiddelde bepaald: =SOM(tblData[n*Gem])/SOM(tblData[n]) ofwel de som van alle waardes in de kolom n*Gem in de tabel tblData gedeeld door de som van alle waardes in de kolom n van die tabel.
NB op de CBS-site is te lezen: “In de periode 1989-1991 woog een baby gemiddeld 3 372 gram bij geboorte, in de periode 2004-2006 was dat 3 434 gram.“ Dus het gemiddelde gewicht van 1990 is ongeveer gelijk aan dat uit het onderzoek met geboortes uit 1970-1980.
Afhankelijk van de waardes in de cellen C2 (met de naam Geslacht) en C3 (met de naam Eerst_later) wordt het gemiddelde van die selectie bepaald: =SOMMEN.ALS(tblData[n*Gem];tblData[Geslacht];Geslacht;tblData[Eerst/later];Eerst_later)/ SOMMEN.ALS(tblData[n];tblData[Geslacht];Geslacht;tblData[Eerst/later];Eerst_later) Dus in plaats van een gewone SOM-formule gebruiken we nu SOMMEN.ALS, waarmee we criteria kunnen opgeven voor het optellen.
Op een vergelijkbare manier worden ook de gemiddeldes voor het geselecteerde geslacht en de geselecteerde soort geboorte berekend.
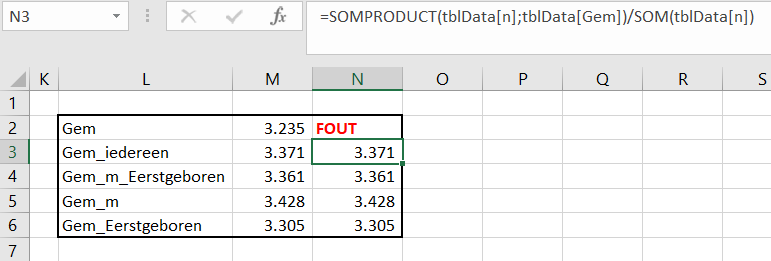
Wil je liever geen hulpkolom (n*Gem) gebruiken dan biedt de functie SOMPRODUCT uitkomst (zie cel N3 in het tabblad Selectie; deze functie vermenigvuldigt alle elementen uit een reeks met de overeenkomende elementen van de andere reeksen en sommeert de resultaten daarvan). Ook de andere gemiddeldes kunnen op een vergelijkbare manier bepaald worden. In cel N4 staat bijvoorbeeld de formule: =SOMPRODUCT(tblData[n];tblData[Gem]; 1*(tblData[Geslacht]=Geslacht); 1*(tblData[Eerst/later]=Eerst_later))/ SOMPRODUCT(tblData[n]; 1*(tblData[Geslacht]=Geslacht); 1*(tblData[Eerst/later]=Eerst_later))
De criteria die we willen meegeven, staan in aparte reeksen; bijvoorbeeld de kolom Geslacht wordt vergeleken met de waarde in de cel Geslacht (dit is cel C2). Dit levert een reeks op van diverse WAAR’s en ONWAAR‘s; door deze met 1 te vermenigvuldigen wordt dit een reeks 1’n en 0‘n.
Grafiek 2
Wanneer je alleen de grafiek toont (en dus niet de hulptabel) dan is het niet altijd even makkelijk om de exacte waardes af te leiden. Daarom zijn in bovenstaande grafiek (zie het tabblad Selectie2 van het Voorbeeldbestand) ook de waardes van het gemiddelde en van de P25 en P75 opgenomen van de geselecteerde geboorte-week. De hulptabel heeft daartoe een extra kolom (WkSel) gekregen:
NB de functie NB() levert als resultaat #N/B. Het voordeel hiervan is dat deze waarde in een grafiek niet wordt weergegeven (zie het artikel Grafiek zonder nullen). In Excel wordt intern WAAR omgezet in de waarde 1. De reeks WkSel is aan de grafiek toegevoegd en aan de secundaire as gekoppeld. Nog een markering toevoegen aan deze ‘lijn’ en op de juiste plaats zien we een signalering. Door ook een kolom Label toe te voegen aan de hulptabel kunnen we deze extra signalering van een Gegevenslabel voorzien. Voor de exacte implementatie, zie het tabblad Selectie2 van het Voorbeeldbestand. Kies je nu een andere geboorteweek (cel C4) dan past de signalering zich automatisch aan:
Grafiek 3
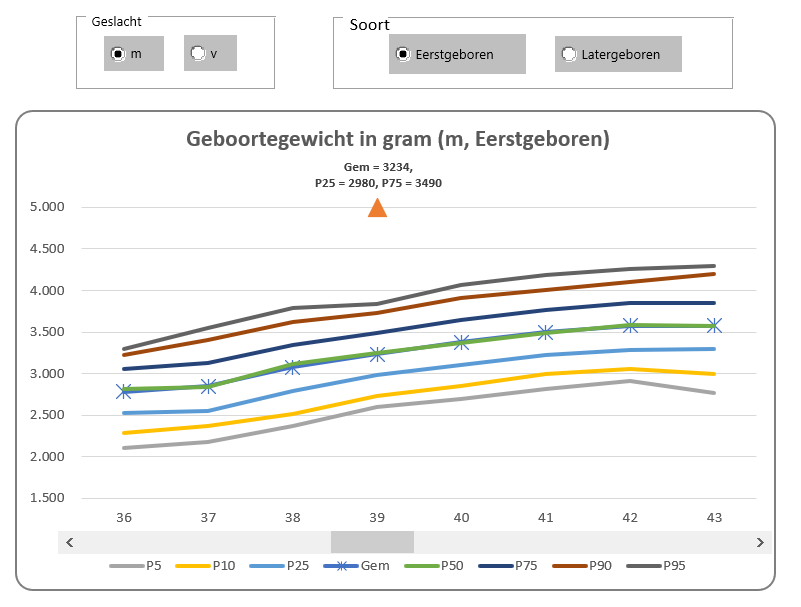
Dit is eigenlijk geen andere grafiek, alleen de manier van selecteren is anders (makkelijker; zie het tabblad Selectie3 van het Voorbeeldbestand).
De hoofdselecties worden gemaakt met behulp van Keuzerondjes, de geboorteweek selecteer je met een Schuifbalk.
Deze voeg je toe via de menutab Ontwikkelaars. In het blok Besturingselementen kies je de optie Invoegen. Selecteer de gewenste optie binnen de Formulierbesturingselementen. Na de selectie kun je zo’n element op de gewenste plaats ‘met de muis tekenen’.
