
Vanaf 31 maart publiceert het RIVM andere gegevens dan daarvoor. Helaas is het dus niet meer mogelijk om via het voorbeeldbestand de (ver)spreiding van Corona op een consistente manier te volgen.
Op de site https://nlcovid-19-esrinl-content.hub.arcgis.com/ zijn wel nog diverse overzichten en kaarten te vinden.
Corona: de laatste weken beheerst deze crisis niet alleen het nieuws maar ook ons leven. Het einde is nog niet in zicht.
Het zou mooi zijn als we met Excel een bijdrage zouden kunnen leveren aan de oplossing er van.
Helaas, maar wat we wel kunnen, is proberen inzicht te geven in de omvang en voortgang van de besmettingen en overlevenden.
Het RIVM publiceert dagelijkse nieuwe gegevens en ook een kaartje dat de verspreiding van de besmettingen laat zien.
Voor G-Info is dit een goede aanleiding om eens te kijken hoe we van gegevens, die we over Corona kunnen vinden, informatie kunnen maken. Niet voor niets is onze hoofddoelstelling: van Gegevens naar Informatie.
In dit artikel gaan we eerst op zoek naar gegevens rond Corona. Daarna kijken we welke informatie we daaraan kunnen ontlenen. We zullen daarom diverse (vaak met behulp van draaitabellen gemaakte) overzichten bekijken. Als laatste zult u zien dat Voorwaardelijke opmaak heel handig is om snel binnen een grote hoeveelheid gegevens de uitschieters te signaleren.
Brongegevens
In dit artikel focussen we ons op de situatie in Nederland. Het is dan ook logisch dat we terecht komen bij het RIVM. Dit instituut publiceert iedere dag een update van de situatie op hun website rivm.nl.

Op deze site hebben we vanaf de uitbraak in Nederland kunnen terugvinden hoeveel mensen er besmet zijn geraakt en hoeveel daarvan er ondertussen zijn overleden (zie het tabblad DataNed van het Voorbeeldbestand).
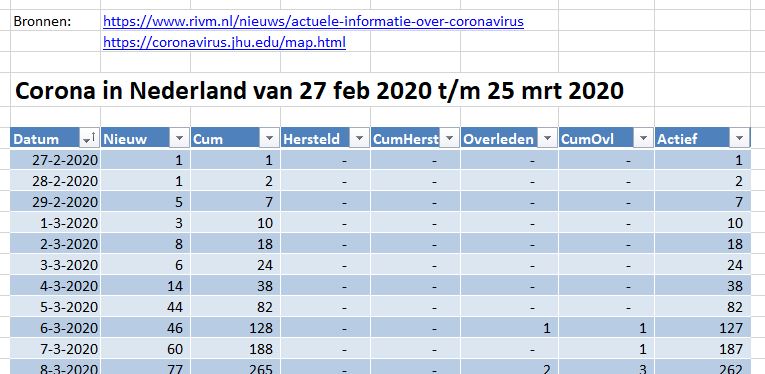
Deze gegevens zijn dagelijks handmatig ingevoerd in een Excel-tabel met de naam tblNed. De kolom Cum bevat een formule, die een lopend cumulatief bepaalt (in cel D9 staat bijvoorbeeld =D8+C9); op een vergelijkbare manier worden ook de 5e en 7e kolom gevuld. In de laatste kolom (Actief) berekenen we het aantal personen, dat op dit moment nog besmet is: =[@Cum]-[@CumHerst]-[@CumOvl].
NB1 het RIVM geeft aan, dat de door hen gehanteerde cijfers geen exacte waarheid weergeven:
“Het werkelijke aantal besmettingen met het nieuwe coronavirus ligt hoger dan het aantal dat hier genoemd wordt. Dit komt omdat niet iedereen met mogelijke besmetting getest wordt, maar vooral patiënten die zo ziek zijn dat ze in het ziekenhuis opgenomen worden en zorgverleners.
Het aantal gemelde patiënten en overleden patiënten kan per dag verschillen om verschillende redenen. Zo zien we dat overleden patiënten niet altijd op dezelfde dag gemeld worden.”
Voor inzicht in de verspreiding lijken ze mij echter significant genoeg.
NB2 gegevens over personen, die hersteld zijn, zijn niet bekend bij het RIVM of worden niet geregistreerd. Op de website van de Johns Hopkins University over Corona worden wel aantal vermeld. Of deze op dit moment de werkelijkheid benaderen betwijfel ik.
NB3 dit artikel is in de loop van enkele dagen geschreven. Aangezien de werkmap in die dagen continu is bijgewerkt kunnen data in de afbeeldingen afwijken van die in het Voorbeeldbestand.
NB4 boven de tabel staat een dynamische kopregel; de inhoud past zich aan aan de datums in de tabel:
=”Corona in Nederland van “&TEKST(MIN(tblNed[Datum]);”d mmm jjjj”)&” t/m “&TEKST(MAX(tblNed[Datum]);”d mmm jjjj”)
Teksten worden aan elkaar gekoppeld met behulp van het &-teken; de minimum- en maximum-datum wordt met behulp van de functie Tekst van het gewenste formaat voorzien.
Als tweede bron is dagelijks een bestand gedownload van de RIVM-site (via het pijltje naast de kaart met gemelde Corona-gevallen).
In het Voorbeeldbestand is dit geautomatiseerd via de Power Query-tabel op het tabblad DagInput. Het bestand bevat het totaal aantal bekende Corona-gevallen per gemeente. Om de resultaten van de gemeentes met elkaar te kunnen vergelijken is dit aantal genormaliseerd (de kolom Aantal per 100.000 inwoners), namelijk door te delen door het aantal inwoners van die gemeente (en met 100.000 te vermenigvuldigen).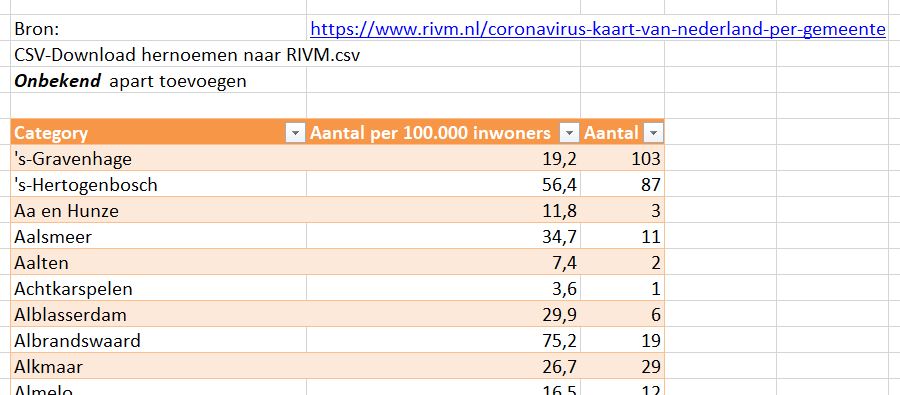
Deze gegevens (zonder de kopregel) zijn iedere dag gekopieerd naar de Excel-tabel tblGem op het tabblad DataGem van het Voorbeeldbestand.
