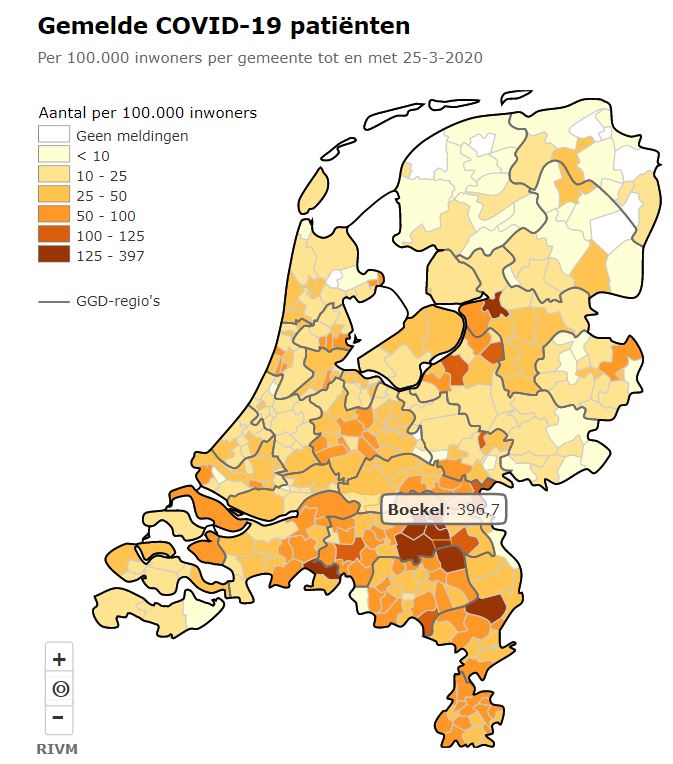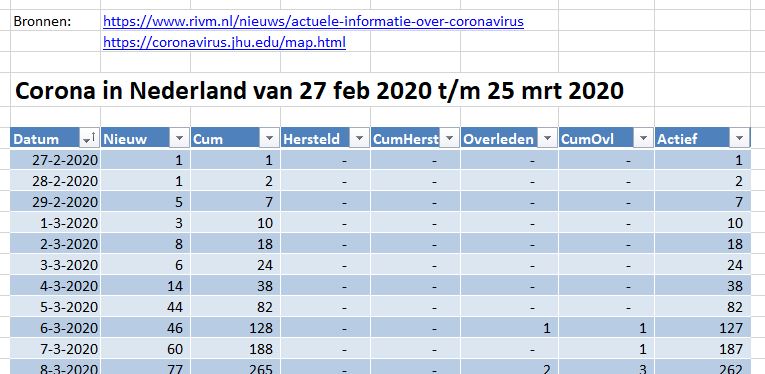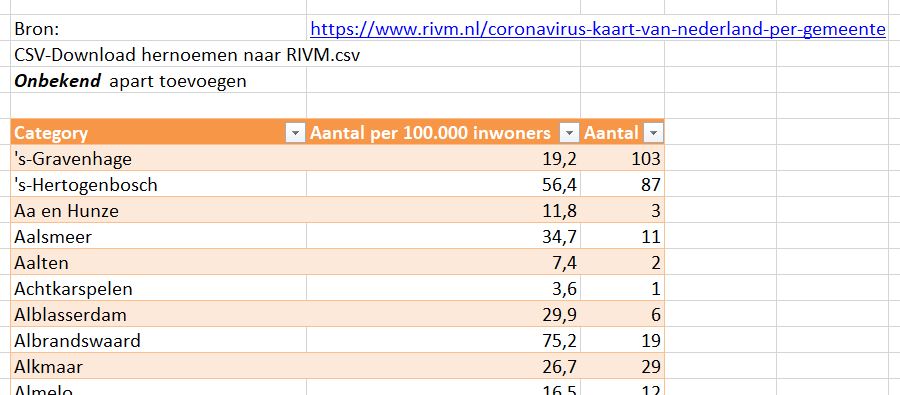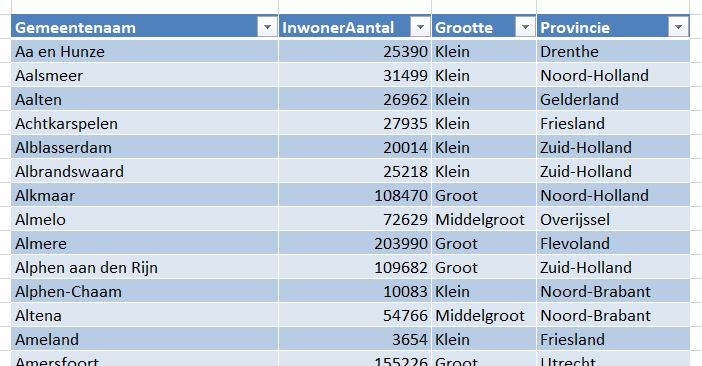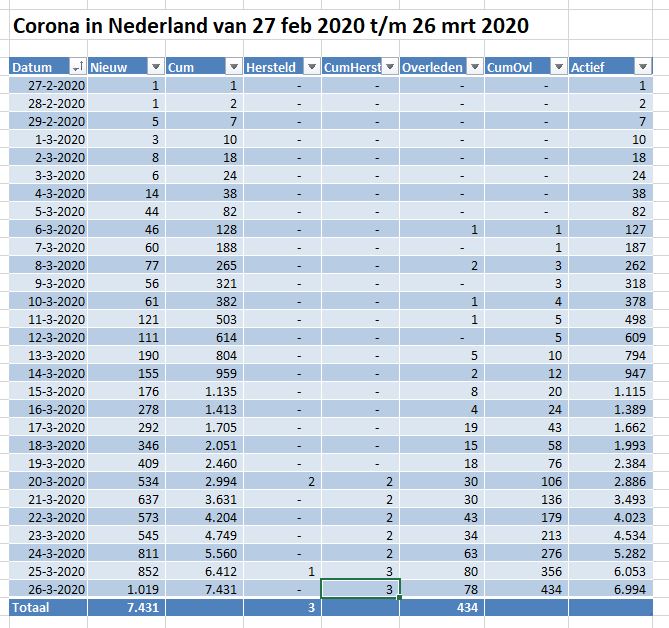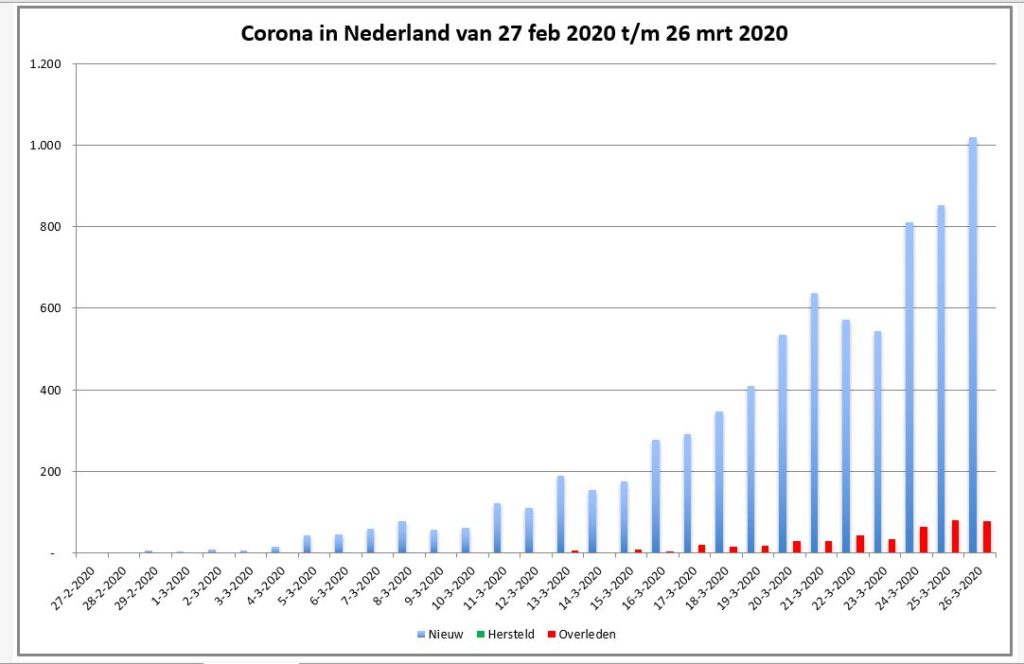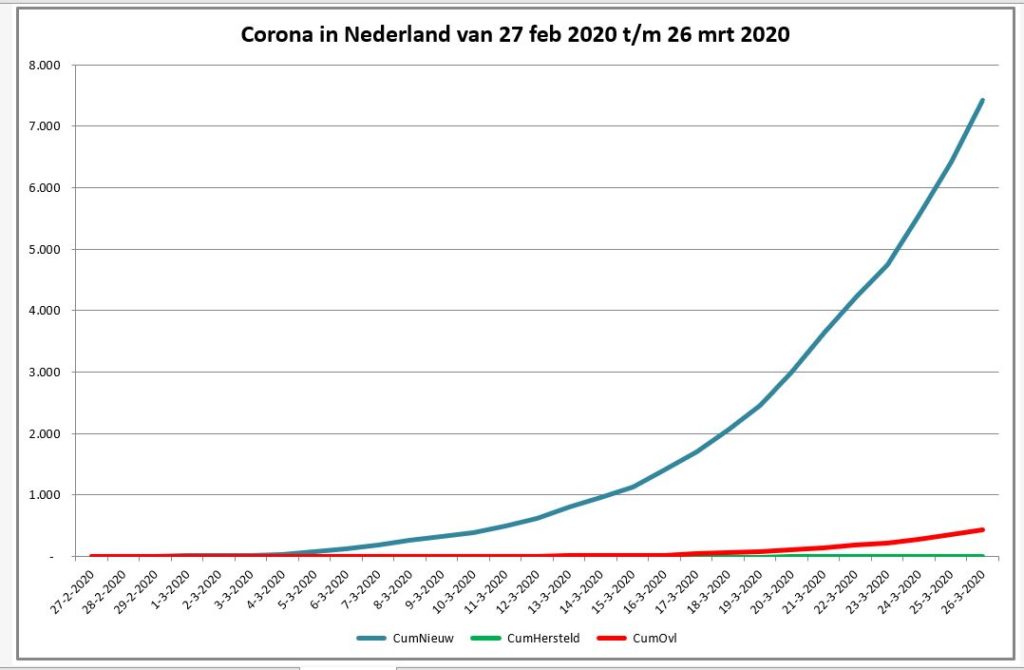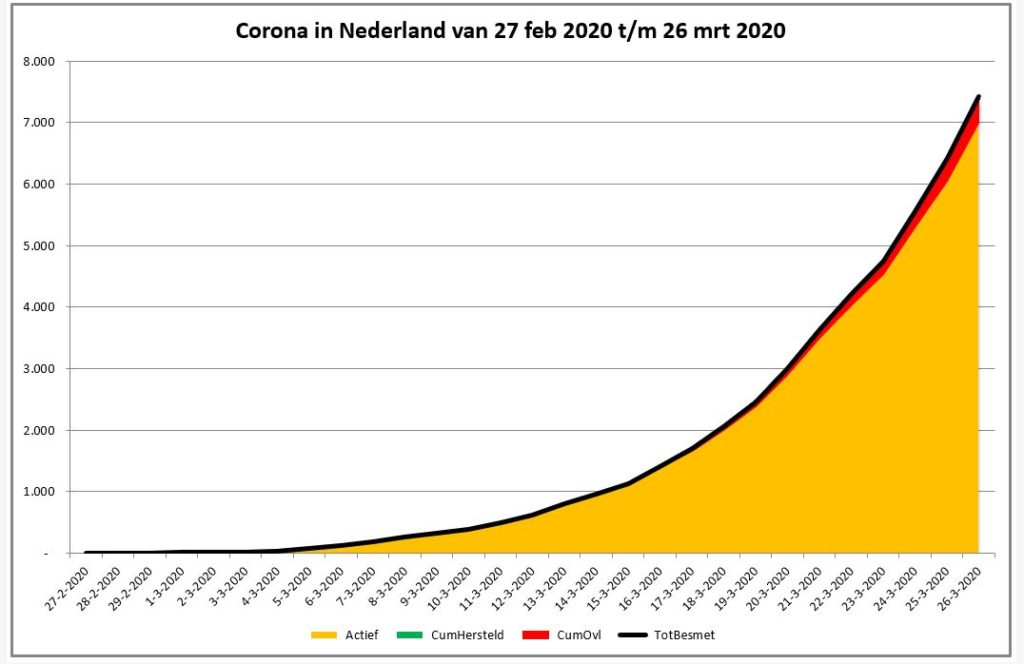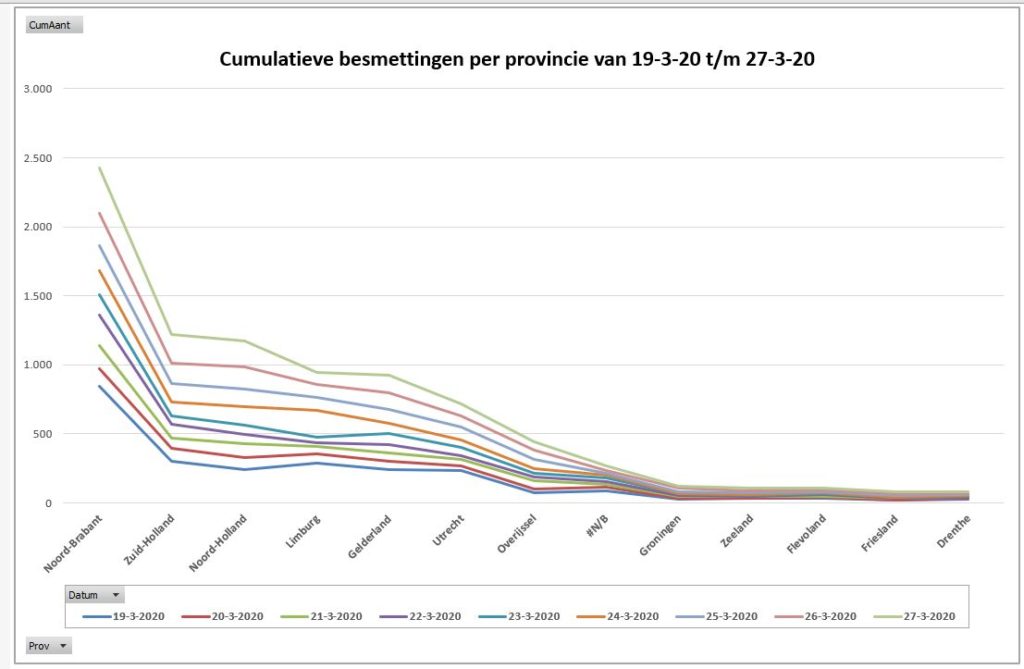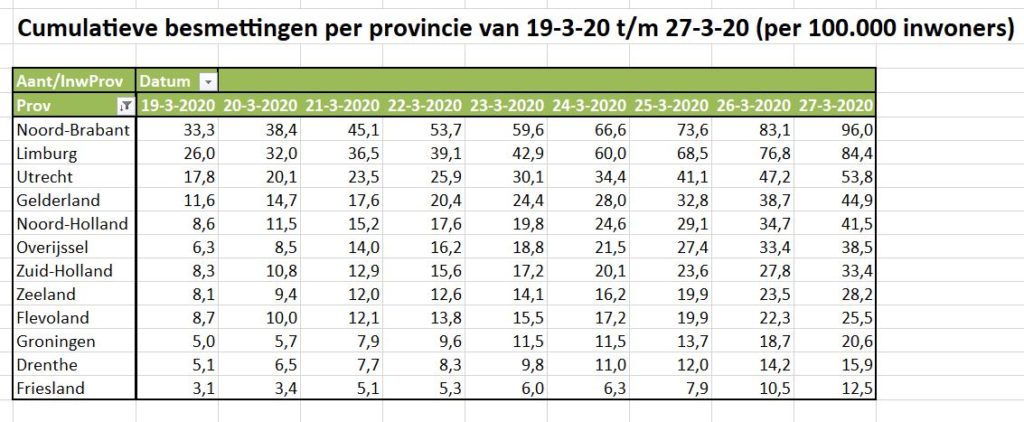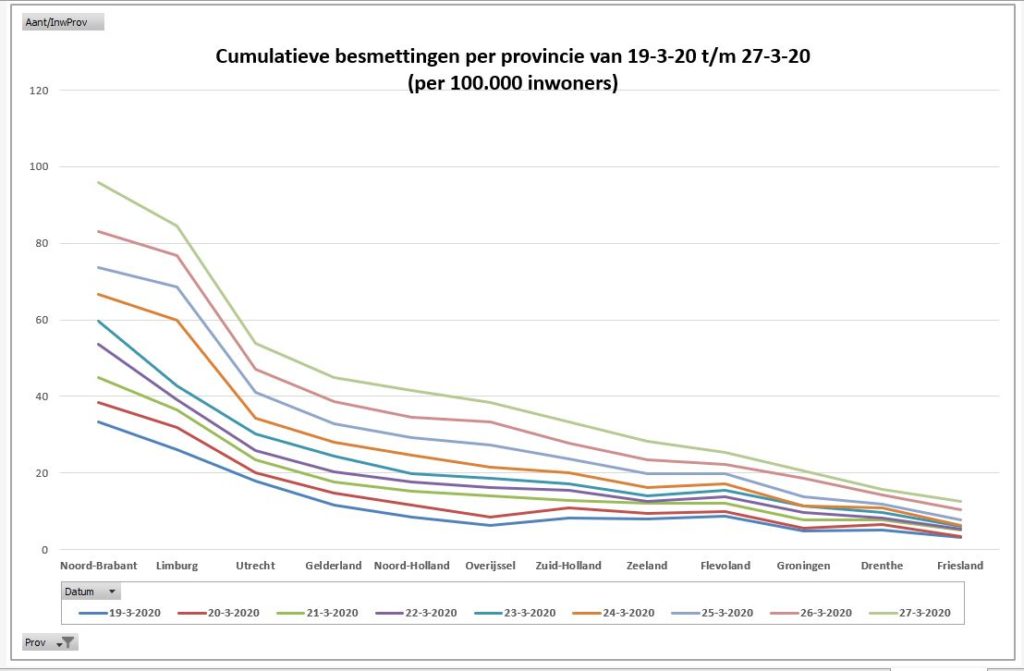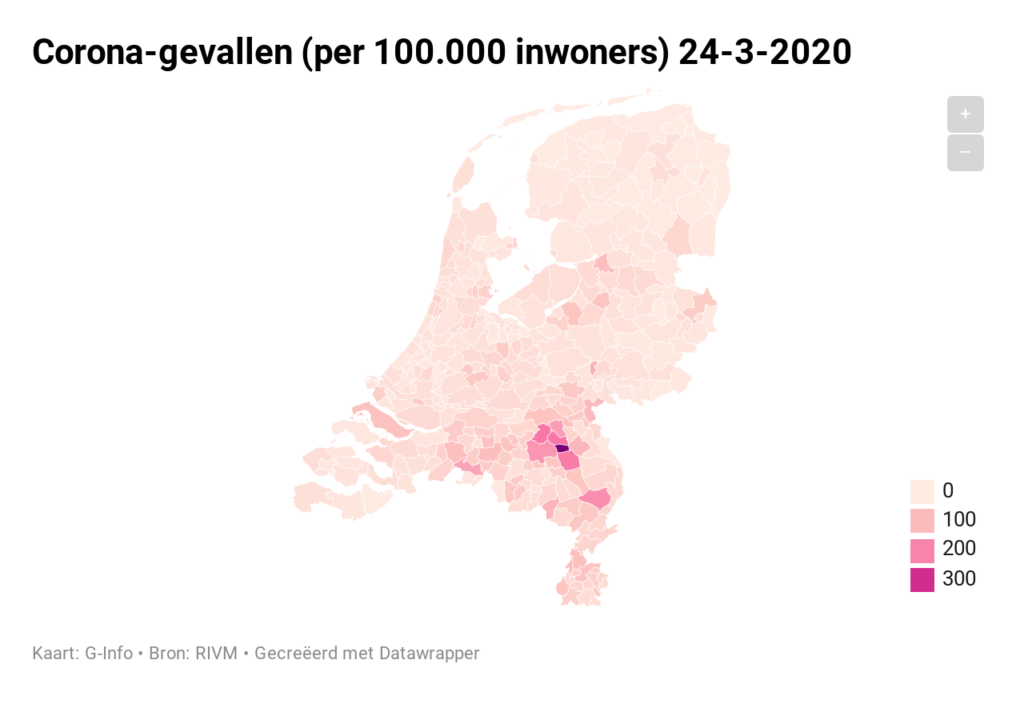