Bij Keuzerondjes is de volgende werkwijze het handigst:
teken één keuzerondje
klik rechts, verander de tekst in m, kies Besturingselement opmaken en maak een koppeling met een cel (in het voorbeeld op tabblad Selectie3 is dat N2)
tik Ctrl-C en ergens anders Ctrl-V, verander de tekst in v
voeg eventueel een groepsvak toe, die je om deze twee keuzerondjes tekent
doe hetzelfde voor het soort geborene; maak daar een koppeling met een andere cel (in het voorbeeld N3)
door een keuzerondje aan te klikken wordt er in cel N2, respectievelijk N3 de waarde 1 of 2 geplaatst; in de cellen daarnaast wordt een ‘vertaling’ gemaakt.
De Schuifbalk is eenvoudiger:
teken deze op de plaats waar je hem wilt hebben (kun je later natuurlijk nog aanpassen)
klik rechts, kies Besturingselement opmaken en maak een koppeling met een cel (in het voorbeeld op tabblad Selectie3 is dat N4). Stel ook de minimum- (in het voorbeeld 36) en de maximumwaarde (43) in.
Grafiek 4
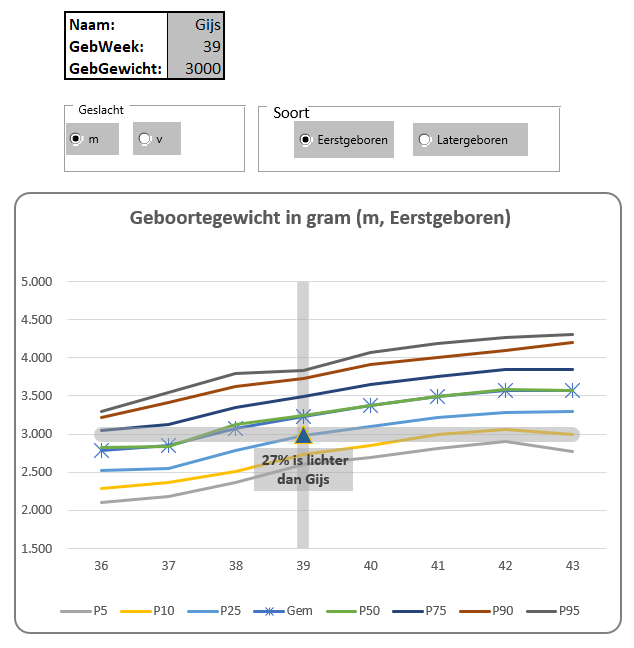
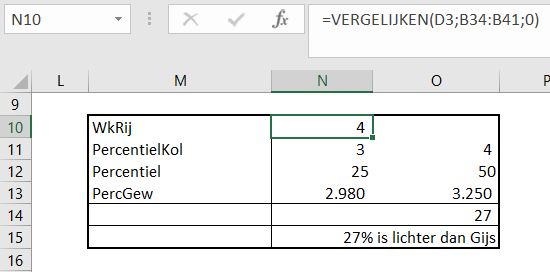
Met behulp van het systeem in het tabblad Vergelijken van het Voorbeeldbestand kun je snel een eigen waarneming afzetten tegen de populatie uit het onderzoek.
Voer de naam, de zwangerschapsduur (in weken) en het geboortegewicht in. In de grafiek is direct de relatieve positie tussen de percentiellijnen te zien. Door wat extra berekeningen wordt via een label ook een schatting voor de absolute positie weergegeven.
Een korte toelichting op de berekening:
zoek eerst de rij op van de geboorteweek (in cel N10 met de functie VERGELIJKEN)
met behulp van deze waarde en de functies VERGELIJKEN en VERSCHUIVING wordt in cel N11 de kolom opgezocht waarvan de score gelijk of kleiner is aan het geboortegewicht uit cel D4. LET OP1 de derde parameter in de VERGELIJKEN-functie is weggelaten; meestal is deze parameter gelijk aan 0 (nul; dan wordt een exacte match gezocht). Vaak zal het gezochte geboortegewicht namelijk niet in de tabel voorkomen. LET OP2 wanneer je de derde parameter weglaat (beter gezegd: als die niet gelijk is aan 0) dan moet de reeks waarin je zoekt, gesorteerd zijn.
in cel N12 bepalen we de percentiel-waarde die bij die kolom hoort
ook het bijbehorende gewicht wordt dan opgezocht in cel N13
in kolom O worden de vorige 2 stappen uitgevoerd voor een hogere percentielkolom
we interpoleren tussen de hiervoor bepaalde waardes om een schatting te krijgen voor het percentiel dat bij het opgegeven geboortegewicht hoort (zie cel O14)
Om de markering op de juiste plaats te krijgen voegen we een nieuwe kolom in de hulptabel toe met voor elke geboorteweek de waarde NB() en alleen in de betreffende geboorteweek komt het geboortegewicht (zie de kolom Verg in de hulptabel op het tabblad Vergelijken).
Net als bij de vorige grafiek moet aan de hierbij behorende ‘lijn’ een markering meegegeven worden, voordat het markeringspunt zichtbaar zal zijn. Geef deze reeks ook een label mee (zie kolom VergLabel).
Als laatste moeten nog de verticale en horizontale lijnen ingevoegd worden:
de verticale kan het makkelijkst door een nieuwe reeks te maken net als in de vorige grafiek (zie kolom VergWk in de hulptabel van het tabblad Vergelijken). Kies als grafiektype een Kolomdiagram en koppel deze aan de secundaire as.
de horizontale lijn wordt geproduceerd door een reeks toe te voegen met voor iedere week dezelfde waarde, namelijk het geboortegewicht uit cel D4.
NB het ‘systeem’ is nog niet fool-proof: vul je een hoog geboortegewicht in, dan zal het zoeken naar het overeenkomende percentiel problemen opleveren.
De Tour de France: ieder jaar kijk ik er weer naar uit, deze keer wat langer dan anders! Een artikel op de site van G-Info met de Tour-gegevens als basis mag dan ook niet ontbreken.
Overal vind je wel standen en overzichten, dus dat gaan we niet overdoen. Het leek me wel aardig om te kijken of we een overzicht kunnen maken van de meest constant-presterende renners. We zullen daarbij allerlei manieren van tellen en zoeken gaan gebruiken, variërend van de functie AANTAL.ALS, de combinatie van Index en Vergelijken tot het gebruik van Gegevensvalidatie en Keuzelijsten.
