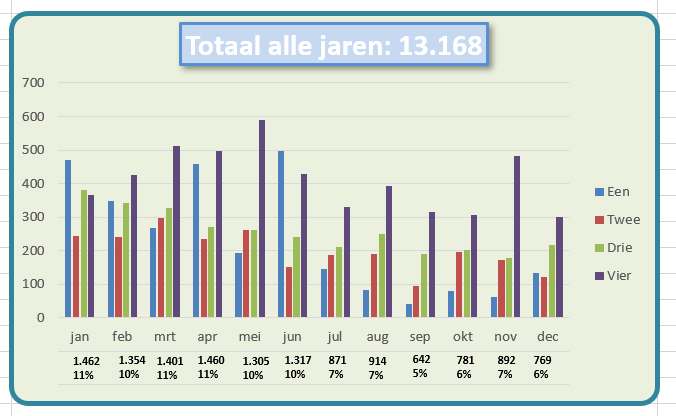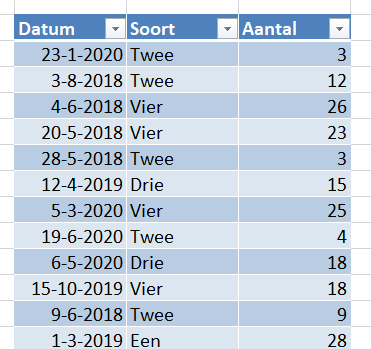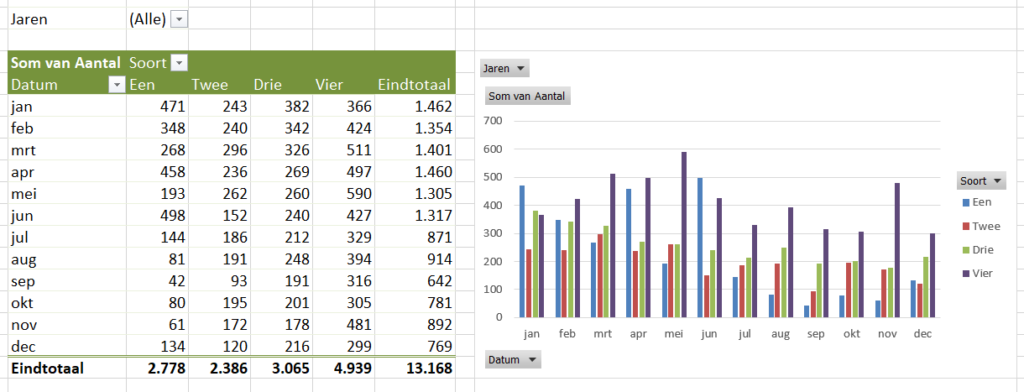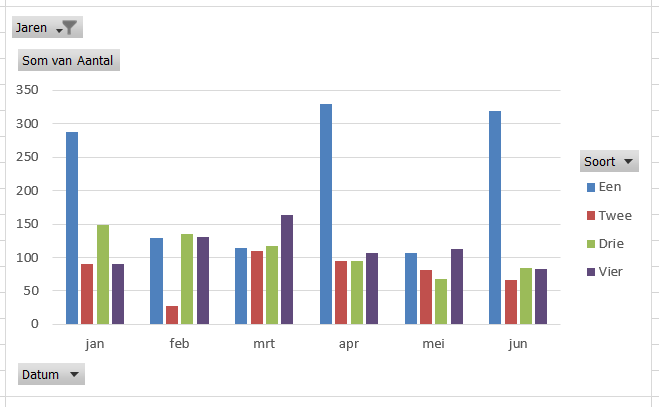
De Tour de France: ieder jaar kijk ik er weer naar uit, deze keer wat langer dan anders!
Een artikel op de site van G-Info met de Tour-gegevens als basis mag dan ook niet ontbreken.
Overal vind je wel standen en overzichten, dus dat gaan we niet overdoen. Het leek me wel aardig om te kijken of we een overzicht kunnen maken van de meest constant-presterende renners.
We zullen daarbij allerlei manieren van tellen en zoeken gaan gebruiken, variërend van de functie AANTAL.ALS, de combinatie van Index en Vergelijken tot het gebruik van Gegevensvalidatie en Keuzelijsten.
Doel
Dit jaar gaat de Tour al direct los: de eerste dagen moeten veel ‘heuvels’ en bergen bedwongen worden (zie het tabblad Etappes in het Voorbeeldbestand). De sprinters hebben dan niet al te veel kans. Misschien vallen er zelfs al renners uit die categorie uit voordat ze aan een massa-sprint kunnen beginnen.
Daarom gaan we in dit artikel eens kijken welke renners zich het meest in de top-10 laten zien: dat noemen we dan maar de meest-constante renners.