LET OP vanaf 27 maart bevat het bestand van het RIVM 4 namen van gemeenten, die anders gespeld worden dan daarvoor:
Bergen (L.) moet zijn: Bergen (L)
Bergen (NH.) moet zijn: Bergen (NH)
Hengelo moet zijn: Hengelo (O)
s-Gravenhage moet zijn: ‘s-Gravenhage (in de Excel-cel moet dus een dubbele ‘ komen)
De Power Query routine is hier op aangepast, anders met de hand wijzigen in de tabel tblGem.
Een ander bronbestand (zie het tabblad ProvGemeente) is een overzicht van alle gemeentes in Nederland met daarachter het inwoneraantal, een indeling naar klein, middelgroot en groot en de bijbehorende provincie.
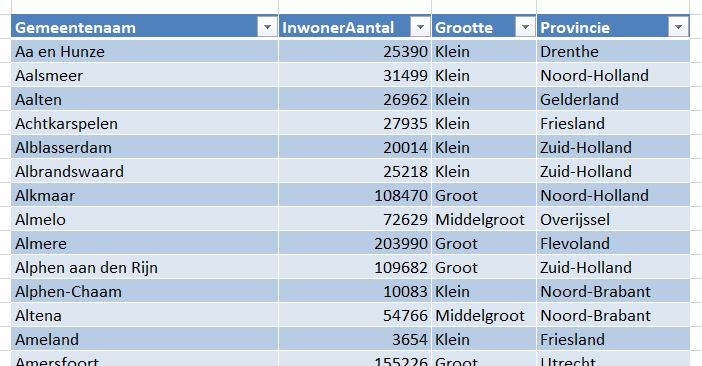
NB De gegevens zijn ontleend aan de website van het Ministerie van Sociale Zaken en Werkgelegenheid (stand van 1 jan 2019).
Overzicht stand van zaken Nederland
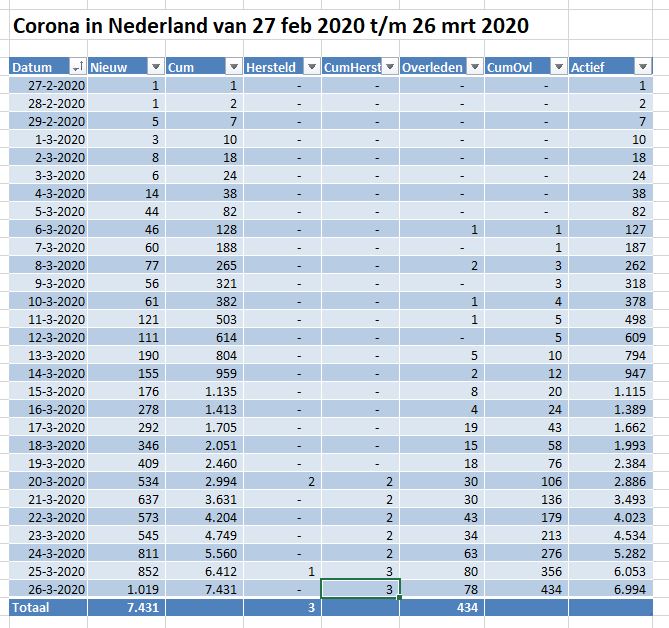
Het overzicht in het tabblad DataNed van het Voorbeeldbestand laat het verloop in de tijd zien van het aantal besmettingen, overledenen en herstelden. Maar hoe de getallen zich tot elkaar verhouden is moeilijk te onderscheiden. Een grafiek is geschikter om dit te laten zien:
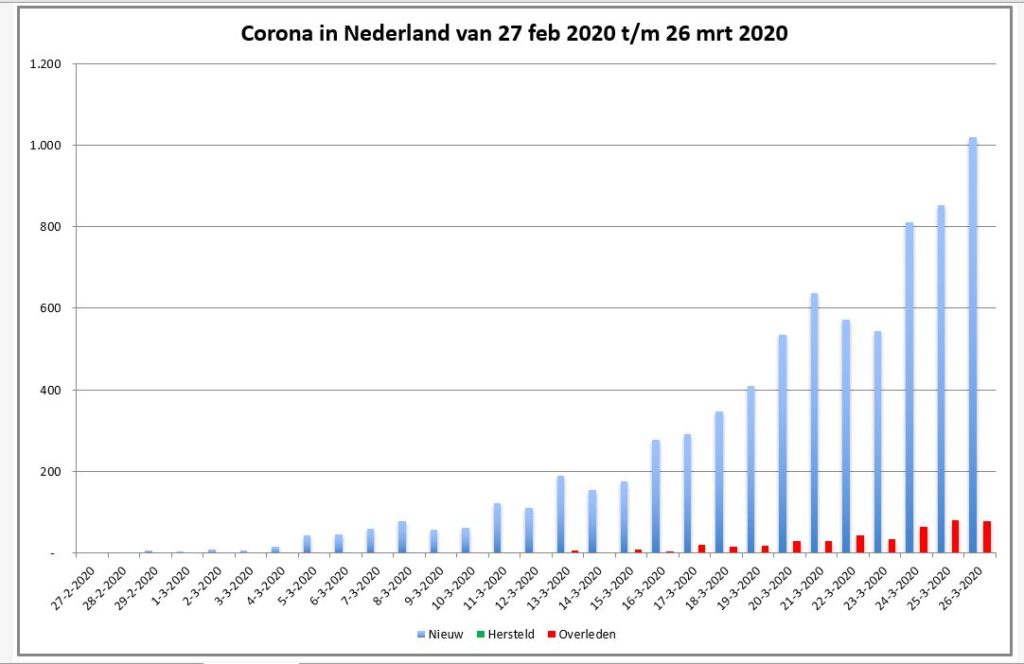
De eerste grafiek (staafdiagram) laat het aantal nieuwe geregistreerde besmettingen, herstelden en overledenen per dag zien (tabblad GrafNed1).