Doel
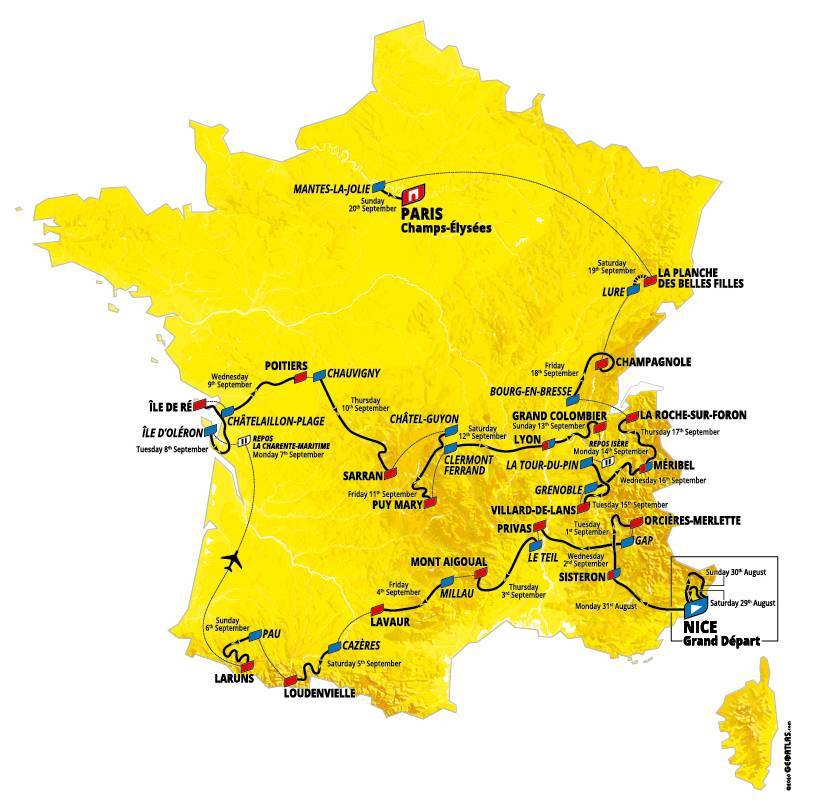
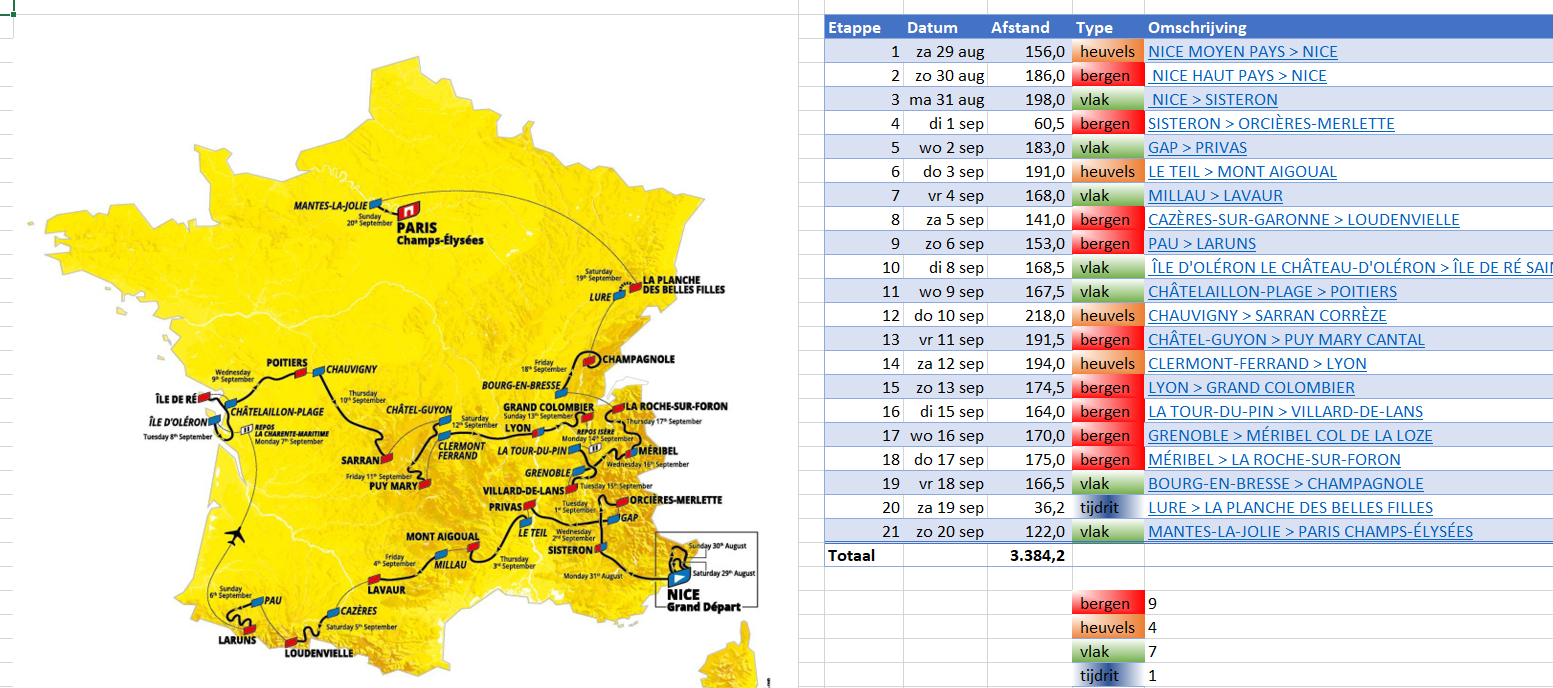
Dit jaar gaat de Tour al direct los: de eerste dagen moeten veel ‘heuvels’ en bergen bedwongen worden (zie het tabblad Etappes in het Voorbeeldbestand). De sprinters hebben dan niet al te veel kans. Misschien vallen er zelfs al renners uit die categorie uit voordat ze aan een massa-sprint kunnen beginnen.
Daarom gaan we in dit artikel eens kijken welke renners zich het meest in de top-10 laten zien: dat noemen we dan maar de meest-constante renners.