Bron-gegevens
Etappes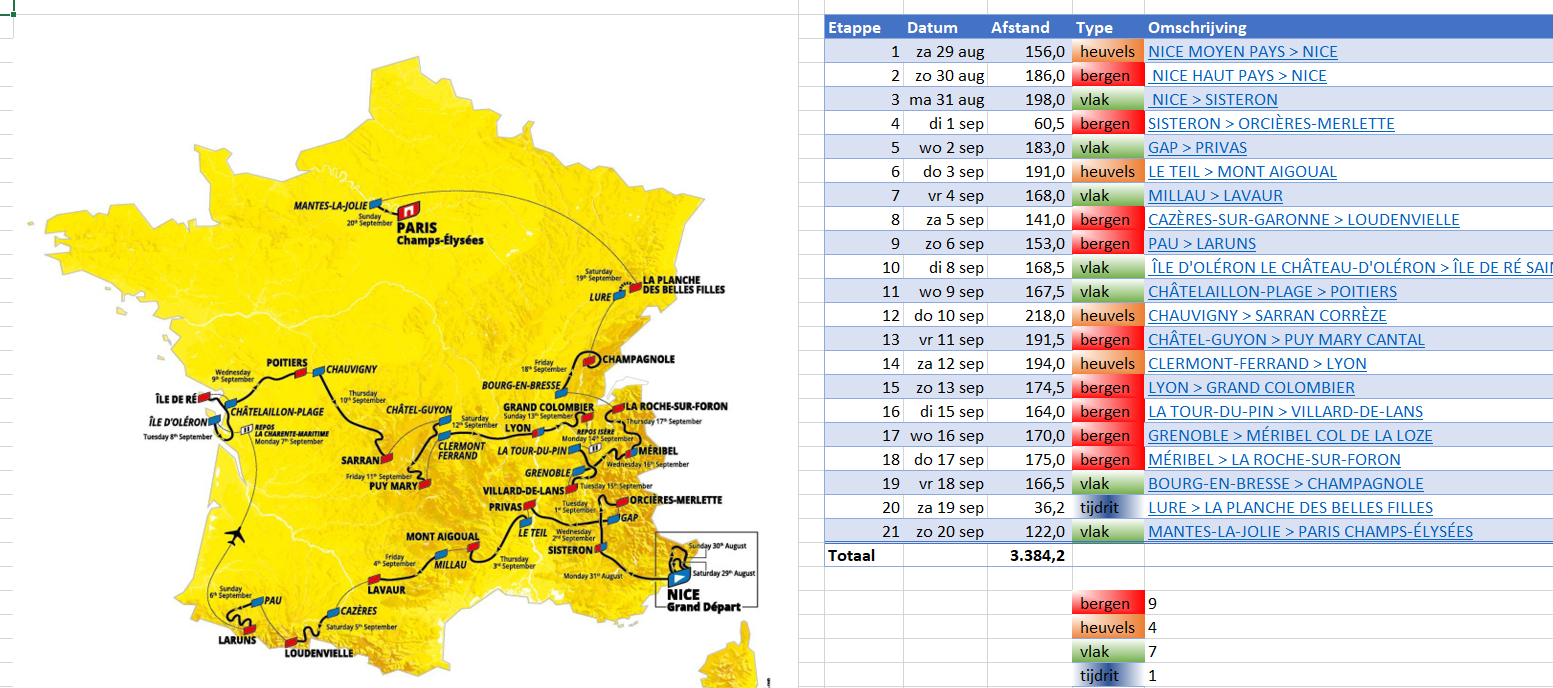
Onder andere op www.touretappe.nl kun je een overzicht van de etappes vinden. Op het tabblad Etappes van het Voorbeeldbestand heb ik die overgenomen. Alle etappes zijn via de optie Koppeling (rechts klikken op een cel) aan een pagina van die site gelinked, zodat de details van een etappe direct zijn te vinden.
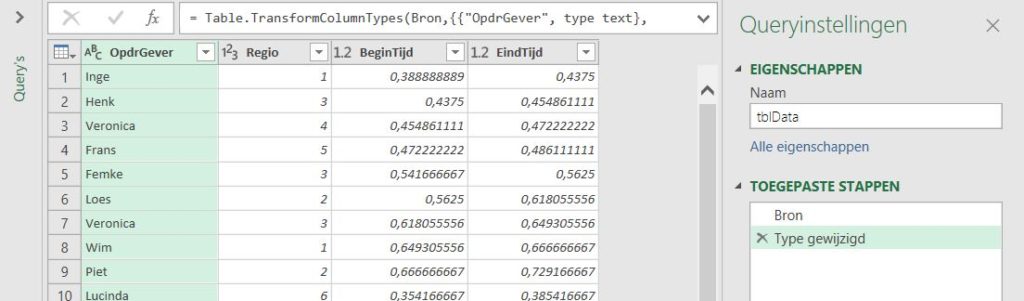
Met behulp van voorwaardelijke opmaak zijn de soorten etappes zichtbaar gemaakt. Onderaan wordt het aantal per soort geteld. In cel H26 staat daartoe de formule:
=AANTAL.ALS(tblEtappes[Type];G26)
Tel het Aantal Als in de kolom Type van de Excel-tabel tblEtappes de waarde uit cel G26 (hier Bergen) voor komt.
Van de 21 etappes zijn er dus 9 als berg-etappe gekwalificeerd!
Teams en renners
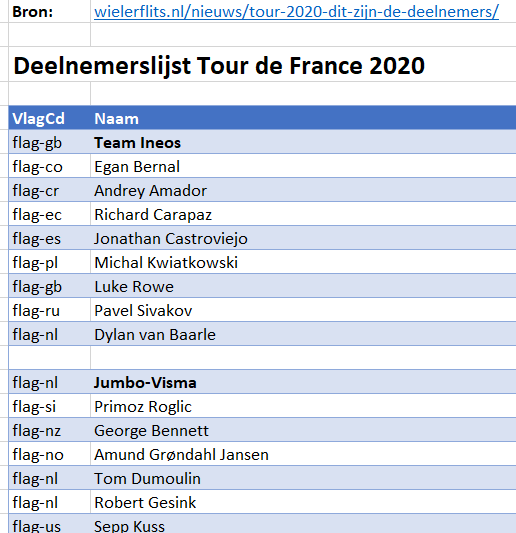
Op het tabblad Teams van het Voorbeeldbestand staat de definitieve deelnemerslijst (in een Excel-tabel tblTeams) zoals die op de site wielerflits.nl is terug te vinden. Op die site zijn de ploegen en renners voorzien van een landen-vlaggetje; bij het plakken in Excel wordt dit vertaald naar een code. Die kunnen we goed gebruiken om ons overzicht te verrijken met echte landnamen.