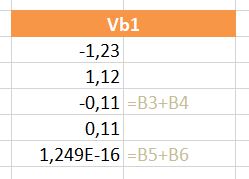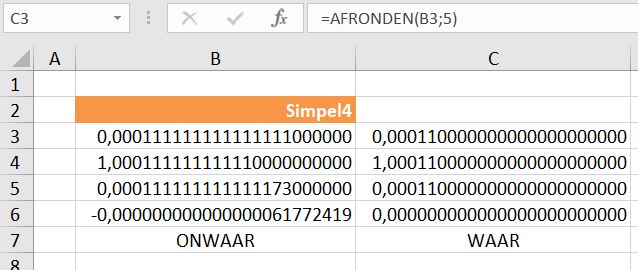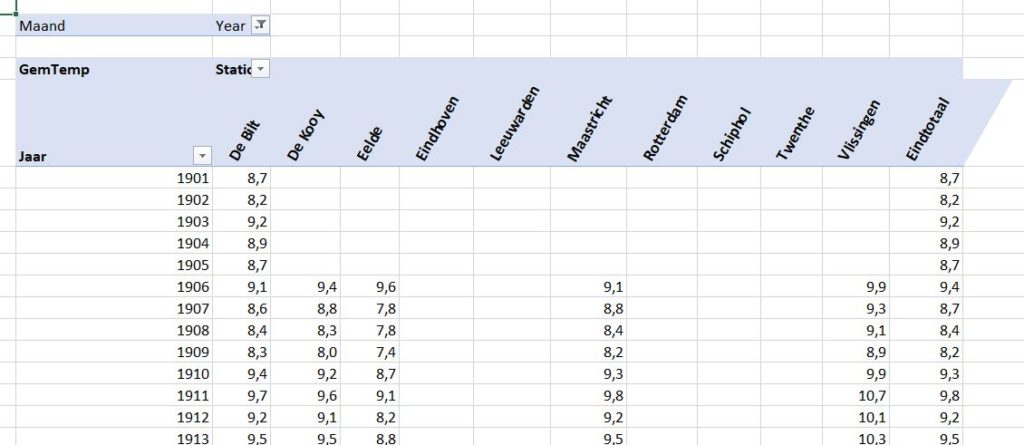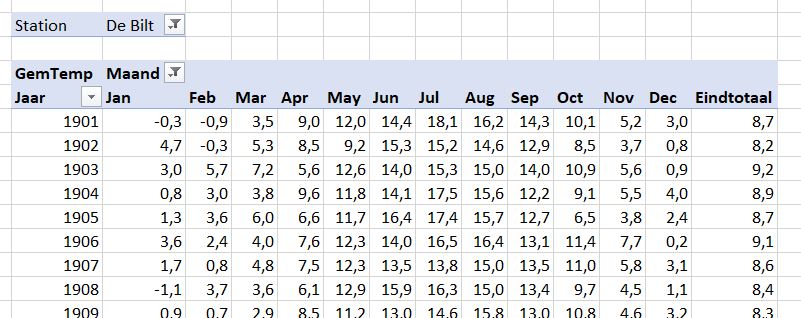
Iedere dag krijgen of vinden we wel gegevens, waarvan je denkt: interessant, maar als ik die met een andere set combineer (verrijken van data) kan ik er nog veel meer informatie uit halen.
In dit artikel geef ik uitleg over verschillende methoden zoals bestaande tabellen uitbreiden met extra kolommen, gebruik maken van het Excel-gegevensmodel en het gebruik van Power Query.