Bron-gegevens
Etappes
Onder andere op www.touretappe.nl kun je een overzicht van de etappes vinden. Op het tabblad Etappes van het Voorbeeldbestand heb ik die overgenomen. Alle etappes zijn via de optie Koppeling (rechts klikken op een cel) aan een pagina van die site gelinked, zodat de details van een etappe direct zijn te vinden. Met behulp van voorwaardelijke opmaak zijn de soorten etappes zichtbaar gemaakt. Onderaan wordt het aantal per soort geteld. In cel H26 staat daartoe de formule: =AANTAL.ALS(tblEtappes[Type];G26) Tel het AantalAls in de kolom Type van de Excel-tabel tblEtappes de waarde uit cel G26 (hier Bergen) voor komt. Van de 21 etappes zijn er dus 9 als berg-etappe gekwalificeerd!
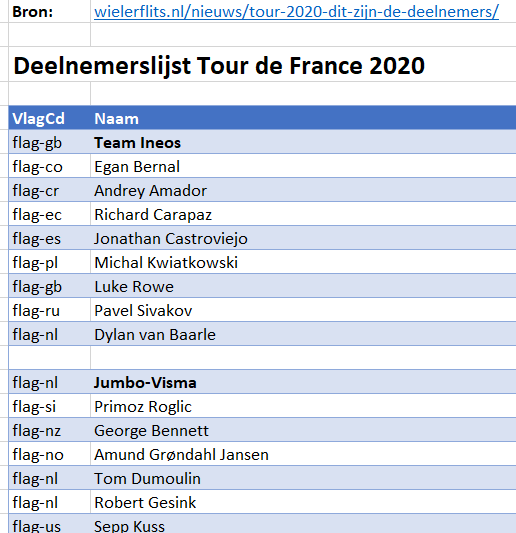
Teams en renners
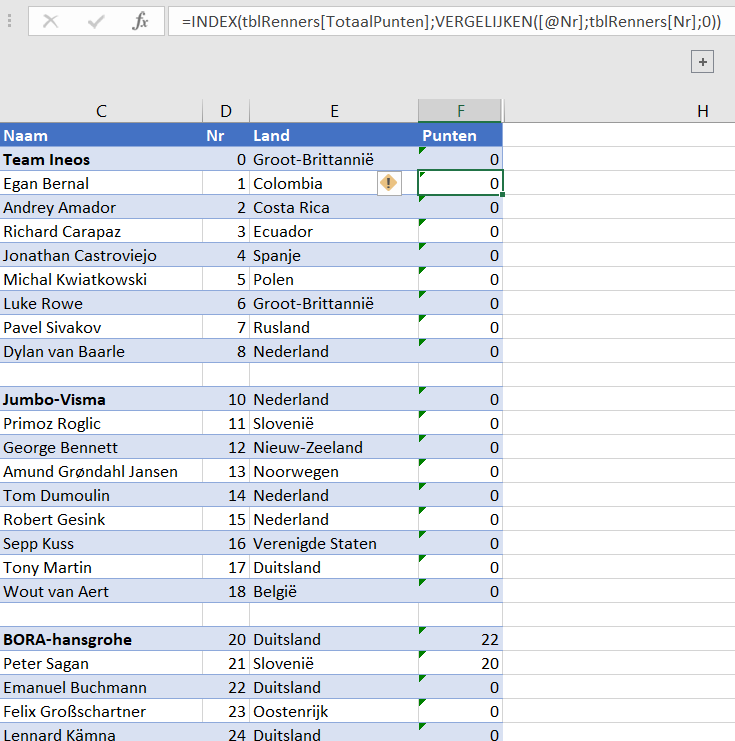
Op het tabblad Teams van het Voorbeeldbestand staat de definitieve deelnemerslijst (in een Excel-tabel tblTeams) zoals die op de site wielerflits.nl is terug te vinden. Op die site zijn de ploegen en renners voorzien van een landen-vlaggetje; bij het plakken in Excel wordt dit vertaald naar een code. Die kunnen we goed gebruiken om ons overzicht te verrijken met echte landnamen.
Aan de tabel tblTeams zijn daarom 2 kolommen toegevoegd:
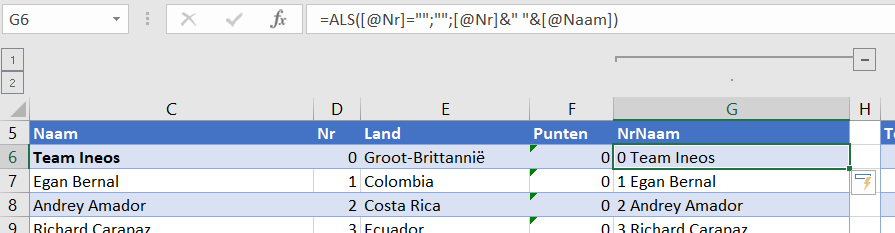
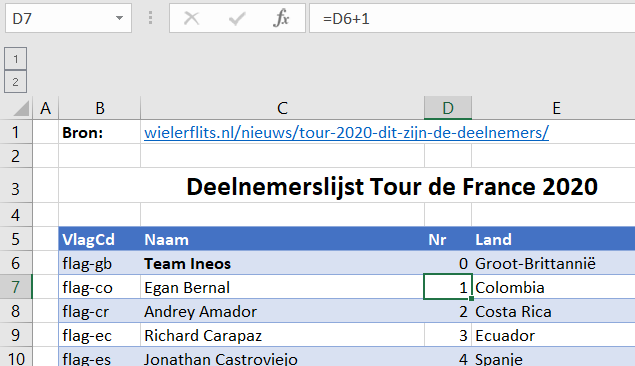
Nr: ieder team en renner krijgt een nummer: het team van de vorige winnaar heeft nummer 0, de kopman van dat team krijgt nummer 1 en de overige renners krijgen hun nummer in alfabetische volgorde.
NB1 is Dumoulin bijgelovig? Hij heeft nummer 13 geruild met de Noor Grøndahl Jansen.
NB2 de kolom Nr kun je handigst op de volgende manier vullen: de eerste cel (D6) krijgt nummer 0 en in de cel daaronder plaatsen we de formule =D6+1. Deze formule doorvoeren naar alle cellen daaronder. Wis dan in de lege regels de cel in kolom D en vul bij het team het volgende tiental in (Jumbo krijgt dan nummer 10, BORA 20 etc).
Land: aan de hand van de vlagcode uit de eerste kolom bepalen we uit welk land het team of renner komt (zie tabblad Landen). Dat zou met VERT.ZOEKEN kunnen, maar we gebruiken liever de universeel toepasbare INDEX-VERGELIJKEN-methode (zie het artikel Zoeken: index en vergelijken, inclusief de avz-truc).