Aan de tabel tblTeams zijn daarom 2 kolommen toegevoegd:
- Nr: ieder team en renner krijgt een nummer: het team van de vorige winnaar heeft nummer 0, de kopman van dat team krijgt nummer 1 en de overige renners krijgen hun nummer in alfabetische volgorde.
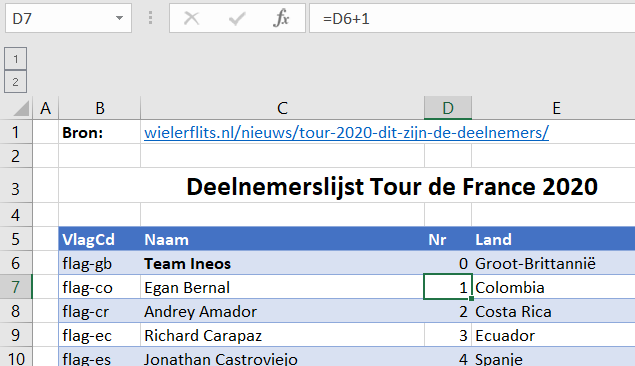
NB1 is Dumoulin bijgelovig? Hij heeft nummer 13 geruild met de Noor Grøndahl Jansen.
NB2 de kolom Nr kun je handigst op de volgende manier vullen: de eerste cel (D6) krijgt nummer 0 en in de cel daaronder plaatsen we de formule =D6+1. Deze formule doorvoeren naar alle cellen daaronder. Wis dan in de lege regels de cel in kolom D en vul bij het team het volgende tiental in (Jumbo krijgt dan nummer 10, BORA 20 etc).
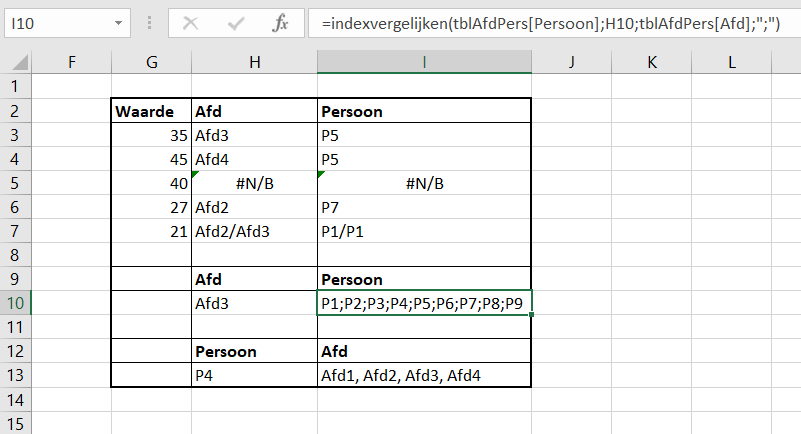
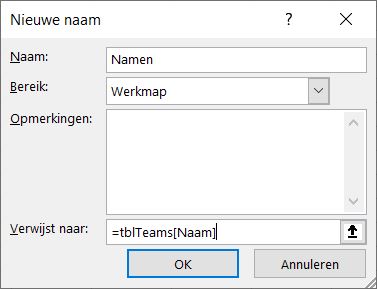
- Land: aan de hand van de vlagcode uit de eerste kolom bepalen we uit welk land het team of renner komt (zie tabblad Landen). Dat zou met VERT.ZOEKEN kunnen, maar we gebruiken liever de universeel toepasbare INDEX-VERGELIJKEN-methode (zie het artikel Zoeken: index en vergelijken, inclusief de avz-truc).
Landen
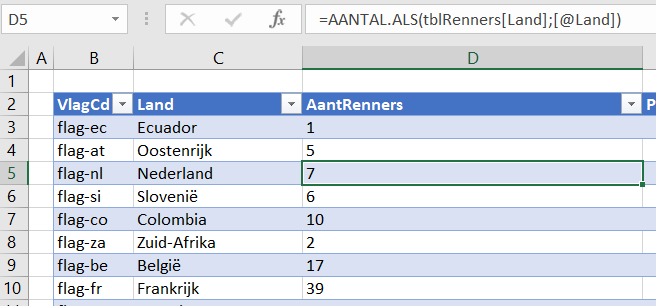
Aan iedere unieke VlagCd uit het tabblad Teams hebben we een land-omschrijving gekoppeld (in de Excel-tabel tblLand van het tabblad Landen in het Voorbeeldbestand).
In de derde kolom van die tabel (AantRenners) bepalen we het aantal renners per land: =AANTAL.ALS(tblRenners[Land];[@Land])
Turf het Aantal Als in de kolom Land van de tabel tblRenners de waarde uit de kolom Land in deze regel (vandaar de @) voor komt.
NB de tabel tblRenners is terug te vinden op het tabblad Renners van het Voorbeeldbestand; zie hierna.
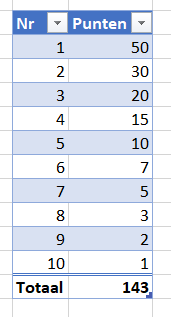
Punten
Op het tabblad Punten van het Voorbeeldbestand hebben we vastgelegd hoe de puntenverdeling voor de eerste 10 renners van iedere etappe moet zijn.
NB1 mocht het eindresultaat straks niet bevallen, dan kunt u natuurlijk proberen uw favoriete renner te helpen door de puntenverdeling aan te passen 😉
NB2 een totaal-regel onder een Excel-tabel wordt automatisch gegenereerd als de betreffende optie is aangevinkt op de menutab Ontwerpen.
Uitslagen
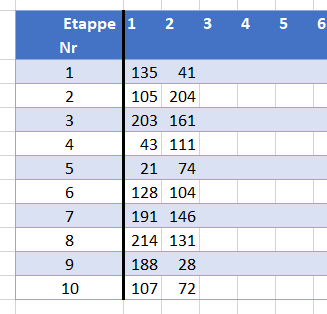
De uitslagen verwerken is heel eenvoudig: vul van de eerste 10 renners hun rugnummers in bij de betreffende etappe (zie het tabblad Uitslagen van het Voorbeeldbestand).
Op de officiële tour-site www.letour.fr kun je die rugnummers in de uitslagen vinden.
Maar wat als je alleen maar de namen hebt?
(Er zijn waarschijnlijk nog wel meer mensen die dan meteen aan Theo Koomen, of was het Barend Barendse, moeten denken: “Aan namen heb ik niks. Rugnummers moet ik hebben“).
In Excel zijn er dan allerlei opties om het rugnummer te vinden. Hier komen er een paar:
- ga naar het tabblad Teams van het Voorbeeldbestand, druk in Ctrl-F, tik een gedeelte van de naam in en klik op Alles zoeken. In het onderste gedeelte van het zoek-scherm komen alle cellen die voldoen.
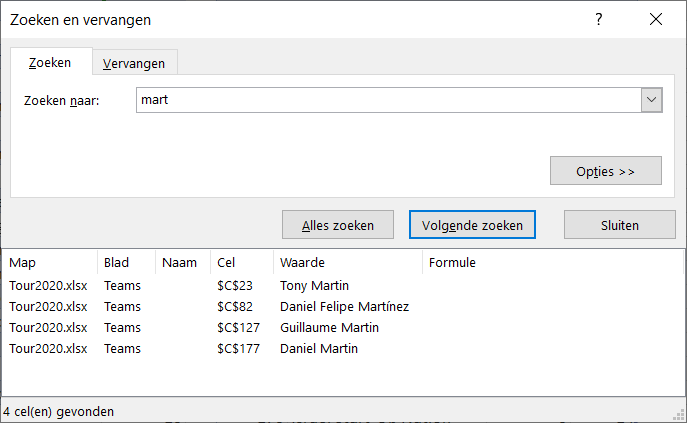
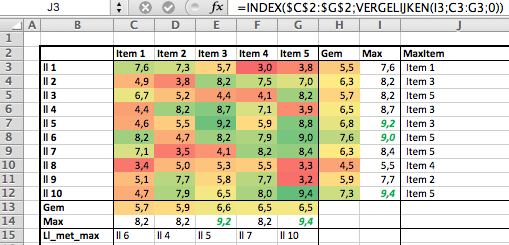
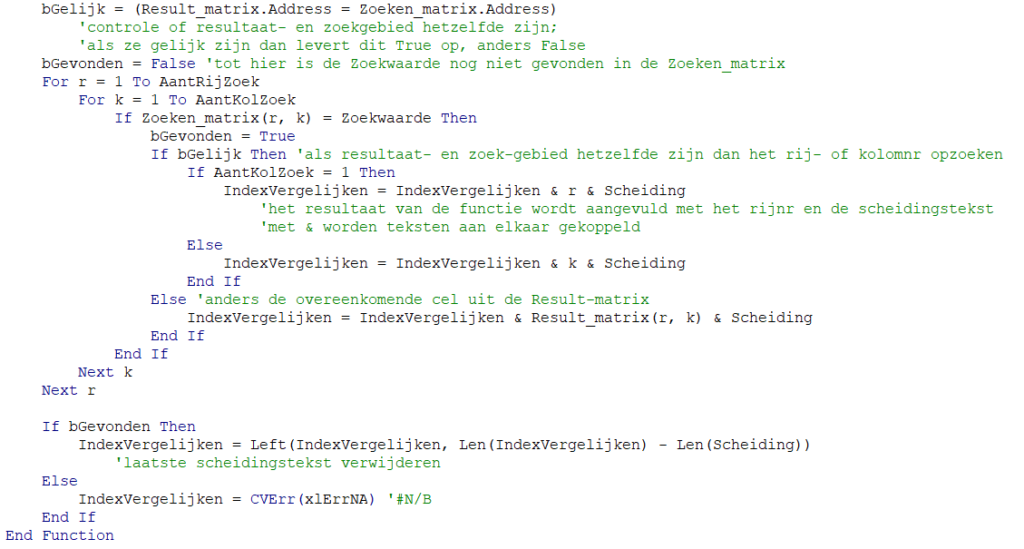
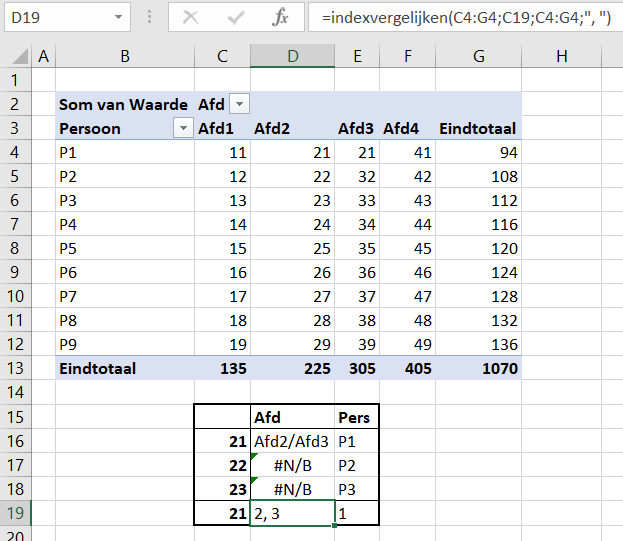
Klik op de gewenste naam en u ziet het rugnummer daarnaast staan. - gebruik Index en Vergelijken:

In cel O2 van het tabblad Uitslagen wordt eerst met behulp van de functie Vergelijken gekeken op welke positie in de kolom Naam van de tabel tblTeams de invoer in cel H2 staat. Deze functie kent zogenaamde ‘wildcards’, dus we hoeven maar een gedeelte van de naam in te tikken (de *’s geven aan dat het er niet toe doet, wat er voor en achter de inhoud van cel H2 staat). Daarna wordt deze positie gebruikt om met behulp van de functie Index het betreffende Nr op te halen.
Ter controle halen we in cel P2 op een vergelijkbare manier de naam op die hoort bij het rugnummer.
LET OP Vergelijken geeft de eerste positie terug waarvan de naam voldoet aan de voorwaarde. Is het niet de juiste naam? Tik meer letters in, bijvoorbeeld daniel f om de renner met nummer 76 op te zoeken. - denk je het rugnummer wel ongeveer te weten omdat je het team kent en je weet welk tiental bij deze ploeg hoort:

De ploeg van Jumbo-Visma begint met renner 11, Dumoulin zit vooraan in het alfabet (en hij is geen kopman!), dus zal het wel 13, 14 of 15 zijn.
Tik het nummer in in cel O4 en je ziet of je goed hebt gegokt. 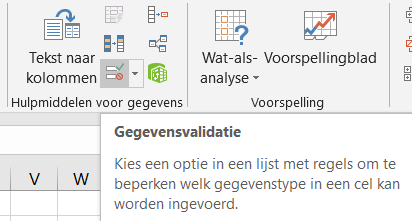 Via de menutab Gegevens in het blok Hulpmiddelen voor gegevens is aan cel H6 een Gegevensvalidatie toegewezen:
Via de menutab Gegevens in het blok Hulpmiddelen voor gegevens is aan cel H6 een Gegevensvalidatie toegewezen: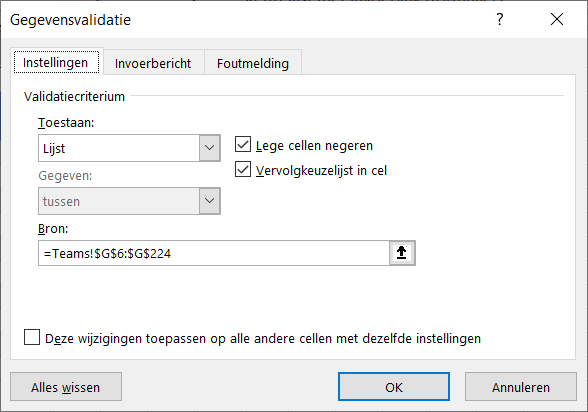
Alleen gegevens uit kolom G van het tabblad Teams zijn toegestaan.
In die kolom G staat voor iedere renner (en team) een koppeling van nummer en naam met een extra spatie daartussen: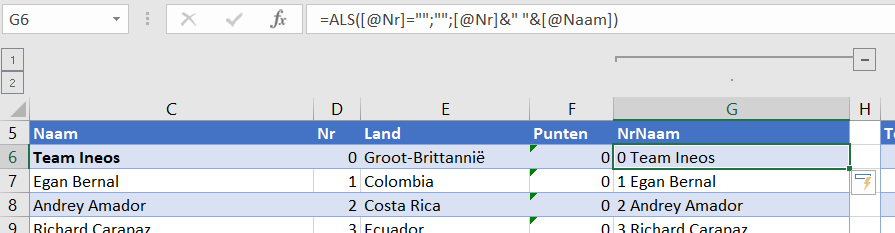
NB kolom G is standaard niet zichtbaar; via Groeperen kan de kolom ‘ingeklapt’ worden.
LET OP je kunt een kolom ook Verbergen (via rechtsklikken op een kolomletter) maar ik ben daar geen voorstander van: het zichtbaar maken is niet zo makkelijk en vaak zie je niet dat er een kolom verborgen is.
- een andere, minder gebruikte, optie is een keuzelijst (met invoervak).
Kies in de menutab Ontwikkelaars in het blok Besturingselementen de optie Invoegen.
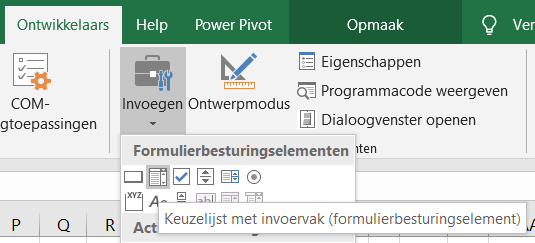
Klik op de 2e optie binnen de Formulierbesturingselementen.
‘Teken’ nu met de cursor het gebied waar de keuzelijst moet komen.
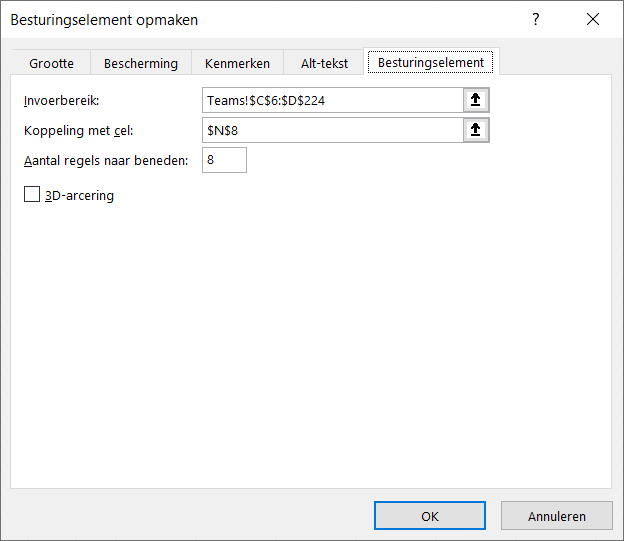
Dan komt de vraag om het besturingselement op te maken: zorg dat in het Invoerbereik de cellen geselecteerd worden met de namen van de renners en dat er een Koppeling komt met de cel naast het invoervak (zie het tabblad Uitslagen in het Voorbeeldbestand).
Wanneer je nu een naam selecteert dan komt in de gekoppelde cel de positie van deze renner in de lijst te voorschijn. Met behulp van de formule =INDEX(tblTeams[Nr];Uitslagen!N8) wordt het rugnummer opgehaald.
- een andere keuzelijst maakt gebruik van Active-X; iets ingewikkelder maar wel een stuk flexibeler.
Kies opnieuw in de menutab Ontwikkelaars in het blok Besturingselementen de optie Invoegen. Maar, let op, klik dan op de 2e optie binnen de Active-X besturingselementen.
‘Teken’ weer met de cursor het gebied waar de keuzelijst moet komen. Nu moet je de Eigenschappen aanpassen: klik op de betreffende button in de menubalk en vul de 4 eigenschappen in zoals hiernaast (achter de pijltjes).
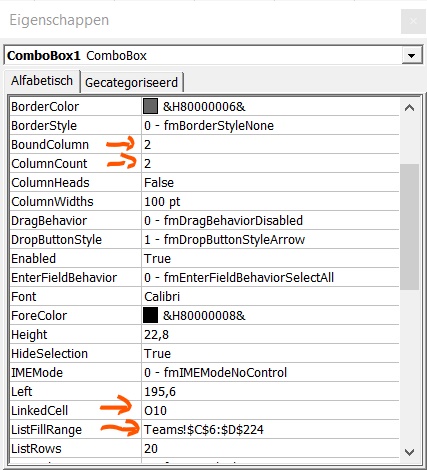
LET OP bij het gebruik van Active-X-elementen moet je de Ontwerpmodus uitzetten, wanneer je deze wilt gebruiken (en andersom als je de eigenschappen wilt aanpassen).
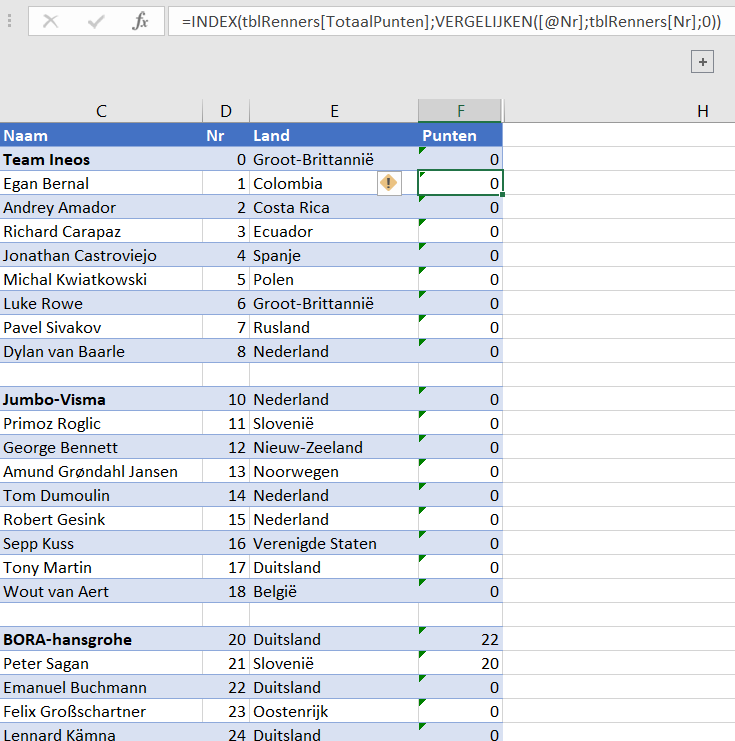
Resultaten per renner
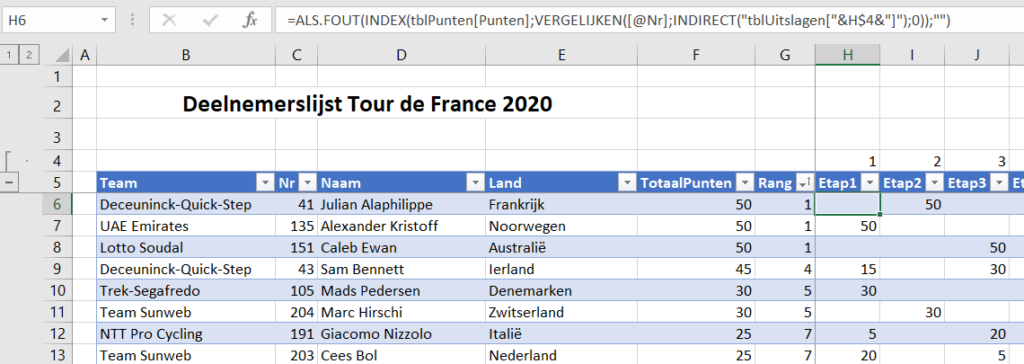
In het tabblad Renners van het Voorbeeldbestand worden de resultaten per renner ‘automatisch’ bepaald; alleen de kolom Nr bevat harde waarden, de overigen worden afgeleid of berekend:
- in cel H6 staat de formule:
=ALS.FOUT(
INDEX(tblPunten[Punten];
VERGELIJKEN([@Nr];INDIRECT(“tblUitslagen[“&H$4&”]”);0));
“”)
Aangezien cel H4 de waarde 1 bevat, wordt de 2e parameter binnen de Vergelijken-functie INDIRECT(“tblUitslagen[1]”); Excel vertaalt dit dan naar een bereik van cellen en wel de eerste kolom in de tabel tblUitslagen.