Brongegevens
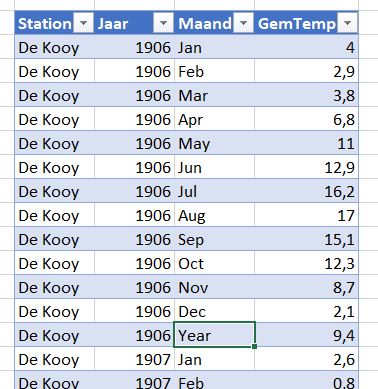
We gaan als voorbeeld een Excel-tabel gebruiken met daarin het aantal verkochte producten, uitgesplitst naar datum, klant- en productcode.
In het tabblad Verkoop van het Voorbeeldbestand vindt u 1000 records in de Excel-tabel tblVerkoop.
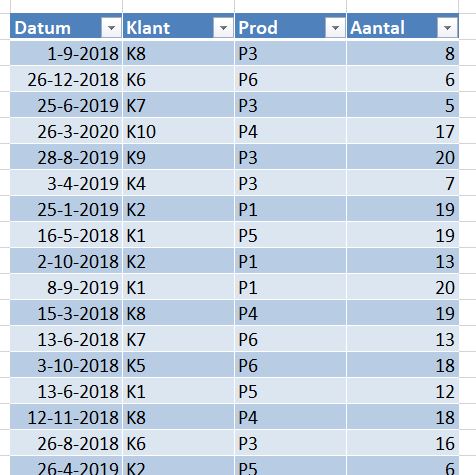
Welke klanten komen hierin voor? Welke producten zijn verkocht? Over welke periode gaat dit bestand?
Meer vragen dan antwoorden.