Landen
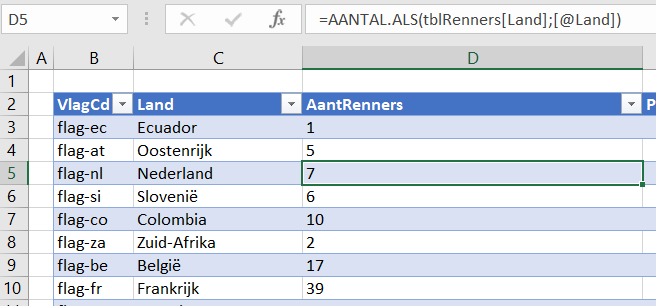
Aan iedere unieke VlagCd uit het tabblad Teams hebben we een land-omschrijving gekoppeld (in de Excel-tabel tblLand van het tabblad Landen in het Voorbeeldbestand).
In de derde kolom van die tabel (AantRenners) bepalen we het aantal renners per land: =AANTAL.ALS(tblRenners[Land];[@Land]) Turf het Aantal Als in de kolom Land van de tabel tblRenners de waarde uit de kolom Land in deze regel (vandaar de @) voor komt.
NB de tabel tblRenners is terug te vinden op het tabblad Renners van het Voorbeeldbestand; zie hierna.
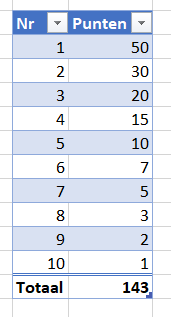
Punten
Op het tabblad Punten van het Voorbeeldbestand hebben we vastgelegd hoe de puntenverdeling voor de eerste 10 renners van iedere etappe moet zijn.
NB1 mocht het eindresultaat straks niet bevallen, dan kunt u natuurlijk proberen uw favoriete renner te helpen door de puntenverdeling aan te passen 😉
NB2 een totaal-regel onder een Excel-tabel wordt automatisch gegenereerd als de betreffende optie is aangevinkt op de menutab Ontwerpen.
Uitslagen
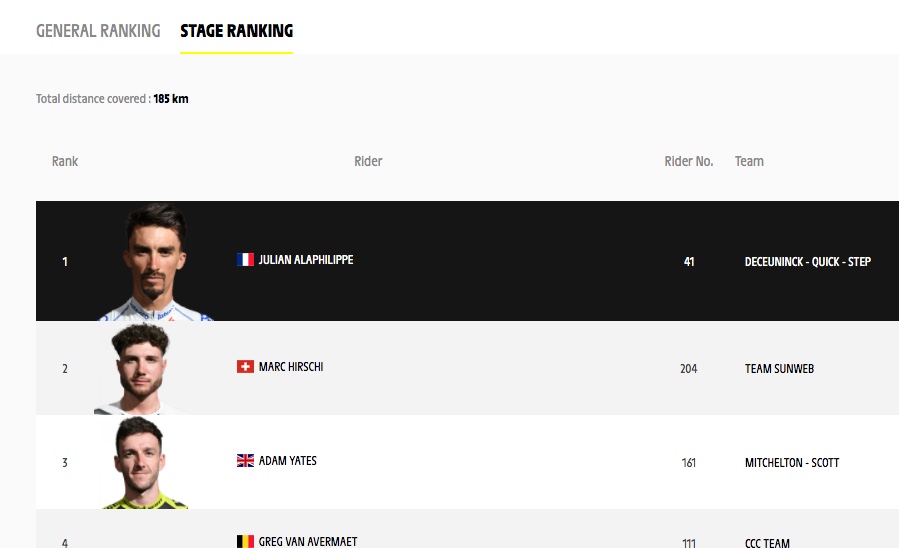
Uitslag 2e etappe op letour.fr
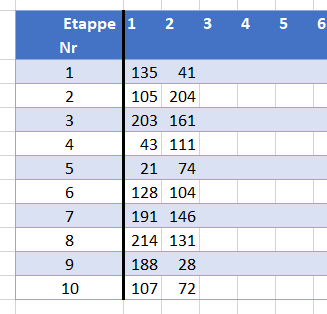
De uitslagen verwerken is heel eenvoudig: vul van de eerste 10 renners hun rugnummers in bij de betreffende etappe (zie het tabblad Uitslagen van het Voorbeeldbestand). Op de officiële tour-site www.letour.fr kun je die rugnummers in de uitslagen vinden.
Maar wat als je alleen maar de namen hebt? (Er zijn waarschijnlijk nog wel meer mensen die dan meteen aan Theo Koomen, of was het Barend Barendse, moeten denken: “Aan namen heb ik niks. Rugnummers moet ik hebben“). In Excel zijn er dan allerlei opties om het rugnummer te vinden. Hier komen er een paar:
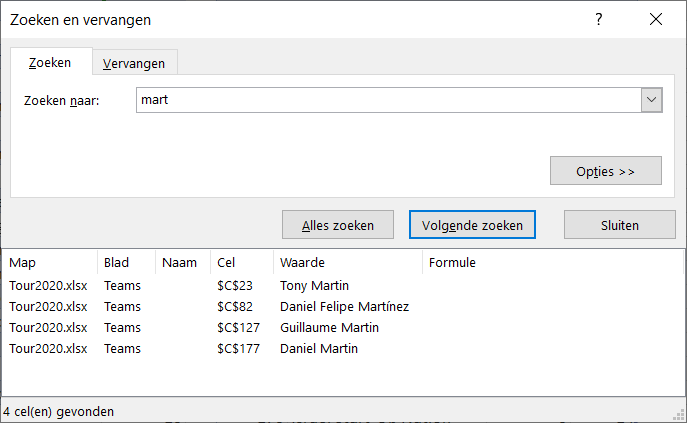
ga naar het tabblad Teams van het Voorbeeldbestand, druk in Ctrl-F, tik een gedeelte van de naam in en klik op Alles zoeken. In het onderste gedeelte van het zoek-scherm komen alle cellen die voldoen. Klik op de gewenste naam en u ziet het rugnummer daarnaast staan.
gebruik Index en Vergelijken: In cel O2 van het tabblad Uitslagen wordt eerst met behulp van de functie Vergelijken gekeken op welke positie in de kolom Naam van de tabel tblTeams de invoer in cel H2 staat. Deze functie kent zogenaamde ‘wildcards’, dus we hoeven maar een gedeelte van de naam in te tikken (de *’s geven aan dat het er niet toe doet, wat er voor en achter de inhoud van cel H2 staat). Daarna wordt deze positie gebruikt om met behulp van de functie Index het betreffende Nr op te halen. Ter controle halen we in cel P2 op een vergelijkbare manier de naam op die hoort bij het rugnummer. LET OPVergelijken geeft de eerste positie terug waarvan de naam voldoet aan de voorwaarde. Is het niet de juiste naam? Tik meer letters in, bijvoorbeeld daniel f om de renner met nummer 76 op te zoeken.
denk je het rugnummer wel ongeveer te weten omdat je het team kent en je weet welk tiental bij deze ploeg hoort: De ploeg van Jumbo-Visma begint met renner 11, Dumoulin zit vooraan in het alfabet (en hij is geen kopman!), dus zal het wel 13, 14 of 15 zijn. Tik het nummer in in cel O4 en je ziet of je goed hebt gegokt.