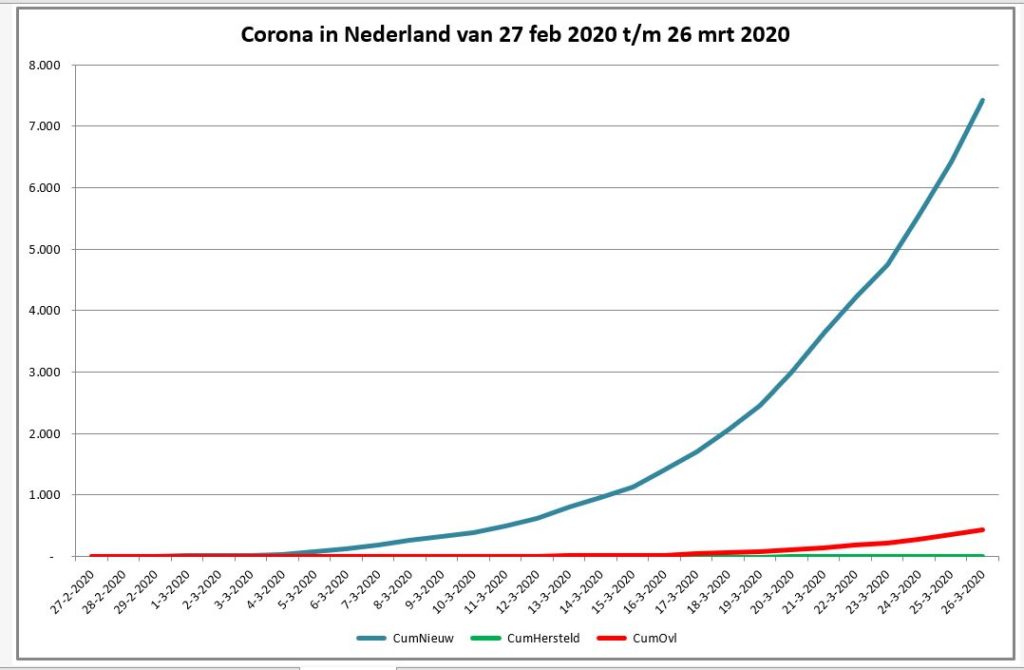
De lijngrafiek (tabblad GrafNed2) toont de cumulatieven daarvan in de tijd.
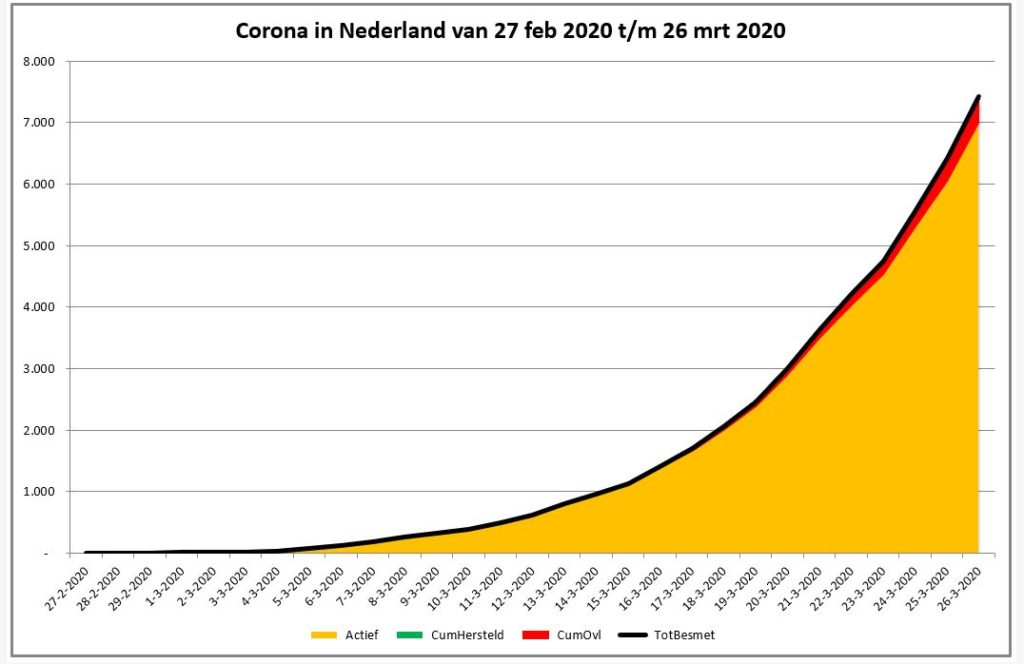
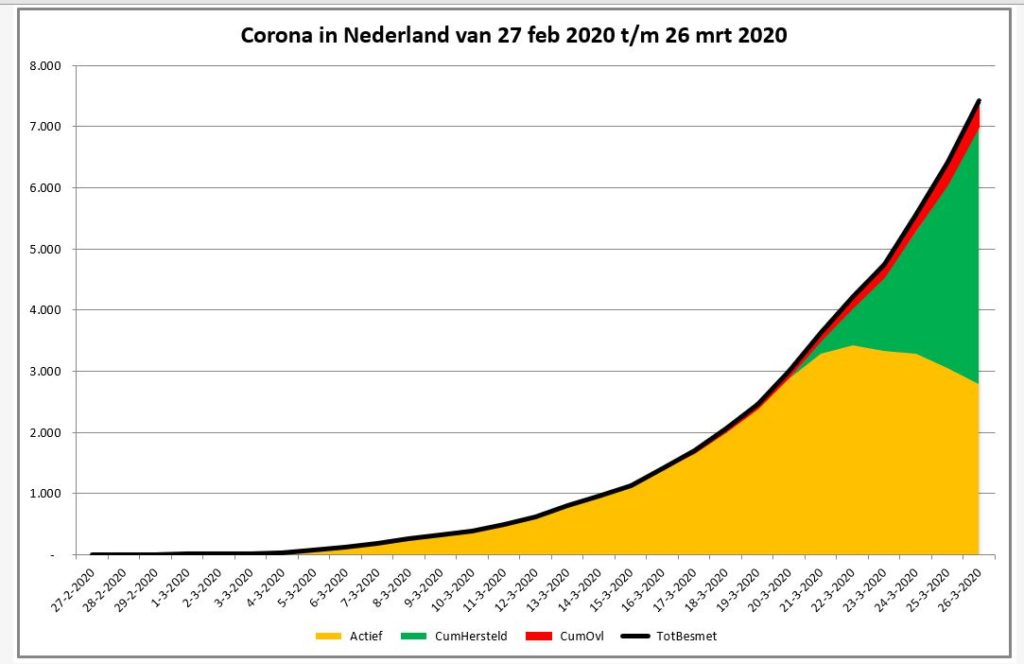
In de derde grafiek (tabblad GrafNed3) wordt door het gebruik van vlakken de opdeling van het aantal cumulatieve besmettingen zichtbaar gemaakt.