Verkoopoverzicht
Om snel inzicht te krijgen in bovenstaande vragen maken we op basis van het bestand een draaitabel:
- Plaats de cursor ergens in de tabel tblVerkoop.
- Kies in de menutab Invoegen in het blok Tabellen de optie Draaitabel en klik op OK.
- Sleep de Datum naar de Rijen, Aantal naar het Waarden-gebied en Prod naar Kolommen.
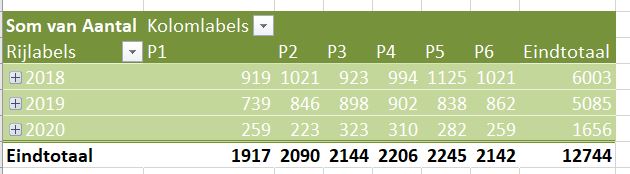
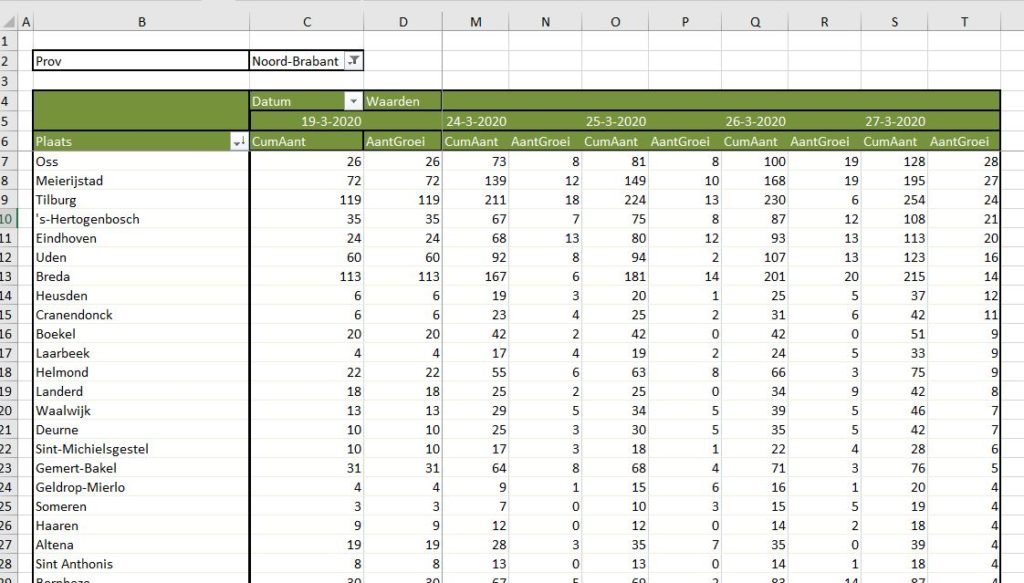
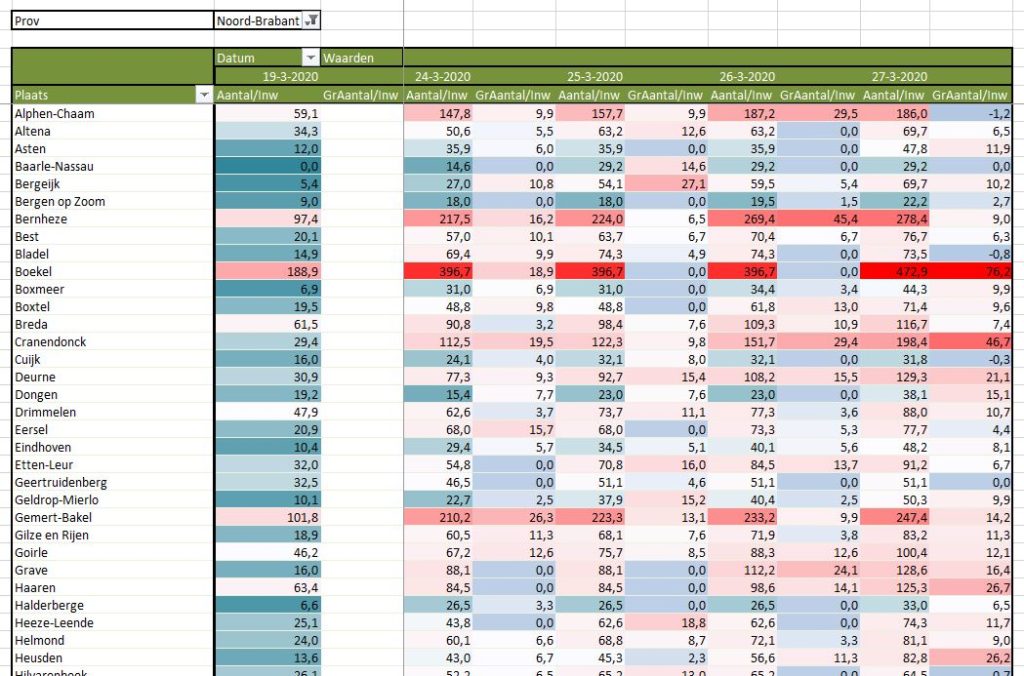
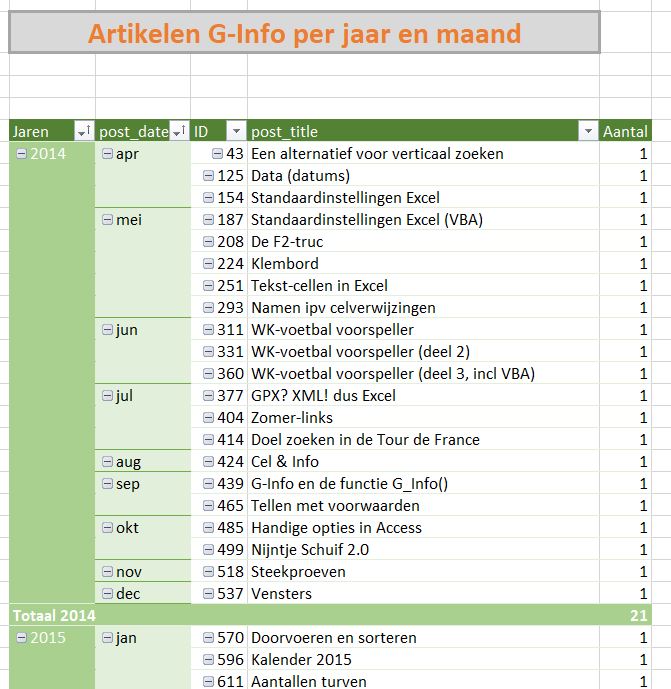
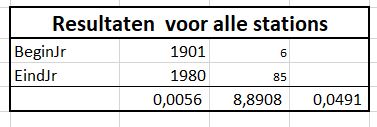
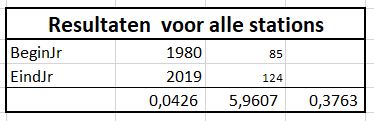
We zien dus direct (tabblad OvzVerkoop) dat het 6 producten betreft en dat het over de periode 2018-2020 gaat.
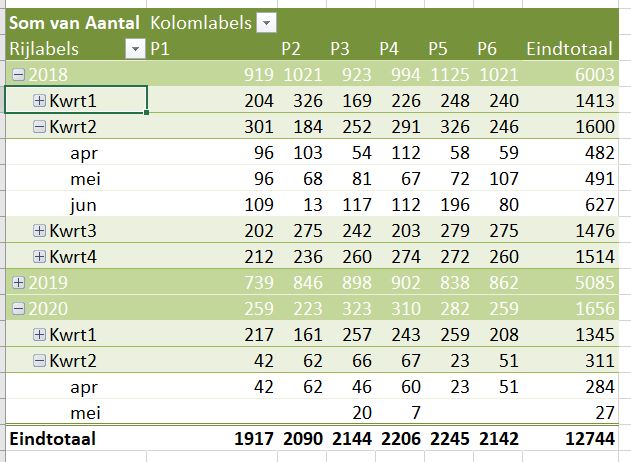
Klik je op de + voor een jaar, dan zie je welke kwartalen en maanden er in het overzicht voorkomen.
NB1 vanaf versie 2016 zal Excel datums, die in de kolommen of rijen worden geplaatst, direct groeperen naar Jaren, Kwartalen en Maanden.
Gebeurt dit niet automatisch, klik dan met de rechtermuisknop op een datum en kies Groeperen; selecteer daar dan de gewenste opties.
NB2 wil je geen groepering naar kwartaal? Klik rechts op een van de tijdaanduidingen, kies Groeperen en deselecteer de optie Kwartalen.
Maar hoe zit het met de klanten?
- Verwijder Prod uit de Kolommen.
- Verplaats Jaren van Rijen naar Kolommen.