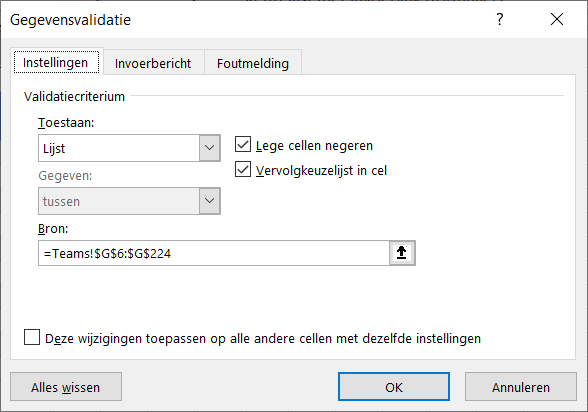
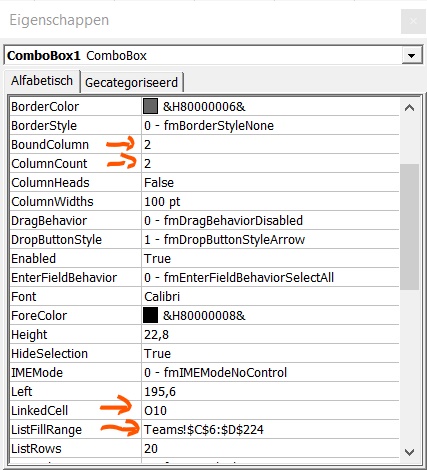
Via de menutab Gegevens in het blok Hulpmiddelen voor gegevens is aan cel H6 een Gegevensvalidatie toegewezen: Alleen gegevens uit kolom G van het tabblad Teams zijn toegestaan. In die kolom G staat voor iedere renner (en team) een koppeling van nummer en naam met een extra spatie daartussen: NB kolom G is standaard niet zichtbaar; via Groeperen kan de kolom ‘ingeklapt’ worden. LET OP je kunt een kolom ook Verbergen (via rechtsklikken op een kolomletter) maar ik ben daar geen voorstander van: het zichtbaar maken is niet zo makkelijk en vaak zie je niet dat er een kolom verborgen is.
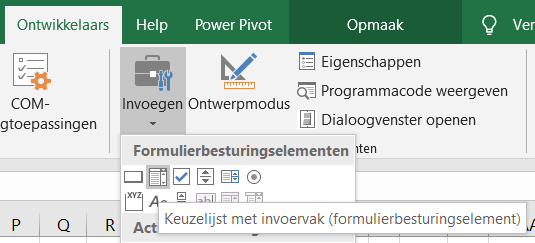
een andere, minder gebruikte, optie is een keuzelijst (met invoervak). Kies in de menutab Ontwikkelaars in het blok Besturingselementen de optie Invoegen.
Klik op de 2e optie binnen de Formulierbesturingselementen.
‘Teken’ nu met de cursor het gebied waar de keuzelijst moet komen.
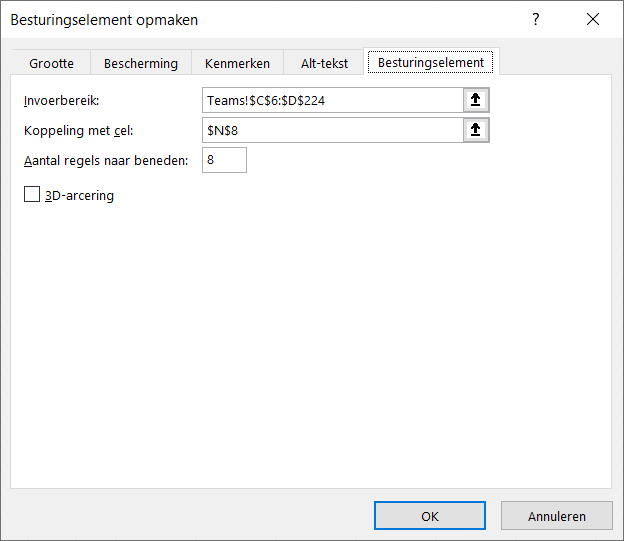
Dan komt de vraag om het besturingselement op te maken: zorg dat in het Invoerbereik de cellen geselecteerd worden met de namen van de renners en dat er een Koppeling komt met de cel naast het invoervak (zie het tabblad Uitslagen in het Voorbeeldbestand).
Wanneer je nu een naam selecteert dan komt in de gekoppelde cel de positie van deze renner in de lijst te voorschijn. Met behulp van de formule =INDEX(tblTeams[Nr];Uitslagen!N8) wordt het rugnummer opgehaald.
een andere keuzelijst maakt gebruik van Active-X; iets ingewikkelder maar wel een stuk flexibeler.
Kies opnieuw in de menutab Ontwikkelaars in het blok Besturingselementen de optie Invoegen. Maar, let op, klik dan op de 2e optie binnen de Active-X besturingselementen. ‘Teken’ weer met de cursor het gebied waar de keuzelijst moet komen. Nu moet je de Eigenschappen aanpassen: klik op de betreffende button in de menubalk en vul de 4 eigenschappen in zoals hiernaast (achter de pijltjes).
LET OP bij het gebruik van Active-X-elementen moet je de Ontwerpmodus uitzetten, wanneer je deze wilt gebruiken (en andersom als je de eigenschappen wilt aanpassen).