NB1 bij het schrijven van dit artikel was het aantal herstelden nog gering (volgens de gehanteerde bronnen); resultaten daarvan zijn in de grafieken dan ook nauwelijks/niet zichtbaar.
NB2 in de laatste grafiek moet het oranje vlak (de actieve besmettingen) in de loop van de tijd steeds meer de veel besproken ‘uitgevlakte’ curve laten zien. Het groene vlak (herstelden) zal steeds groter moeten worden. Een fictief voorbeeld staat hiernaast.
Overzicht per gemeente, basis
Zoals bij de bronnen aangegeven bevat het tabblad DataGem van het Voorbeeldbestand de totaal-aantallen geregistreerde besmettingen per gemeente per dag.
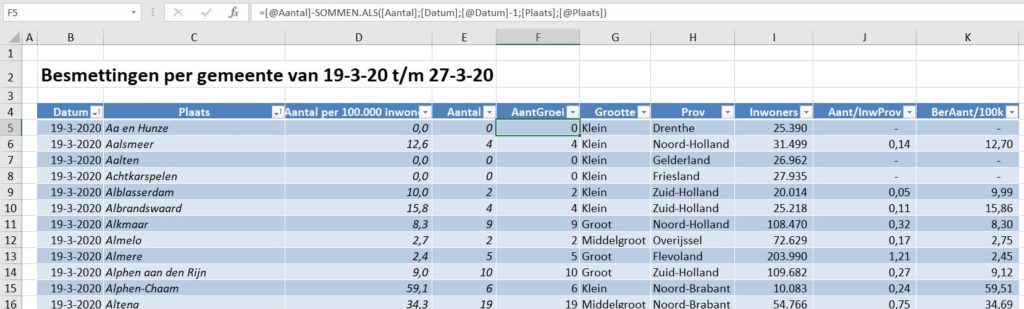
Om hierna diverse analyses op de gegevens uit te kunnen voeren zijn de brongegevens in deze tabel verrijkt:
- in kolom F wordt de dagelijkse groei van het aantal voor een gemeente berekend:
=[@Aantal]-SOMMEN.ALS([Aantal];[Datum];[@Datum]-1;[Plaats];[@Plaats])
Trek van het Aantal in een bepaalde rij het Aantal af van de vorige dag bij die gemeente.
NB SOMMEN.ALS telt alle Aantallen op waarvan de Datum gelijk is aan de Datum in die regel minus 1 en waar de Plaats gelijk is aan de Plaats in die regel. In principe is er altijd maar 1 geval, die aan deze voorwaarden voldoet. - de indeling van de gemeente naar grootte wordt in kolom G bepaald door dat gegeven op te zoeken in tblGemProv in het tabblad ProvGemeente:
=INDEX(tblGemProv[Grootte];VERGELIJKEN([@Plaats];tblGemProv[Gemeentenaam];0)) - op een vergelijkbare manier worden in de kolommen H en I respectievelijk de provincie en het aantal inwoners van een gemeente opgehaald.
- de genormaliseerde aantallen per gemeente (uitgedrukt in Aantal besmettingen per 100.000 inwoners) wordt door het RIVM aangeleverd; kolom D.
Om provincies goed met elkaar te kunnen vergelijken moeten ook de aantallen per provincie worden genormaliseerd. In kolom J wordt de benodigde berekening uitgevoerd:
=[@Aantal]/ INDEX($N$5:$N$16;VERGELIJKEN([@Prov];$M$5:$M$16;0)) *100000
NB de kolommen M en N bevatten een draaitabel die het aantal inwoners per provincie bepaald.
Overzicht per provincie (1)
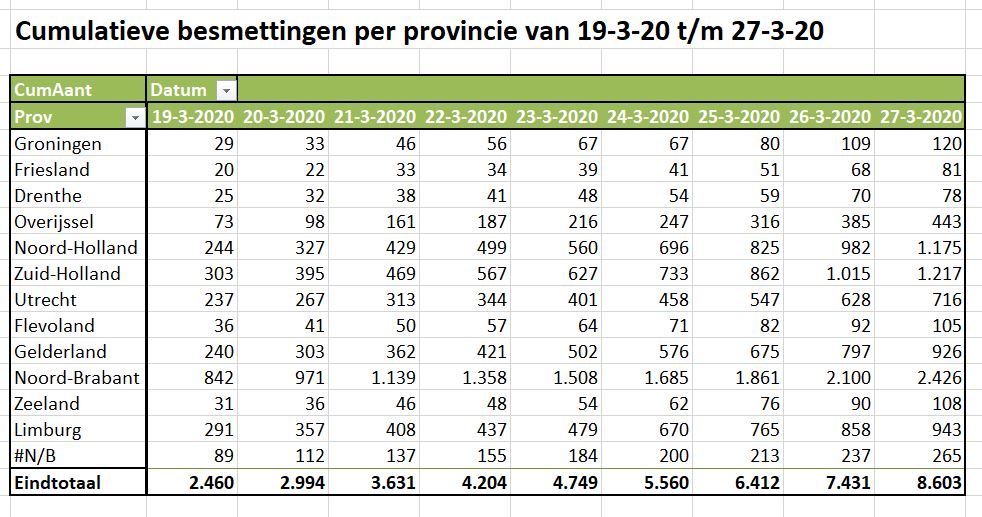
Waar in Nederland zitten de meeste Corona-gevallen? Met behulp van een draaitabel kunnen we snel een overzicht per provincie maken (gerangschikt van noord naar zuid; zie tabblad OvzProv1 van het Voorbeeldbestand):
Uit de bijbehorende draaigrafiek kunnen makkelijker conclusies getrokken worden (tabblad GrafProv1):
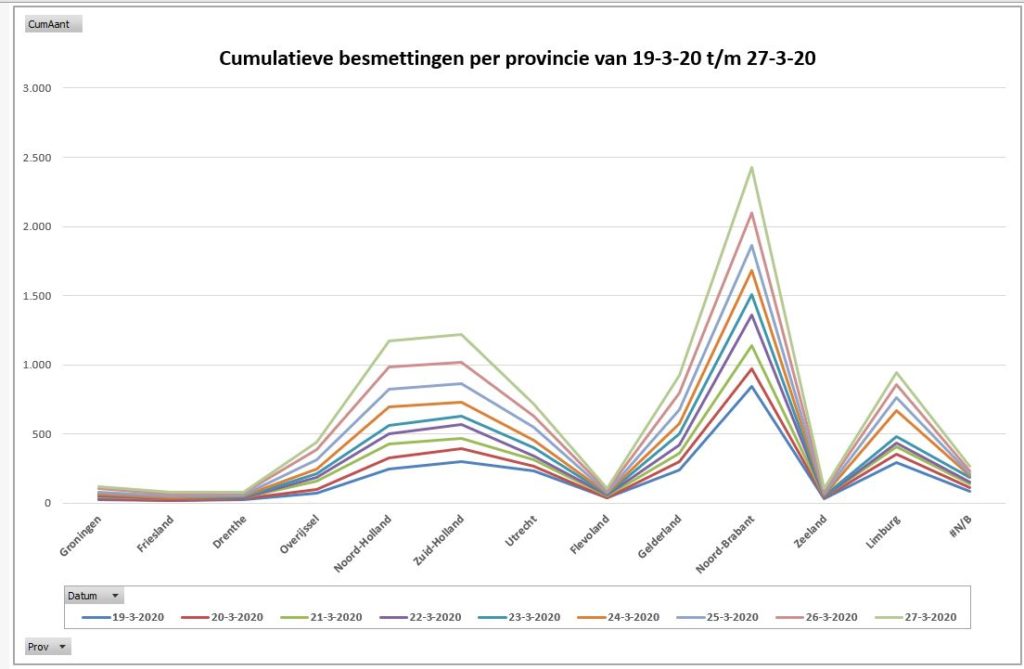
- in absolute zin is het aantal besmettingen vanaf het begin (van de registratie in dit Excel-bestand, 19 maart) het grootst in Noord-Brabant, gevolgd door Noord- en Zuid-Holland en Gelderland en Limburg.