- Sleep Klanten naar Rijen.
Zie het tabblad OvzVerkoop.
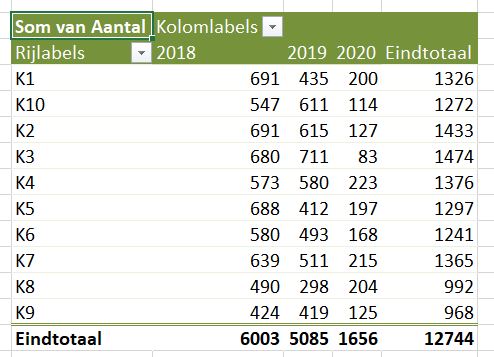
NB Excel plaatst de klanten bij het aanmaken van de draaitabel netjes in alfabetische volgorde, maar door de methode van codering komt K10 direct na K1. Gelukkig is dit snel verholpen: selecteer de cel met K10, ‘pak’ met de muis de rand en sleep de code naar beneden.
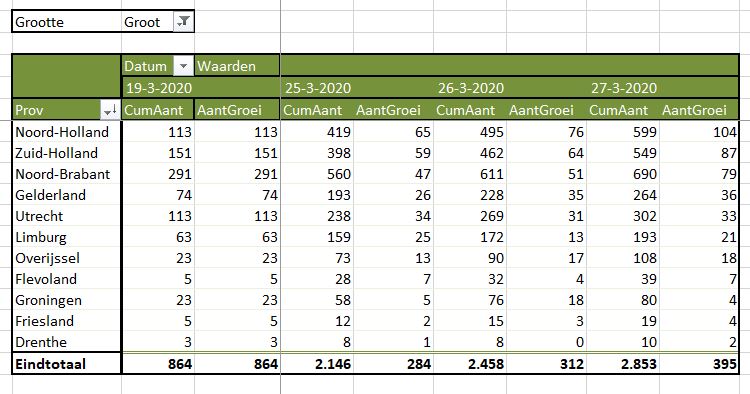
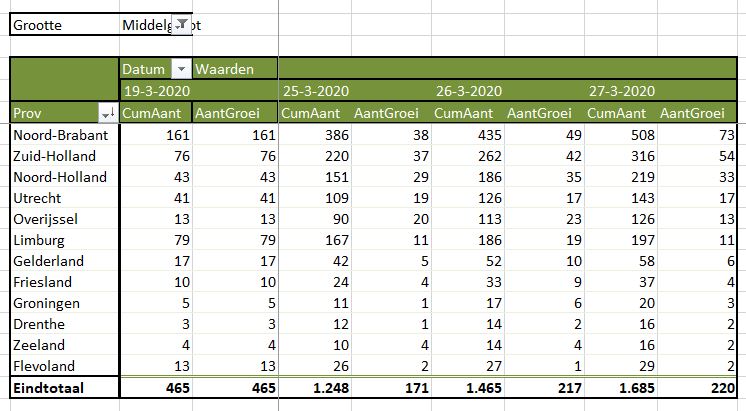
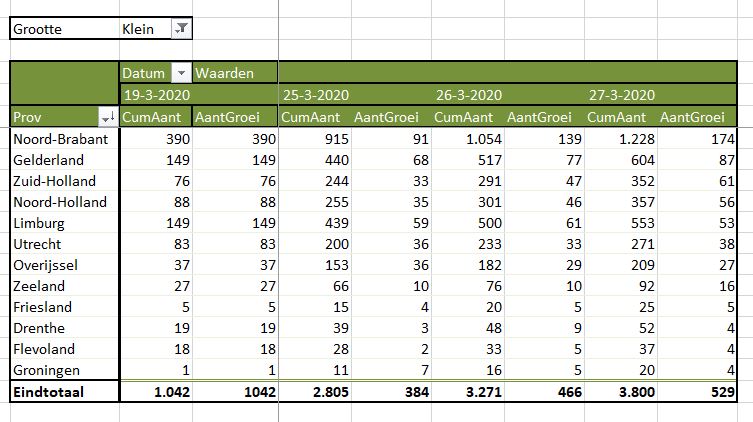
‘Toevallig’ weet ik dat de klanten over 2 regio’s zijn verdeeld: K2, K5, K7 en K8 horen bij de regio Zuid, de anderen bij Noord.
Die moeten we nu dus nog groeperen (zie Groeperen in een draaitabel): selecteer de draaitabel-rij met K2 (het muis-symbool is dan een pijltje naar rechts), houd Ctrl ingedrukt en selecteer op dezelfde manier K5, K7 en K8. Klik rechts en kies Groeperen. Nog even de namen van de groepen aanpassen (gewoon overschrijven) en de groep Noord naar boven verslepen: klaar!
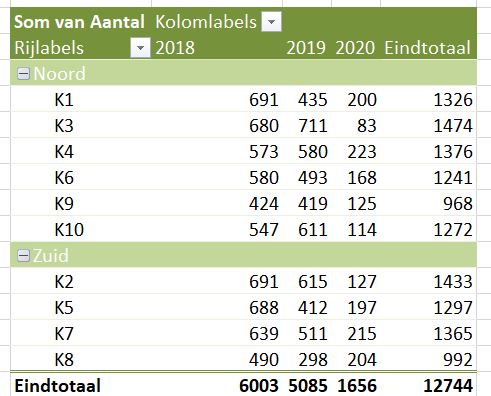
Op deze manier hebben we handmatig de eerste verrijkingen aangebracht.
Verrijking door toevoegen kolommen
Maar we weten nog meer over onze klanten en de producten:
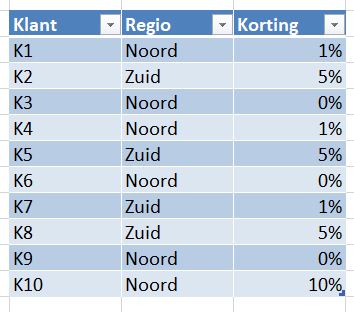
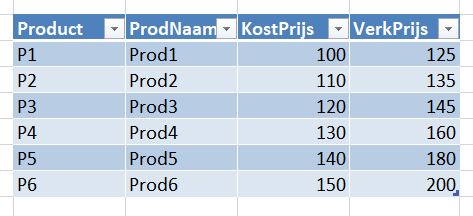
Hiermee kunnen we onze dataset uitbreiden. Dezelfde gegevens van het tabblad Verkoop zijn allereerst gekopieerd naar VerkBerek van het Voorbeeldbestand.
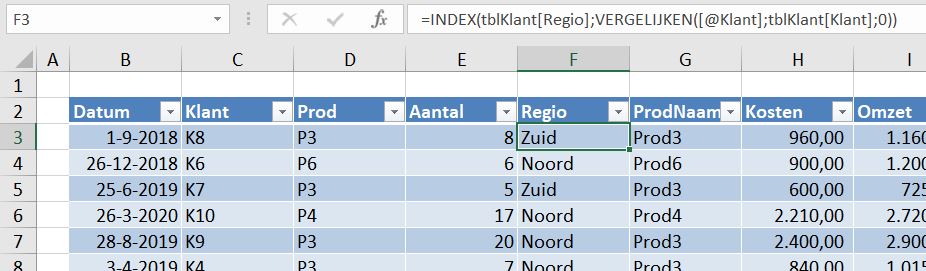
Aan de Excel-tabel (met de naam tblVerkBerek) zijn nieuwe kolommen toegevoegd:
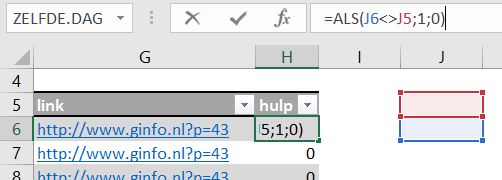
- Regio, in cel F3 staat de formule:
=INDEX(tblKlant[Regio];VERGELIJKEN([@Klant];tblKlant[Klant];0))
NB1 hier is een alternatief voor verticaal zoeken gebruikt. De avz-truc komt goed van pas! Zie zoeken-index-en-vergelijken.
NB2 alle berekeningen worden binnen een Excel-tabel uitgevoerd, waardoor we gestructureerde verwijzingen kunnen gebruiken. Zie voor de voordelen van tabellen: kunst-en-excel.