Resultaten per renner
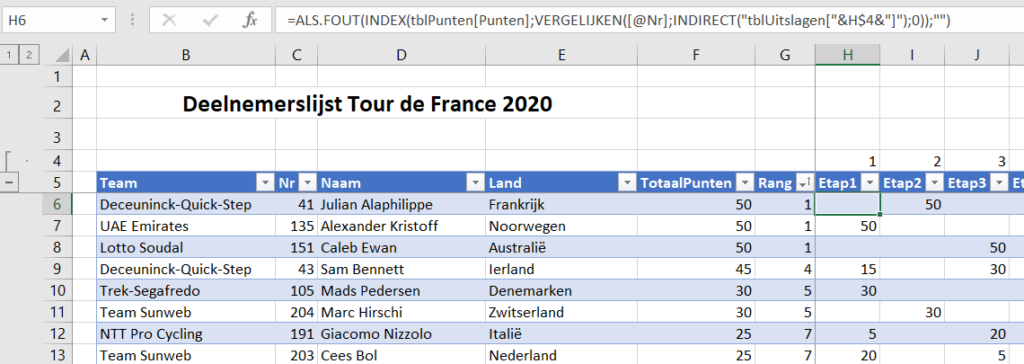
In het tabblad Renners van het Voorbeeldbestand worden de resultaten per renner ‘automatisch’ bepaald; alleen de kolom Nr bevat harde waarden, de overigen worden afgeleid of berekend:
in cel H6 staat de formule: =ALS.FOUT( INDEX(tblPunten[Punten]; VERGELIJKEN([@Nr];INDIRECT(“tblUitslagen[“&H$4&”]”);0)); “”) Aangezien cel H4 de waarde 1 bevat, wordt de 2e parameter binnen de Vergelijken-functie INDIRECT(“tblUitslagen[1]”); Excel vertaalt dit dan naar een bereik van cellen en wel de eerste kolom in de tabel tblUitslagen. De Vergelijken-functie kijkt dan of het rugnummer in die kolom voorkomt. De positie daarvan (1 tot 10) wordt gebruikt om met behulp van de functie Index het daarbij behorende aantal punten te genereren. Als een renner geen top-10-resultaat in een etappe heeft behaald, dan zou er een foutmelding komen; met de functie Als.Fout zorgen we er voor dat in dat geval de cel gevuld wordt met een lege tekst. Deze formule kan naar beneden en rechts gekopieerd, zodat voor alle renners voor alle etappes de resultaten worden bepaald.
in de kolommen Naam en Land worden de gegevens opgehaald uit het tabblad Teams
zo ook voor de kolom Team, behalve dat daarvoor een berekening rond het rugnummer plaats vindt: =INDEX(tblTeams[Naam]; VERGELIJKEN(AFRONDEN.BENEDEN([@Nr];10);tblTeams[Nr];0) ) Het rugnummer wordt dus naar beneden afgerond op het dichtstbijzijnde veelvoud van 10.
in de kolom TotaalPunten wordt het totaal van de renner over alle etappes berekend: =SOM(tblRenners[@[Etap1]:[Etap21]])
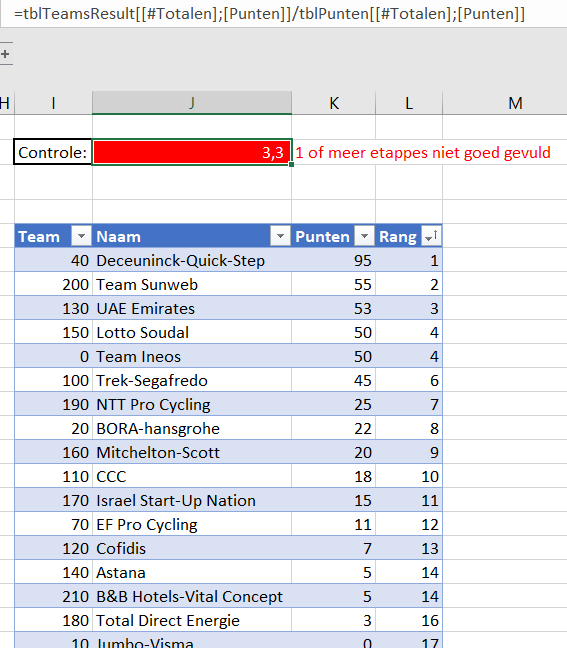
Dan blijft er nog 1 kolom over: Rang. Via de formule =RANG.GELIJK([@TotaalPunten];[TotaalPunten]) wordt in die kolom per renner de rangorde in het totaal bepaald.
Kies met het driehoekje achter Rang de gewenste sortering en u weet welke renner(s) bovenaan staat/staan.
LET OP wanneer er weer nieuwe uitslagen zijn toegevoegd, worden alle formules automatisch herberekend, maar …. de sortering wordt niet vanzelf aangepast. Die moet u zelf nogmaals uitvoeren.
Resultaten per team
In het tabblad Teams van het Voorbeeldbestand wordt op de ondertussen bekende manier per renner de TotaalPunten van die renner opgehaald. Het totaal per team berekenen we met een gewone SOM-formule.
In datzelfde tabblad staat ook een ranglijst van de teams. De formules daarin mogen geen verrassing meer zijn.
Boven die tabel staat een controlegetal: het totaal aantal punten van alle renners gedeeld door het totaal aantal dat per etappe verdiend kan worden. Dit moet een geheel getal zijn. Met voorwaardelijke opmaak krijgt de cel een kleur.
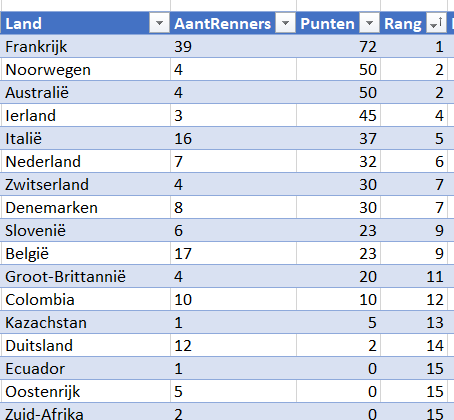
Resultaten per land
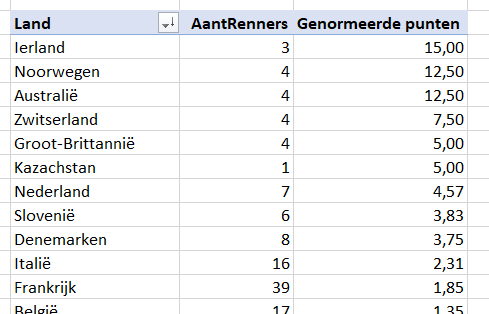
Om het totaal aantal punten per land te bepalen gebruiken we op het tabblad Landen van het Voorbeeldbestand de formule: =SOM.ALS(tblRenners[Land];[@Land];tblRenners[TotaalPunten])
LET OP gebruik de gegevens van tblRenners en niet van tblTeams anders worden ook de totalen van de teams meegeteld.