- Deze laatste provincie kende een relatief grote groei op 24 maart.
- De hoop dat de groei in Brabant zou gaan afvlakken zien we nog niet terug (dan zouden de lijnen daar steeds dichter bij elkaar moeten gaan liggen; op 27 maart zien we zelfs weer een groei) .
- Ook neemt de groei in Noord- en Zuid-Holland toe.
- In Limburg blijft de groei de laatste dagen gelijk.
- De noordelijke provincies en Flevoland en Zeeland lijken nog weinig ‘geraakt’.
LET OP wanneer er gegevens voor een nieuwe datum zijn toegevoegd dan moet de draaitabel vernieuwd worden. Aangezien alle draaitabellen in deze werkmap dezelfde bron gebruiken (tblGem) worden al deze draaitabellen dan tegelijkertijd ververst.
Overzicht per provincie (2)
Wanneer we eenzelfde draaitabel sorteren van ‘hoog naar laag’ op de gegevens van de laatste dag (tabblad OvzProv2) dan ziet de bijbehorende draaigrafiek er als volgt uit (tabblad GrafProv2):
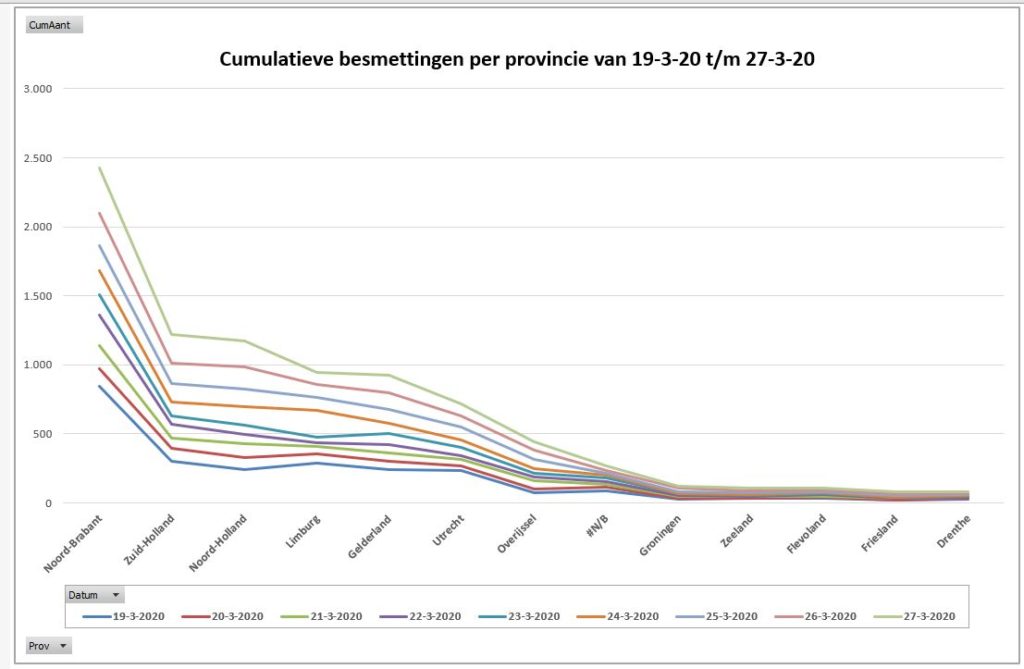
- Noord- en Zuid-Holland gaan ongeveer gelijk op
- Gelderland ‘haalt Limburg langzaamaan in’
Overzicht per provincie (3)
Maar als je provincies echt met elkaar wilt vergelijken moet je ook de verschillen in grootte daarbij betrekken. Op het tabblad OvzProv3 is daarom een draaitabel gemaakt van de genormaliseerde aantallen:
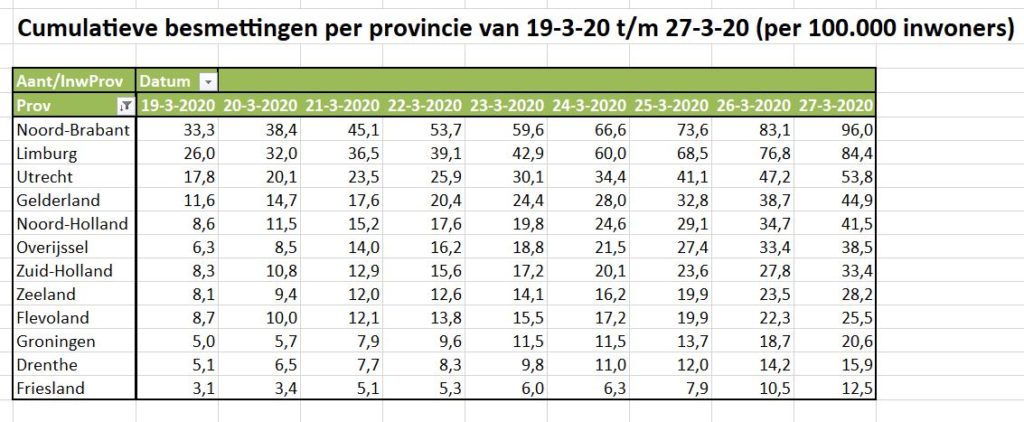
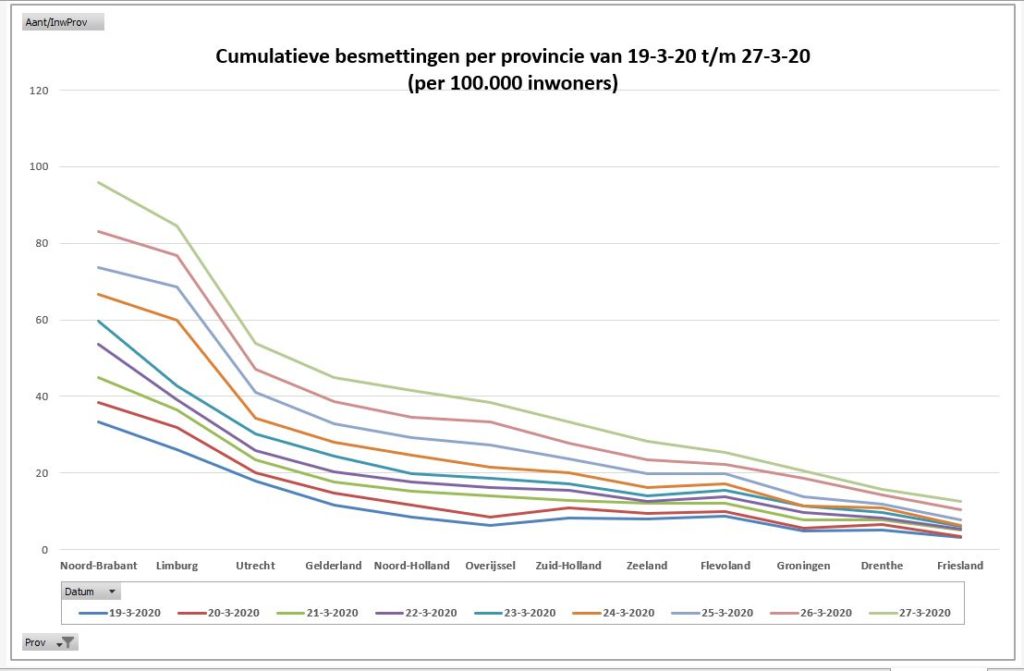
- relatief zijn er dus in Brabant en Limburg de meeste besmettingen (toch gerelateerd aan Carnaval?)
- we horen weinig over Utrecht, maar die komt in dit overzicht op de 3e plaats
- Noord-Holland heeft relatief duidelijk meer besmettingen dan Zuid-Holland
- de provincie Zeeland kende in het begin relatief evenveel besmettingen als Zuid-Holland; deze laatste vertoont echter in de loop van de tijd een grotere groei.
- maar het virus moet ook in de ‘kleinere’ provincies niet onderschat worden
Overzicht per gemeente (1)
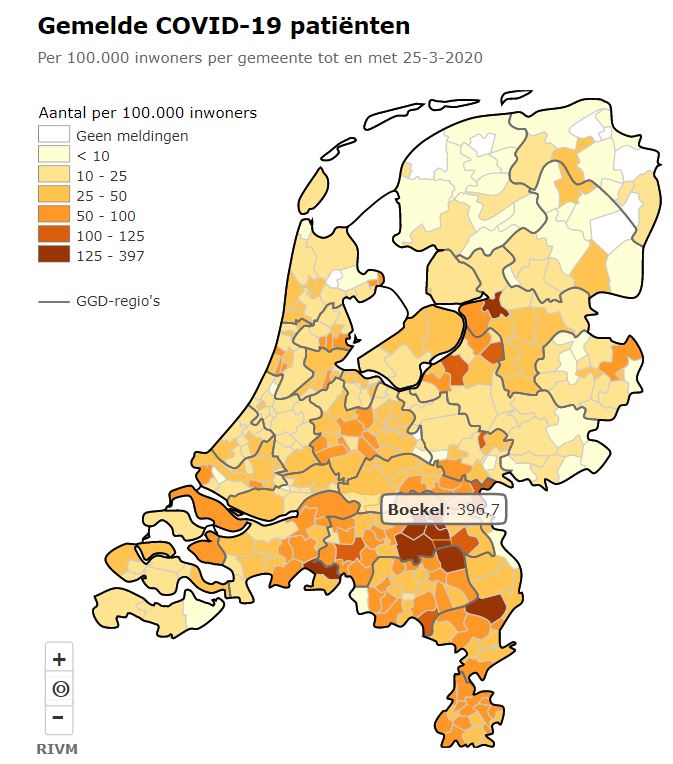
Voor diegene die nog wat ‘dieper willen kijken’ kunnen we op basis van de RIVM-cijfers op gemeenteniveau inzoomen. Het mooiste is natuurlijk om dit op een kaart zichtbaar te maken. De stand van 24 maart hebben we met behulp van Datawrapper.de ‘vertaald’:

‘Uiteraard’ komen daarmee de grote plaatsen boven drijven. Dat is ook de reden, dat het RIVM vanaf het begin een genormaliseerde kaart heeft getoond. Dat hebben we voor 24 maart ook gedaan:
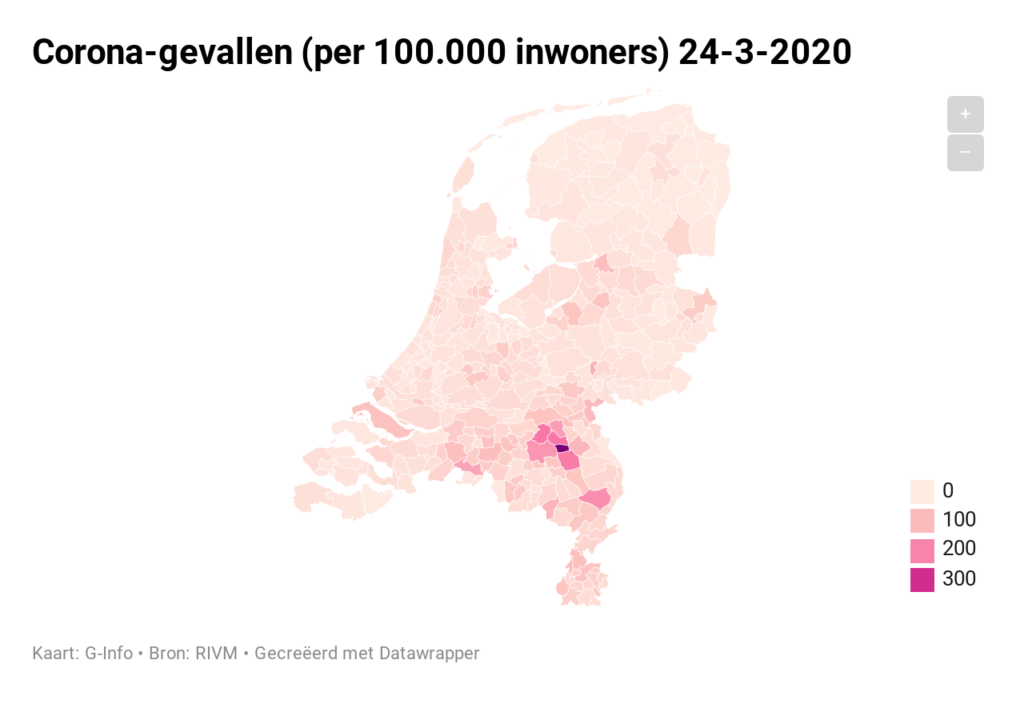
Op deze manier is beter te onderscheiden waar het virus zich vooral heeft verspreid. Naast de bekende plaatsen in Oost-Brabant zien we ook mogelijke haarden in Alphen-Chaam en Peel en Maas.