De Vergelijken-functie kijkt dan of het rugnummer in die kolom voorkomt. De positie daarvan (1 tot 10) wordt gebruikt om met behulp van de functie Index het daarbij behorende aantal punten te genereren. Als een renner geen top-10-resultaat in een etappe heeft behaald, dan zou er een foutmelding komen; met de functie Als.Fout zorgen we er voor dat in dat geval de cel gevuld wordt met een lege tekst.
Deze formule kan naar beneden en rechts gekopieerd, zodat voor alle renners voor alle etappes de resultaten worden bepaald. - in de kolommen Naam en Land worden de gegevens opgehaald uit het tabblad Teams
- zo ook voor de kolom Team, behalve dat daarvoor een berekening rond het rugnummer plaats vindt:
=INDEX(tblTeams[Naam];
VERGELIJKEN(AFRONDEN.BENEDEN([@Nr];10);tblTeams[Nr];0)
)
Het rugnummer wordt dus naar beneden afgerond op het dichtstbijzijnde veelvoud van 10. - in de kolom TotaalPunten wordt het totaal van de renner over alle etappes berekend: =SOM(tblRenners[@[Etap1]:[Etap21]])
- Dan blijft er nog 1 kolom over: Rang.
Via de formule =RANG.GELIJK([@TotaalPunten];[TotaalPunten]) wordt in die kolom per renner de rangorde in het totaal bepaald.
Kies met het driehoekje achter Rang de gewenste sortering en u weet welke renner(s) bovenaan staat/staan.
LET OP wanneer er weer nieuwe uitslagen zijn toegevoegd, worden alle formules automatisch herberekend, maar …. de sortering wordt niet vanzelf aangepast. Die moet u zelf nogmaals uitvoeren.
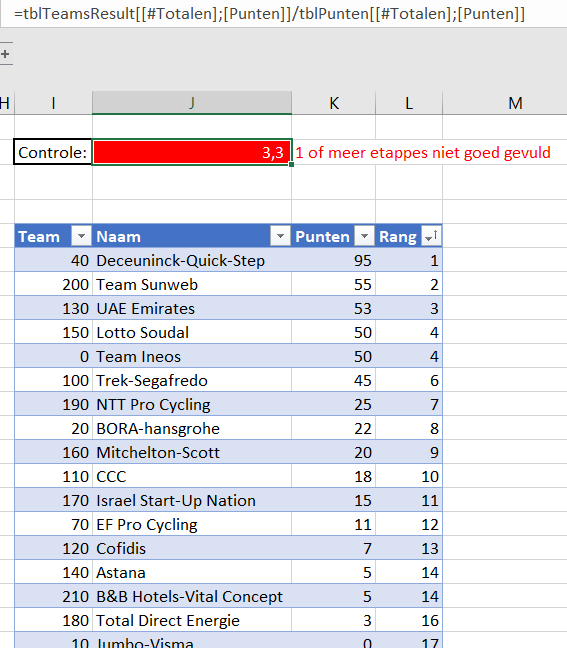
Resultaten per team
In het tabblad Teams van het Voorbeeldbestand wordt op de ondertussen bekende manier per renner de TotaalPunten van die renner opgehaald. Het totaal per team berekenen we met een gewone SOM-formule.
In datzelfde tabblad staat ook een ranglijst van de teams. De formules daarin mogen geen verrassing meer zijn.
Boven die tabel staat een controlegetal: het totaal aantal punten van alle renners gedeeld door het totaal aantal dat per etappe verdiend kan worden. Dit moet een geheel getal zijn. Met voorwaardelijke opmaak krijgt de cel een kleur.