NB3 na het invoeren van de formule in F3 wordt deze automatisch naar beneden doorgevoerd, zodat alle cellen in die kolom een consistente formule hebben. - In cel G3 halen we op een vergelijkbare manier de naam van het product op:
=INDEX(tblProd[ProdNaam];VERGELIJKEN([@Prod];tblProd[Product];0)) - De totale kosten, die met een verkoop zijn gemoeid worden in cel H3 bepaald:
=[@Aantal]* INDEX(tblProd[KostPrijs]; VERGELIJKEN([@Prod];tblProd[Product];0)) - In cel I3 bepalen we de omzet:
=[@Aantal]* INDEX(tblProd[VerkPrijs]; VERGELIJKEN([@Prod];tblProd[Product];0)) - Daarmee kunnen we in J3 de bruto-winst berekenen:
=[@Omzet]-[@Kosten] - Maar (sommige) klanten krijgen korting; in cel K3:
=INDEX(tblKlant[Korting];VERGELIJKEN([@Klant];tblKlant[Klant];0)) - Waarmee we ook een netto-winst kunnen bepalen in cel L3:
=[@Omzet]*(1-[@Korting])-[@Kosten]
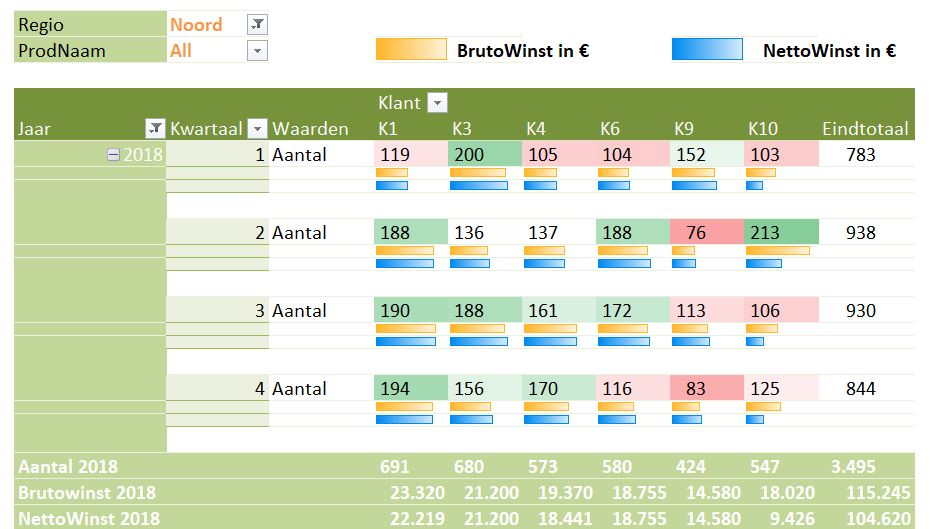
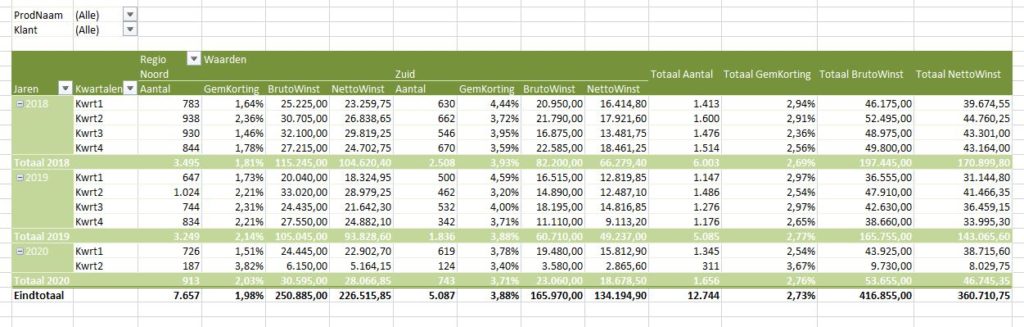
Op basis van deze nieuwe dataset kunnen we diverse analyses uitvoeren, uiteraard met behulp van een draaitabel. Bijvoorbeeld (zie tabblad OvzVerkBerek van het Voorbeeldbestand):
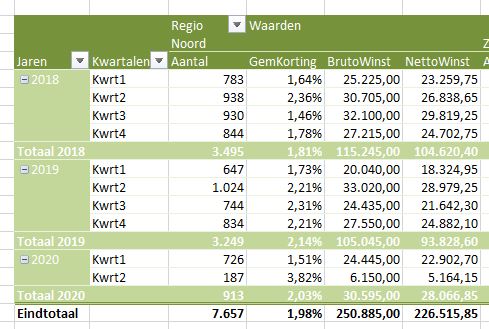
Verrijken m.b.v. gegevensmodel
Een nadeel van de vorige methode is, dat het bestand meteen een stuk groter wordt wanneer er kolommen aan een tabel worden toegevoegd. Dat valt nog wel mee als het over 1.000 records gaat, maar als het er een miljoen zijn en als het meer kolommen betreft….
De koppelingen, die we hiervoor met Index/Vergelijken hebben gemaakt, kunnen sinds versie 2013 ook intern in Excel met behulp van een gegevensmodel worden vastgelegd zonder dat dit extra ruimte in beslag neemt. Wel moeten de basisgegevens in Excel-tabellen vastliggen. In het Voorbeeldbestand bevatten de tabbladen Verkoop, Klant en Product onze basisgegevens.
Nu gaan we het gegevensmodel vullen door de relaties tussen deze tabellen vast te leggen:
- Kies in de menutab Gegevens in het blok Hulpmiddelen voor gegevens de optie Relaties (de button met 3 tabellen en lijntjes daar tussen).
- U legt een relatie vast door op de knop Nieuw te klikken:
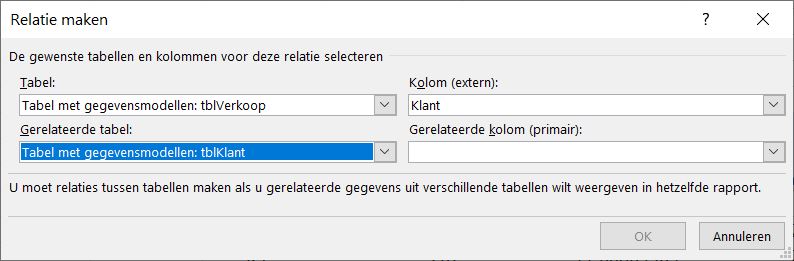
De eerste tabel moet de gegevens bevatten, die uitgebreid gaan worden; in dit geval dus tblVerkoop.
We gaan via de klant-code gegevens opzoeken, dus geven als kolom Klant op.
Daaronder moeten we aangeven in welke tabel we gaan zoeken, in het huidige voorbeeld tblKlant.
Ook in deze tabel bevat de kolom Klant de overeenkomende gegevens.
Klik op OK.
NB1 in de laatste stap staat het woord primair; hiermee wordt bedoeld, dat de kolom unieke gegevens moet bevatten. Anders kan er geen relatie aangemaakt worden.
NB2 heb je meer dan 1 kolom nodig om een relatie te leggen (bijvoorbeeld Naam en Afd) dan zul je een kunstgreep moeten uithalen: in beide tabellen moet je de 2 kolommen aan elkaar koppelen in een nieuwe kolom, bijvoorbeeld Naam&Afd. - Maak op dezelfde manier ook een relatie tussen tblVerkoop en tblProd; de kolomnamen die daarbij gebruikt worden zijn respectievelijk Prod en Product.
De namen hoeven dus niet hetzelfde te zijn. - Sluit het scherm Relaties beheren.
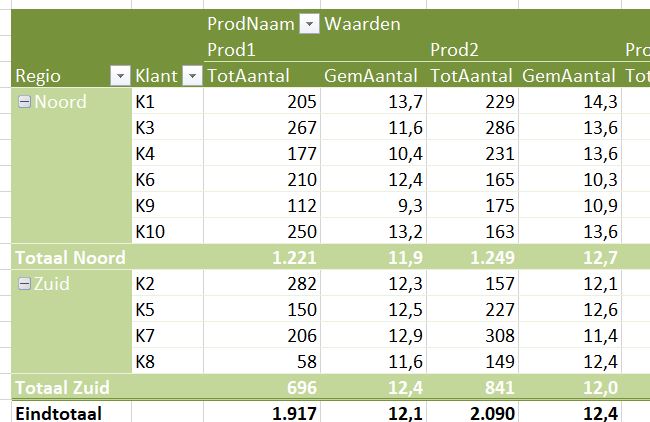
Nu het gegevensmodel is gevuld kunnen we op basis daarvan overzichten maken met behulp van draaitabellen (in het tabblad OvzVerkModel1 van het Voorbeeldbestand staat een voorbeeld):
- Plaats de cursor in een lege cel. Hier zal het overzicht komen, dus meestal doe je dit op een nieuw tabblad.