Aangezien bovenstaande methode nogal bewerkelijk is, zullen we voor een verdere detaillering gebruik maken van draaitabellen.
Op het tabblad OvzGem1 van het Voorbeeldbestand ziet u per provincie de verdeling naar gemeente. Om goed zicht te krijgen op de groei per dag kunt u (handmatig) een sortering aanbrengen; in het voorbeeld is dit op de laatste kolom uitgevoerd.
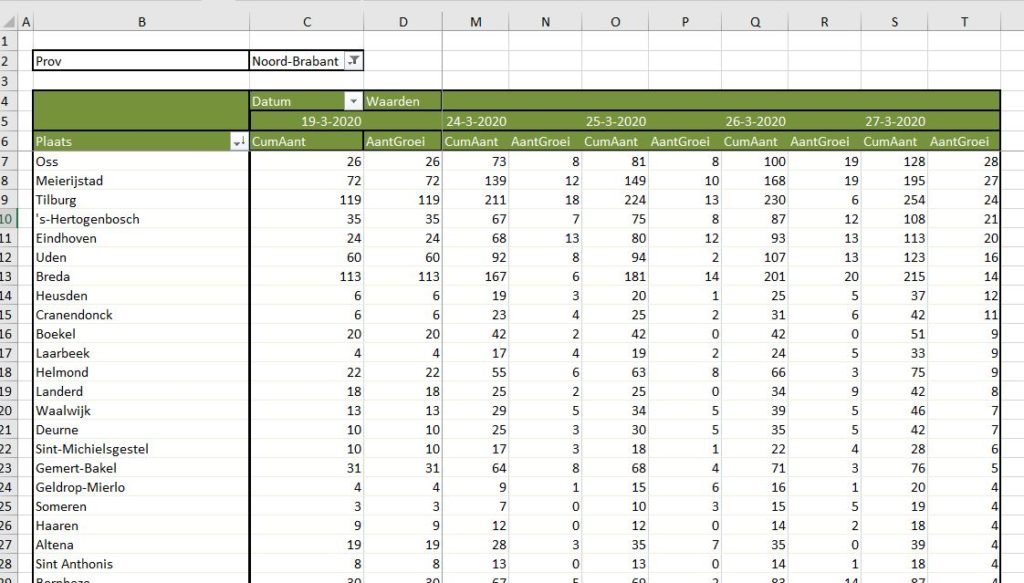
Vooral in de plaatsen aan de oost-kant van Brabant is het aantal besmettingen weer fors toegenomen. Op 27 maart kent ook Boekel weer 9 nieuwe gevallen, terwijl de dagen daarvoor de groei nul was.
NB1 in het voorbeeld hierboven zijn enkele dagen niet zichtbaar; via Beeld/Blokkeren is in cel E7 een Titelblokkering geplaatst.
NB2 wilt u een andere provincie zien? Maak een keuze in cel C2.
Overzicht per gemeente (2)
Grote steden kennen in absolute zin al snel veel besmettingen. Het effect daarvan kunnen we bekijken op het tabblad OvzGem2 van het Voorbeeldbestand.
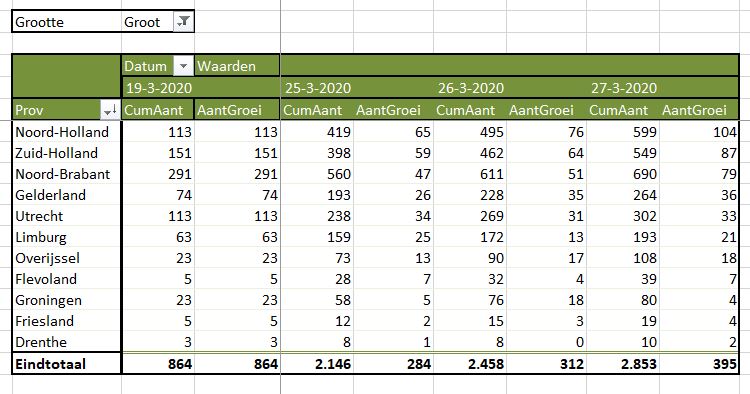
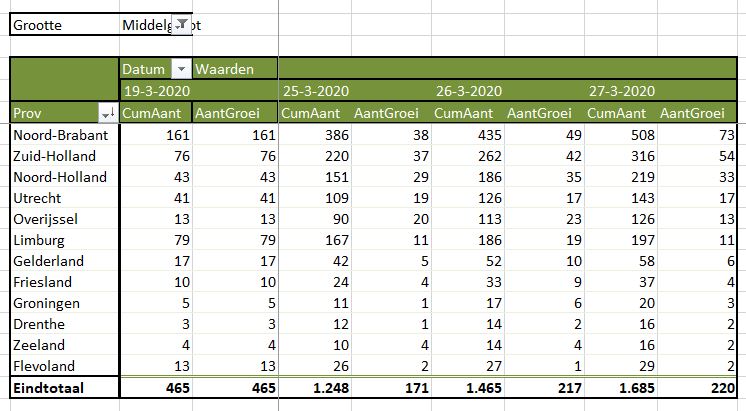
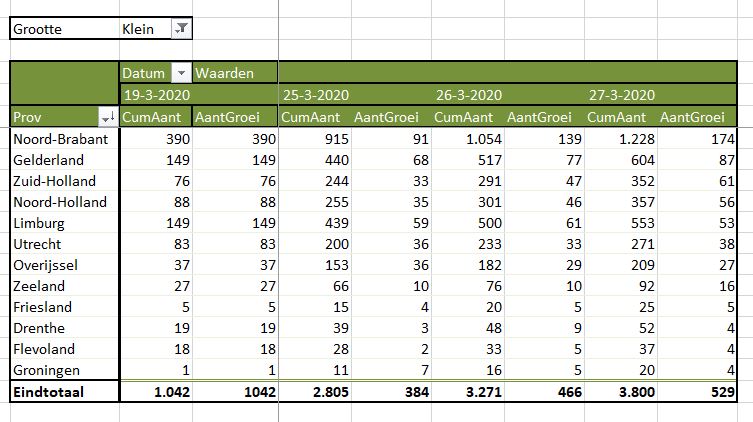
Overzicht per gemeente (3)
Maar pieken zijn duidelijker te zien wanneer we de genormaliseerde aantallen in een draaitabel zetten (zie tabblad OvzGem3 in het Voorbeeldbestand):
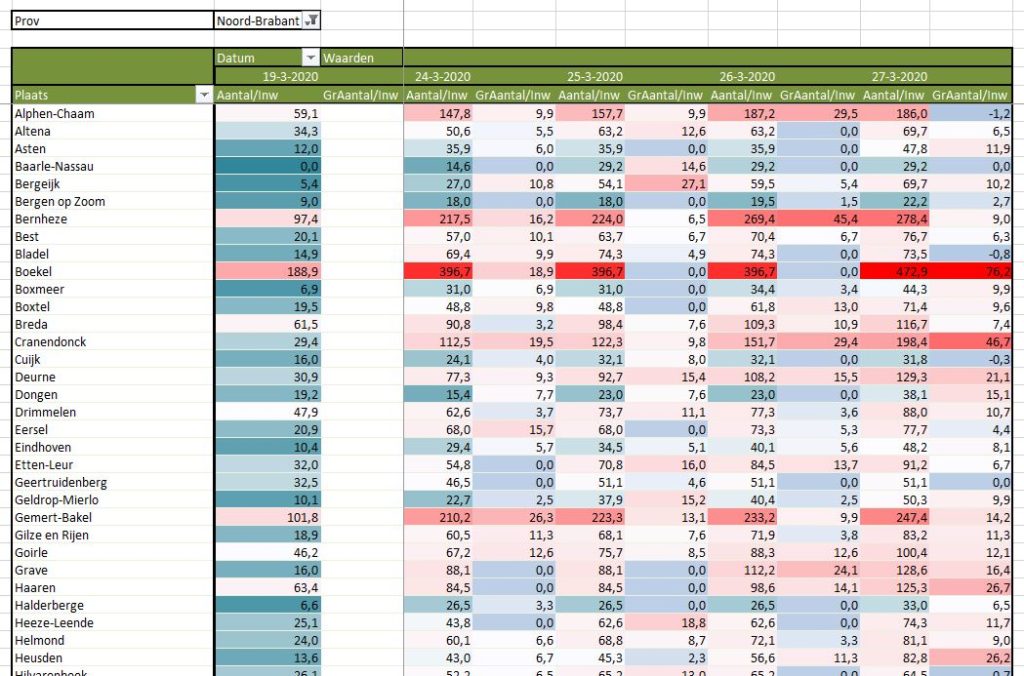
In deze draaitabel is 2 keer het veld Aantal per 100.000 inwoners geplaatst.
Door rechts te klikken op de 2e kolom kunnen de Waardeveldinstellingen aangepast worden. Zoals u hiernaast kunt zien, zal Excel het Verschil met de Vorige Datum berekenen.
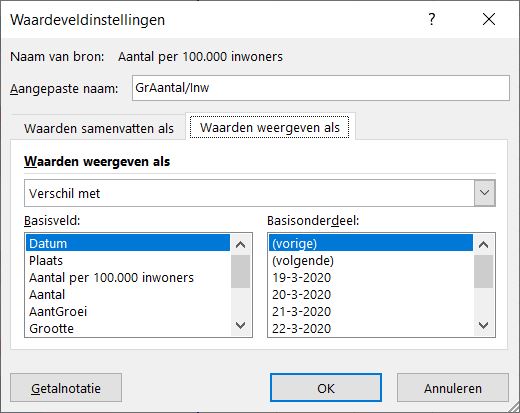
NB De kolomnamen zijn handmatig aangepast.
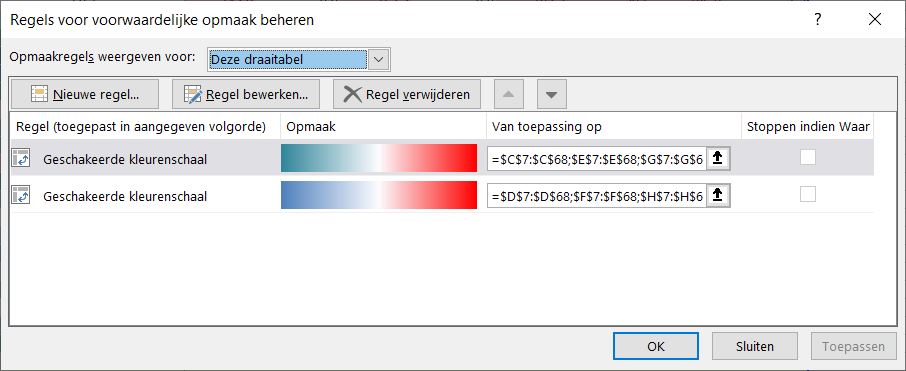
Voor allebei de waardevelden is een Voorwaardelijke opmaak ingesteld zodat uitschieters snel zichtbaar worden. Kijk in de menutab Start in het blok Stijlen bij Voorwaardelijke opmaak/Regels beheren.
LET OP wanneer er gegevens van een nieuwe datum bij zijn gekomen dan moet ook voor de nieuwe kolommen de Voorwaardelijke opmaak ingeregeld worden in de kolom Van toepassing op.
https://www.rivm.nl/actuele-informatie-over-coronavirus.
20200331_RIVM heeft de spelregels veranderd: “Daarom vanaf vandaag het aantal opgenomen personen in het ziekenhuis i.p.v. het aantal nieuwe besmettingen”.
De overzichten kloppen nu niet meer.
Helaas, het is niet meer mogelijk om op deze manier de (ver)spreiding van Corona te volgen.
Op de site https://nlcovid-19-esrinl-content.hub.arcgis.com/ kun je wel nog diverse overzichten en kaarten vinden.