Resultaten per land
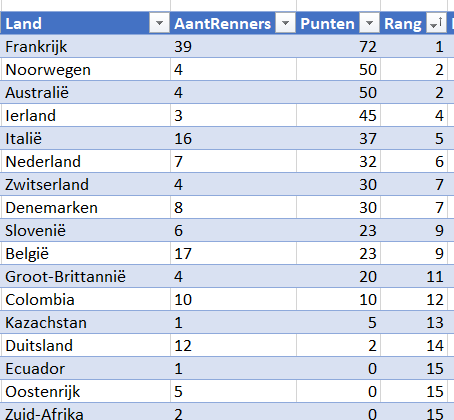
Om het totaal aantal punten per land te bepalen gebruiken we op het tabblad Landen van het Voorbeeldbestand de formule:
=SOM.ALS(tblRenners[Land];[@Land];tblRenners[TotaalPunten])
LET OP gebruik de gegevens van tblRenners en niet van tblTeams anders worden ook de totalen van de teams meegeteld.
Frankrijk heeft de meeste renners rond rijden, logisch (?) dat dit land dan bovenaan staat.
We delen het aantal punten door het aantal renners per land en we krijgen een andere ranglijst.
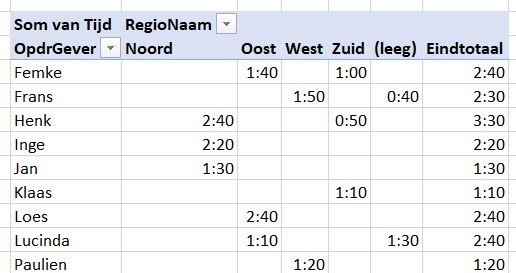
Resultaten per land en team
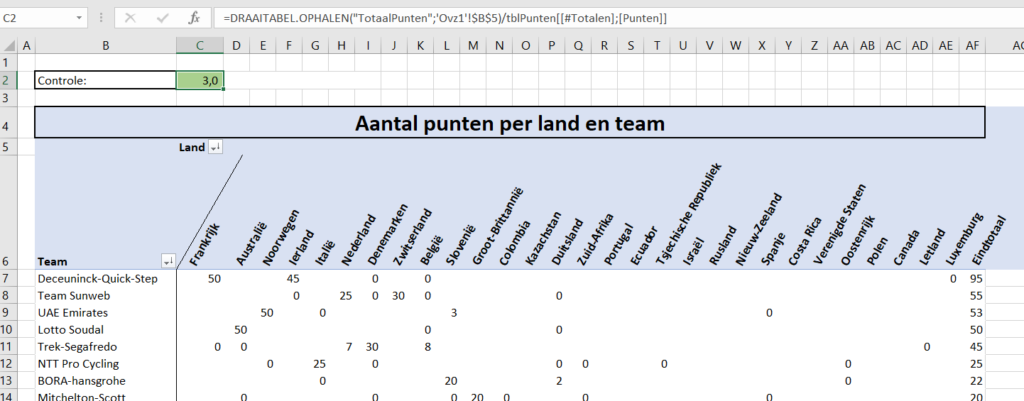
In het tabblad OvzLandTeam van het Voorbeeldbestand staat een draaitabel op basis van de tabel tblRenners. En de rijen én de kolommen worden daarin automatisch gesorteerd (zie ook het artikel Kindernamen).
Bovenin ziet u ook weer een controlegetal; als de uitslagen compleet zijn ingevuld zal dit een geheel getal zijn.
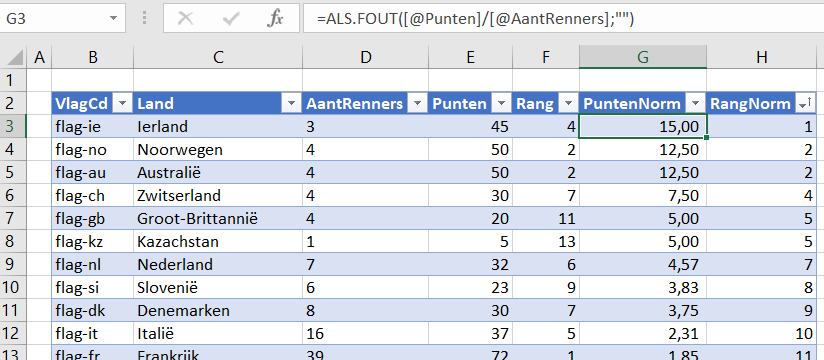
Genormeerde resultaten per land
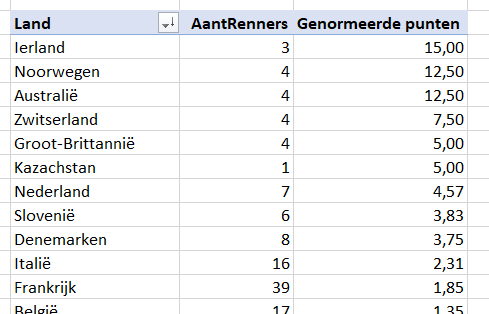
Het tabblad OvzLandTeam van het Voorbeeldbestand bevat ook een draaitabel, nu op basis van de tabel tblLand.
Per land wordt het aantal renners geteld met daarnaast het aantal genormeerde punten (ofwel het totaal aantal punten gedeeld door het aantal renners).
NB in het hele Tour de France-systeem worden alle overzichten direct geactualiseerd na invoer van een uitslag, omdat die allemaal met formules zijn opgebouwd. Dat geldt niet voor de 2 Ovz-tabbladen: dat zijn draaitabellen en die moeten na het opvoeren van nieuwe uitslagen handmatig Vernieuwd worden (met de muis rechtsklikken op een cel in de draaitabel).
LET OP allebei de draaitabellen dienen Vernieuwd te worden aangezien ze op verschillende bronnen zijn gebaseerd.