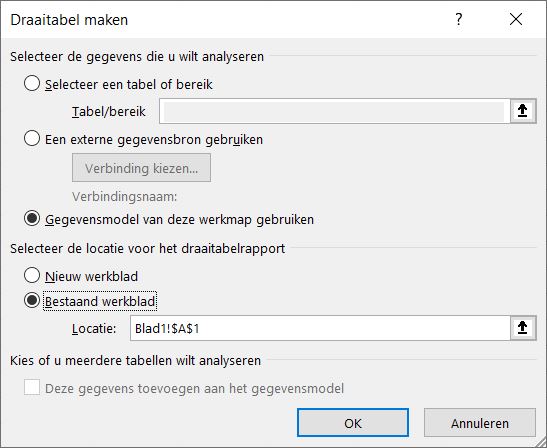
- Start via Toevoegen/Draaitabel een nieuwe draaitabel
- Hiernaast is te zien, dat Excel nu automatisch weet, dat we ons gegevensmodel als bron willen gebruiken. Klik OK.
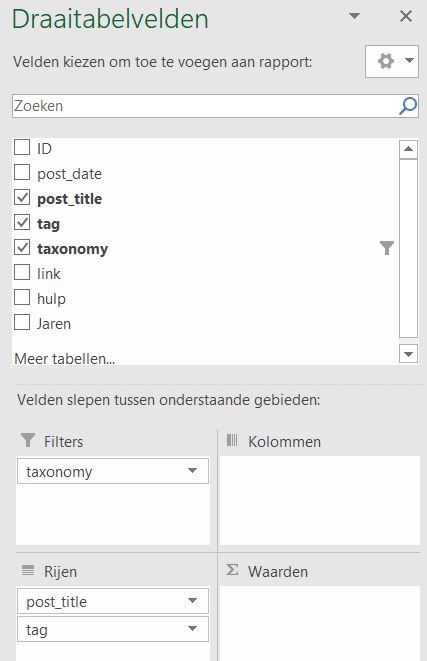
- Het overzicht van draaitabel-velden ziet er iets anders uit dan bij een ‘normale’ draaitabel.
Alle tabellen uit het gegevensmodel zijn beschikbaar met alle bijbehorende kolommen.
Hiernaast zijn alle 4 gebieden gevuld met gegevens uit 3 verschillende tabellen.
NB1 bevat de werkmap nog meer Excel-tabellen (net als het Voorbeeldbestand), dan zijn die ook in dit overzicht zichtbaar.
NB2 heb je velden naar de gebieden versleept en klik je bovenaan op Actief, dan zie je alleen de tabellen die gebruikt zijn in dit overzicht.
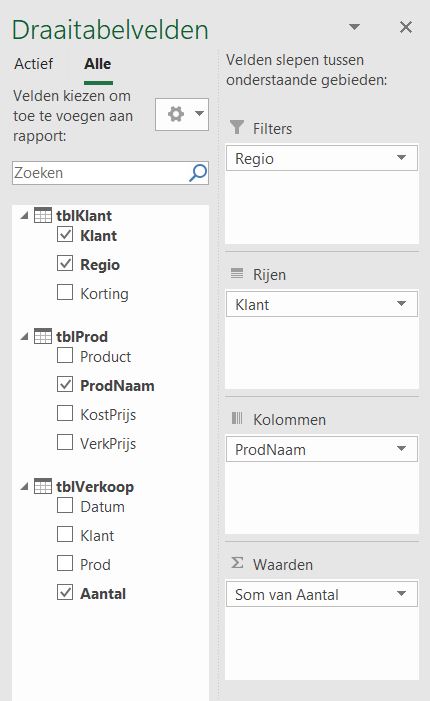
Helaas: op deze manier kun je alleen velden uit de basis-tabel (in het voorbeeld tblVerkoop) in het waarden-gebied plaatsen. Sleep je bijvoorbeeld Korting in het waarden-gebied dan krijg je de volgende melding: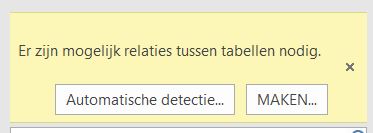
Dit scherm krijg je ook als je niet alle tabellen via relaties met elkaar hebt verbonden, maar wel kolommen uit die tabellen gebruikt.
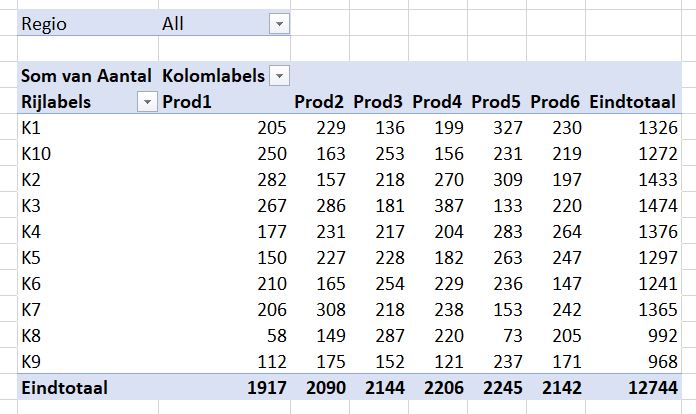
Wat nu wel kan: in de draaitabel kunnen unieke waarden geteld worden. Laten we even via een voorbeeld kijken (tabblad OvzVerkModel2 van het Voorbeeldbestand):
- Maak een draaitabel aan zoals hiervoor beschreven.
- Plaats Regio en Klant in de Rijen.
- Sleep Aantal naar het Waarden-gebied.
- Sleep daarna 2x de Datum naar het Waarden-gebied.
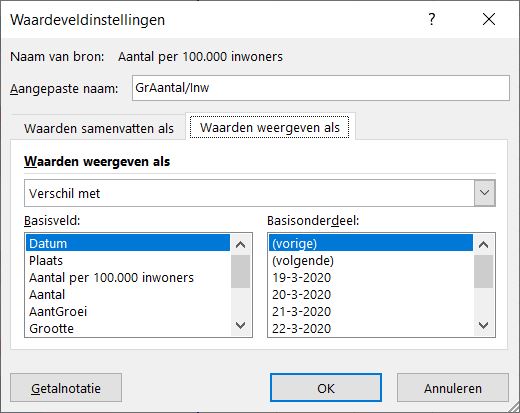
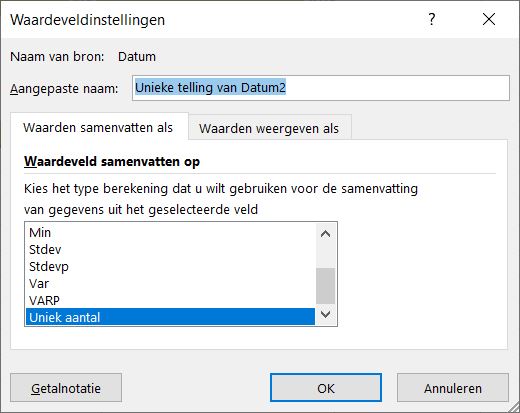
- Klik op het vinkje achter Datum2 en kies Waardeveldinstellingen.
- Helemaal onderaan krijg je nu de mogelijkheid om te kiezen voor Uniek aantal.
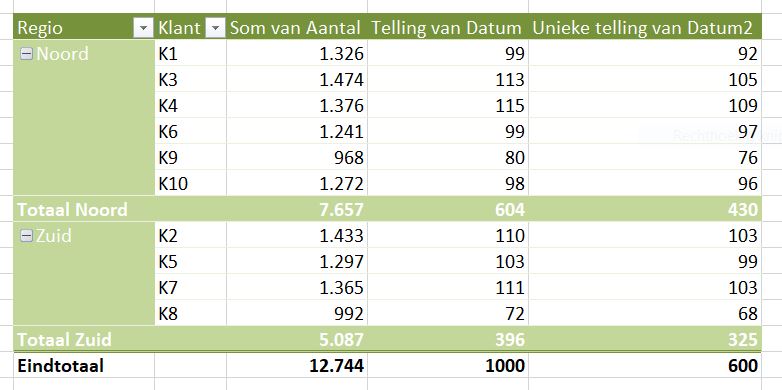
Telling van Datum geeft het aantal datums weer per klant, dus eigenlijk het aantal keer dat een klant voorkomt (als de datum is gevuld); het totaal is dan ook precies 1.000.
Unieke telling van Datum2 laat zien hoe vaak een unieke datum voorkomt bij een klant.
Verrijken m.b.v. Power Query
En dan nu een oplossing die als een soort combinatie van de vorige 2 gezien kan worden: Power Query. Binnen dit Excel-onderdeel leggen we de verbanden tussen de tabellen vast én we maken daar allerlei berekeningen die we nodig hebben:
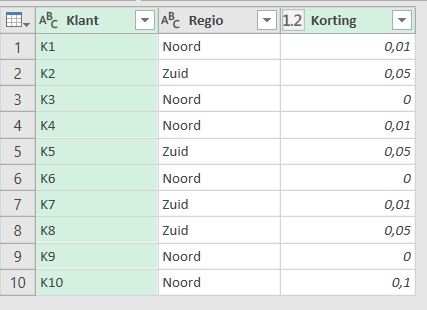
- Selecteer een cel in de tabel tblKlant.
- Kies in de menutab Gegevens in het blok Ophalen en transformeren de optie Uit tabel.
- In principe zijn alle kolommen in orde. Aangezien Korting een percentage is, kunnen we de lay-out nog aanpassen:
* klik op de 1.2 naast Korting
* wijzig de instelling naar Percentage.
- Kies dan het vinkje naast Sluiten en laden.
- Klik op Sluiten en laden naar.
- Zorg dat de optie Alleen verbinding maken is geselecteerd en klik op de button Laden.
- Voer de vorige stappen ook uit voor de tabel tblProduct. Zorg dat KostPrijs en VerkPrijs de instelling Decimaal getal krijgen.
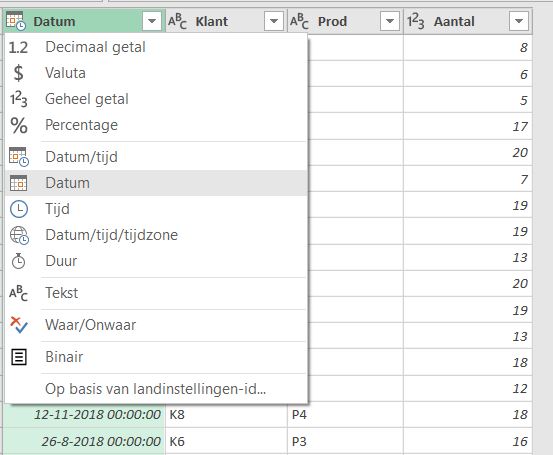
- Als laatste doet u hetzelfde met de tabel tblVerkoop, maar nog NIET sluiten. Wijzig de opmaak van de kolom Datum in alleen Datum.
- Voordat we Power Query afsluiten moeten we nog relaties leggen tussen de 3 tabellen.
Kies het vinkje achter Query’s samenvoegen en kies de optie Samenvoegen als nieuw.
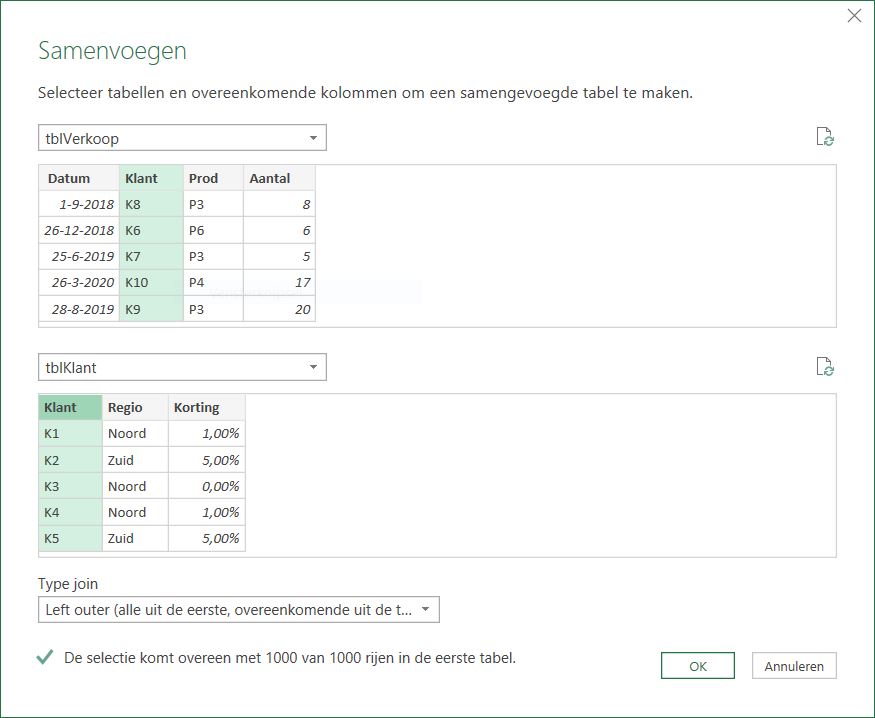
- Maak de verbindingen zoals hierboven en klik op OK. Wijzig de naam van de nieuwe query in PQtblVerkoop.

- Om de gegevens uit tblKlant als extra kolommen toe te voegen klikt u op het symbool rechts van tblKlant. Stel de opties in zoals hierboven en klik OK.
- Doe hetzelfde met tblProduct.
- Nu gaan we nog wat extra kolommen toevoegen: klik in de kolom Datum, klik op de menutab Kolom toevoegen en kies binnen de optie Datum voor het Jaar. Doe hetzelfde om de maand, de naam van de maand en het kwartaal toe te voegen.
- Kies daarna de optie Aangepaste kolom binnen Kolom toevoegen. De naam wordt Omzet en de formule =[Aantal]*[VerkPrijs].
- Voeg op dezelfde manier nog 3 kolommen toe:
Kosten: =[Aantal]*[KostPrijs]
Brutowinst: =[Omzet]-[Kosten]
Nettowinst: =[Aantal]*([VerkPrijs]*(1-[Korting])-[Kostprijs]) - Zorg dat de 4 toegevoegde kolommen de instelling Decimaal getal hebben.
- Kies nu Sluiten en laden en zorg dat er alleen een verbinding tot stand wordt gebracht.
LET OP zorg wel dat deze query PQtblVerkoop in de laatste stap wordt toegevoegd aan het gegevensmodel.
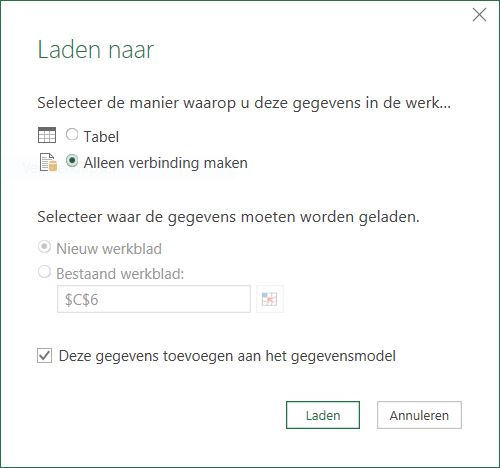
Nu staat alles klaar om overzichten te maken. Op het tabblad OvzVerkPQ van het Voorbeeldbestand vindt u een voorbeeld:

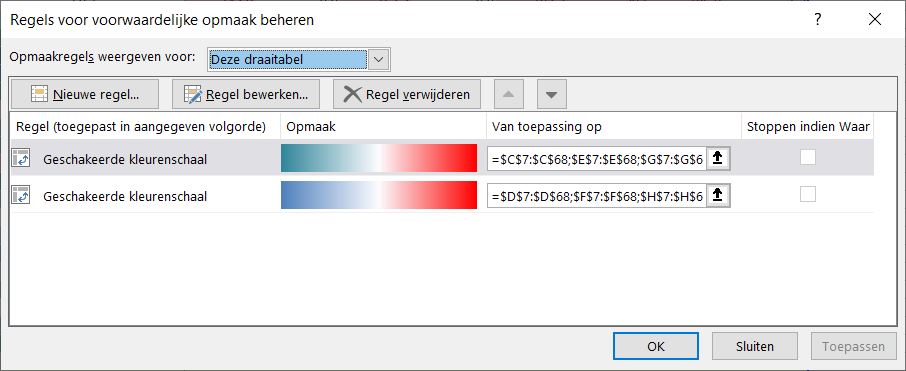
De gegevens van de bruto- en nettowinst zijn niet als getallen zichtbaar. Met behulp van Voorwaardelijke opmaak hebben die gegevensbalken gekregen:
- Selecteer een cel in een betreffende rij.
- Kies in de menutab Start in het blok Stijlen de optie Voorwaardelijke opmaak.
- Kies dan Gegevensbalken en een kleur(overgang).
- Naast de cel staat nu het tekentje van een draaitabel, kies daar de onderste optie.
- Via Regels beheren/Regel bewerken de optie Alleen balk weergeven aanvinken.
- Pas de rijhoogte naar wens aan.
De Aantallen hebben op een vergelijkbare manier een Voorwaardelijke opmaak gekregen, namelijk Kleurenschalen.
Wijzigt er iets aan de basisgegevens of hebt u nieuwe gegevens aan de tabellen toegevoegd? Door te klikken op de button
Wijzigt er iets aan de basisgegevens of hebt u nieuwe gegevens aan de tabellen toegevoegd?
Door te klikken op de button Alles vernieuwen in het blok Verbindingen van de menutab Gegevens, worden alle koppelingen, het gegevensmodel en alle draaitabellen ververst.