Frankrijk heeft de meeste renners rond rijden, logisch (?) dat dit land dan bovenaan staat.
We delen het aantal punten door het aantal renners per land en we krijgen een andere ranglijst.
Resultaten per land en team
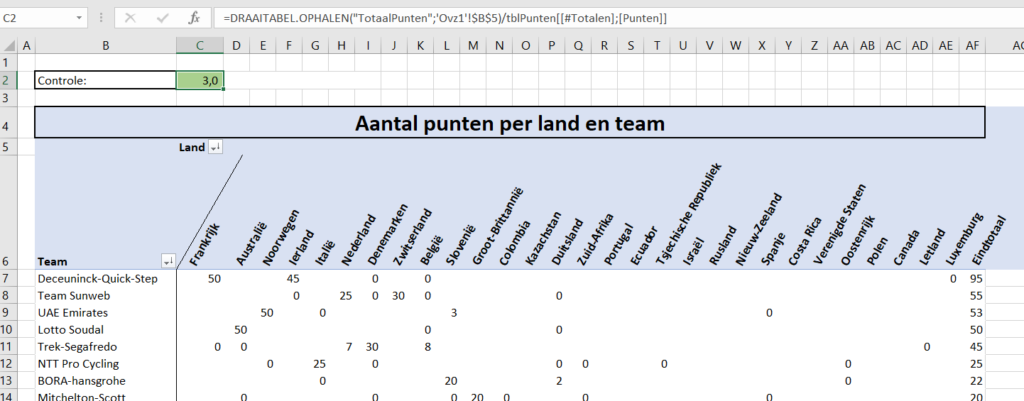
In het tabblad OvzLandTeam van het Voorbeeldbestand staat een draaitabel op basis van de tabel tblRenners. En de rijen én de kolommen worden daarin automatisch gesorteerd (zie ook het artikel Kindernamen).
Bovenin ziet u ook weer een controlegetal; als de uitslagen compleet zijn ingevuld zal dit een geheel getal zijn.
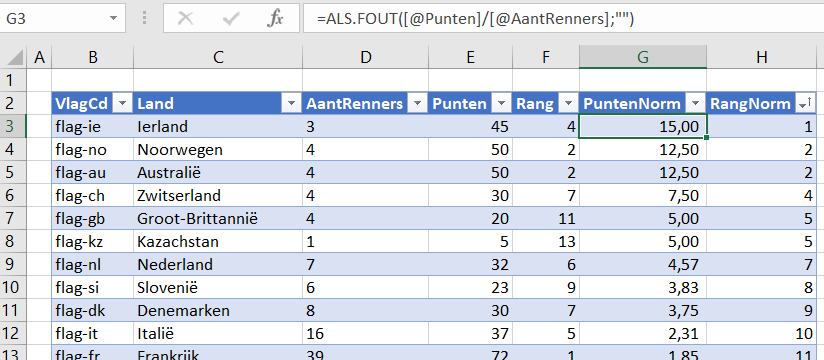
Genormeerde resultaten per land
Het tabblad OvzLandTeam van het Voorbeeldbestand bevat ook een draaitabel, nu op basis van de tabel tblLand.
Per land wordt het aantal renners geteld met daarnaast het aantal genormeerde punten (ofwel het totaal aantal punten gedeeld door het aantal renners).
NB in het hele Tour de France-systeem worden alle overzichten direct geactualiseerd na invoer van een uitslag, omdat die allemaal met formules zijn opgebouwd. Dat geldt niet voor de 2 Ovz-tabbladen: dat zijn draaitabellen en die moeten na het opvoeren van nieuwe uitslagen handmatig Vernieuwd worden (met de muis rechtsklikken op een cel in de draaitabel).
LET OP allebei de draaitabellen dienen Vernieuwd te worden aangezien ze op verschillende bronnen zijn gebaseerd.

 Voorbeeldbestand: RapportageStramien.xlsx
Voorbeeldbestand: RapportageStramien.xlsx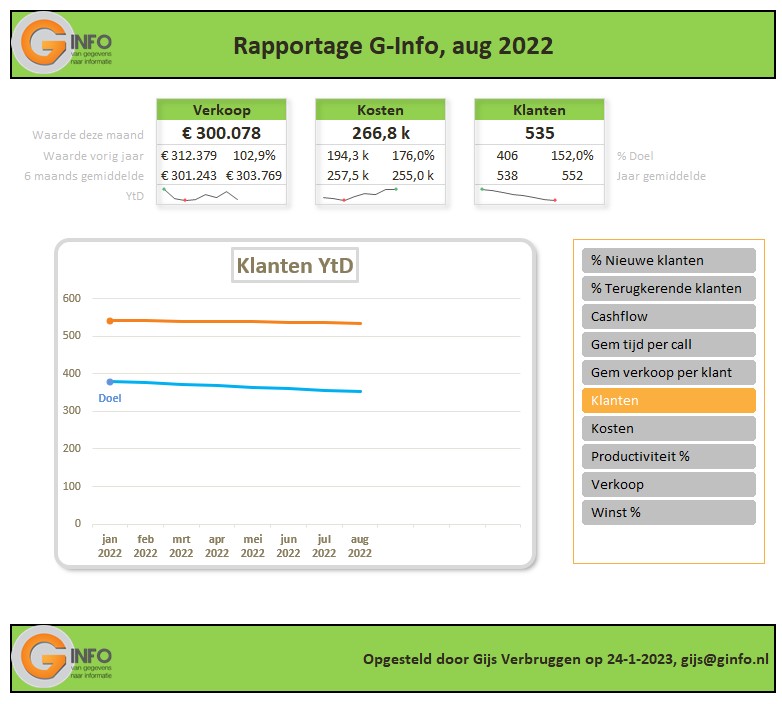









 Via de menutab Gegevens in het blok Hulpmiddelen voor gegevens is aan cel H6 een Gegevensvalidatie toegewezen:
Via de menutab Gegevens in het blok Hulpmiddelen voor gegevens is aan cel H6 een Gegevensvalidatie toegewezen: