LET OP: na het downloaden de extensie wijzigen in xlsb
In het vorige artikel (Grenzen aan de groei – 1) hebben we beloofd dat we een poging zouden wagen om het model uit het rapport van de Club van Rome in Excel te implementeren, althans een vereenvoudigde versie daarvan. In dat artikel is te lezen hoe we dat zouden willen doen en aan de hand van wat vingeroefeningen hebben we laten zien dat het (in theorie) mogelijk zou moeten zijn.
Die laatste conclusie staat nog steeds, maar helaas hebben we wel moeten constateren dat de hoeveelheid verbanden tussen de diverse variabelen en de daarbij behorende parameters zo groot is dat een totale implementatie heel erg veel tijd gaat kosten. Dus deze keer vormt het Voorbeeldbestand geen afgerond project. In dit artikel zullen we laten zien hoe ver we gekomen zijn en welke Excel-opties daarbij zijn gebruikt.
Voor eenieder de uitdaging om de ‘handdoek in de ring’ weer op te rapen en het model verder uit te werken!
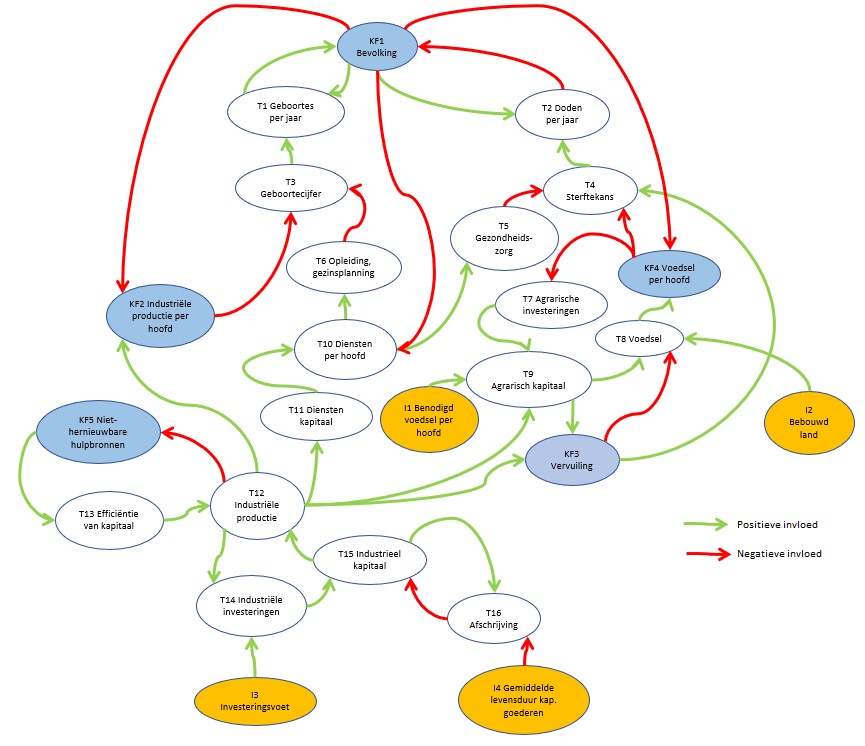
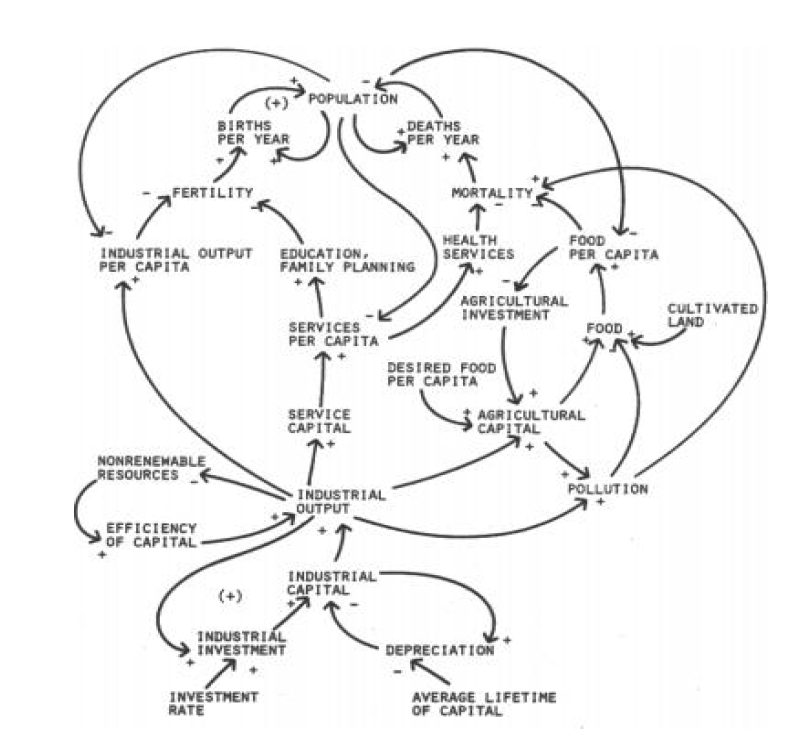
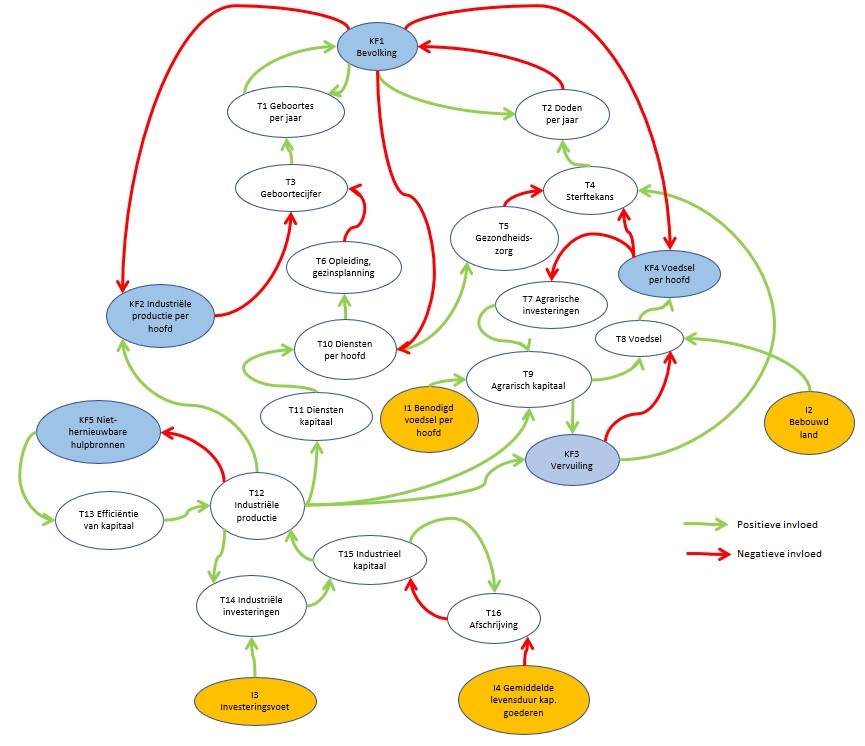
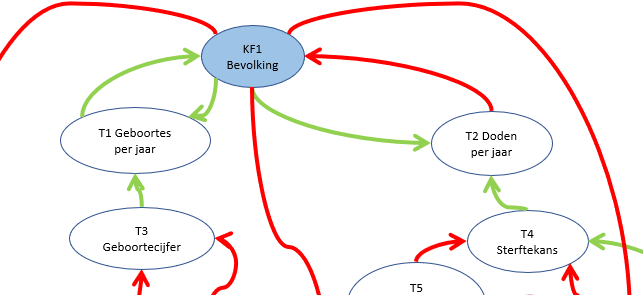
Dit is een schematische weergave van het (vereenvoudigde) ‘Club van Rome’-model; voor nadere uitleg zie het vorige artikel.
Belangrijk om te weten is het volgende:
de pijlen geven aan welke relaties er tussen de variabelen zijn onderkend
de pijlen laten zien in ‘welke richting’ de beïnvloeding loopt
we onderkennen in het model 3 soorten variabelen: de Inputs, de Kritische Factoren en de Tussen-variabelen. De Input-variabelen worden niet beïnvloed door de omgeving, maar kunnen wel in de loop van de jaren variëren. De KF’s zijn die 5 variabelen die in alle grafieken van het rapport terugkomen. Alle overige vallen onder de categorie Tussen-variabelen.
het rapport van de Club van Rome is in 1972 gepubliceerd; waar in dit artikel naar het verleden wordt verwezen bedoelen we dan ook de periode van 1900 tot en met 1970.
voor diverse variabelen is in de literatuur (zie het tabblad Docu van het Voorbeeldbestand) te achterhalen wat de waardes in het verleden zijn geweest. Dit is de eerste basis van de implementatie van het model.
bij de verdere implementatie heeft iedere variabele een eigen tabblad gekregen (behalve de Inputs; zie hierna). Alle aannames voor de berekening van een variabele staan in het betreffende tabblad vermeld. Vaak is daar ook een grafiek opgenomen van die variabele om snel het resultaat van de aannames te controleren.
Tabblad T15
Implementatie
Tabblad Beschr
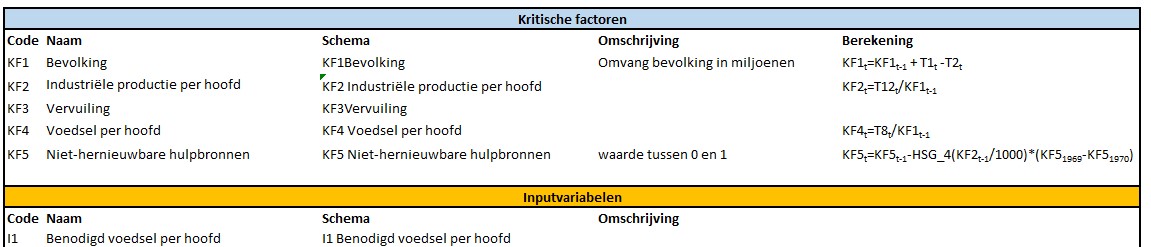
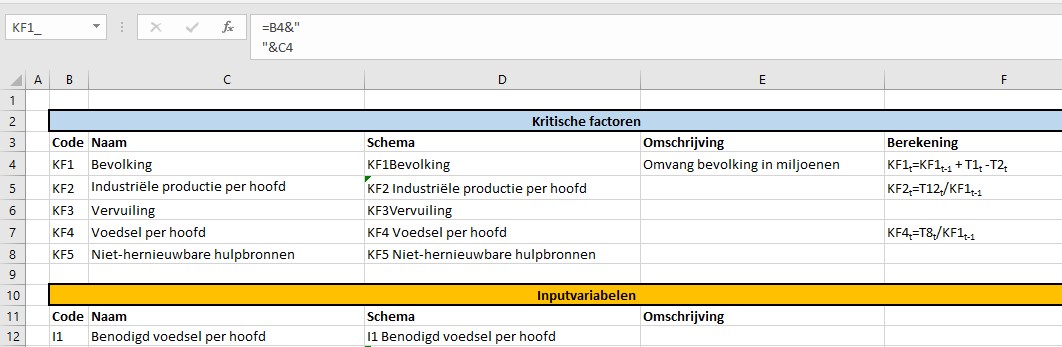
In dit tabblad van het Voorbeeldbestand staat een overzicht van alle gebruikte variabelen met daarbij (zover al uitgezocht) de meest relevante berekening:
De betekenis van de Code en de Naam moge duidelijk zijn; de kolom Schema bevat de tekst zoals die op het tabblad SystemDynamics wordt gebruikt. In de kolom Omschrijving staat in het kort een nadere toelichting op de variabele en de laatste kolom bevat de (belangrijkste) formule voor de berekening van die variabele.
NB de codes onder de 10 voor de Tussenvariabelen hebben een extra 0 gekregen; dit om bij standaard-sorteringen altijd direct de juiste volgorde te hebben (anders zou bijvoorbeeld T10 vóór T2 komen).
Tabblad Inputs
Dit tabblad bevat de gegevens van de 4 Input-variabelen. Deze vormen samen de Excel-tabel tblInputs.
Op dit moment zijn alleen de I3 en I4 gevuld en per kolom hebben alle jaren dezelfde waarde. De juiste interpretatie van deze variabelen vergt nog onderzoek.
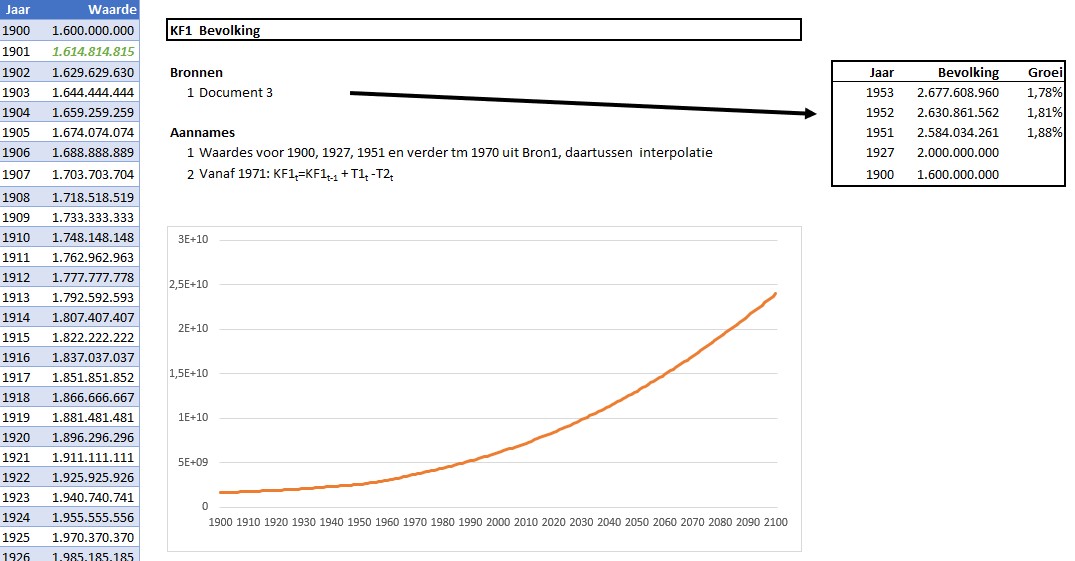
De KF-tabbladen
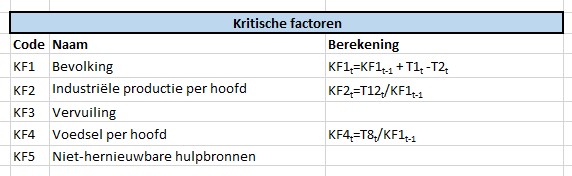
Zoals gezegd hebben alle KF’s (en ook de Tussen-variabelen) een eigen tabblad. Deze bladen hebben allemaal dezelfde structuur: de eerste kolom bevat de jaren en de tweede kolom de daarbij behorende waarde. Samen vormen deze 2 kolommen een Excel-tabel met een overeenkomende naam (in bovenstaand voorbeeld tblKF1).
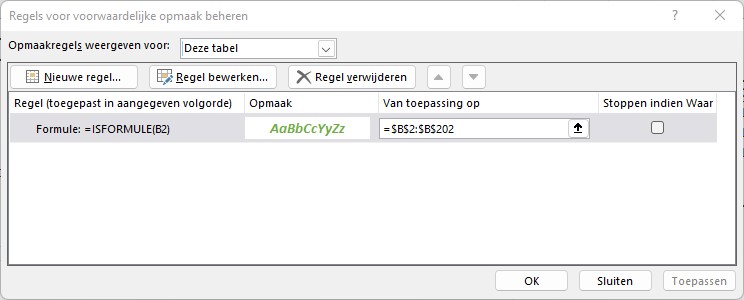
NB de waarde-kolom heeft een voorwaardelijke opmaak: wanneer een cel een formule bevat dan wordt de inhoud in het groen, vet en cursief weergegeven.
In de volgende kolommen staat altijd de code en naam van de variabele, eventueel gebruikte bronnen en de diverse aannames. De rest van het tabblad wordt gebruikt om zo nodig extra berekeningen uit te voeren, de aannames toe te lichten etcetera.
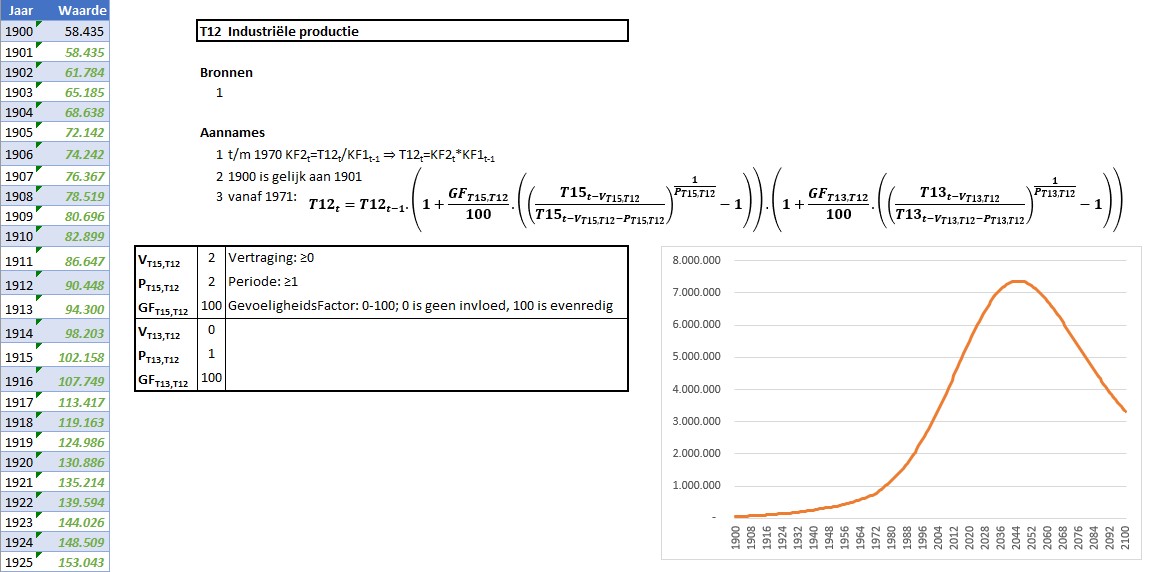
Zoals aangegeven hebben deze tabbladen dezelfde structuur als de KF’s. In het voorbeeld hierboven is te zien dat voor T12 een formule wordt gebruikt, waarbij de gevoeligheid (GF) voor de invloed van een variabele kan worden ingesteld. Daarnaast kan aangegeven worden of de beïnvloeding een vertraging V kent en of er over een periode P gemiddeld moet worden (zie het artikel Grenzen aan de groei – 1).
LET OP in dat artikel hebben we, bij het gebruik van een periode, een rekenkundig gemiddelde gebruikt. Dat is, theoretisch gezien, niet juist. Hoewel dat in dit model, bij niet te grote ontwikkelingen in de tijd, niet echt relevant is, hebben we toch de betere methode gehanteerd waarbij het gemiddelde wordt bepaald met behulp van de Pde-machts wortel (ofwel tot de macht 1/P).
Resultaten
In principe zijn de resultaten van het model bekend als alle tabbladen zijn gevuld met waardes en formules. Door ’te spelen’ met de aannames, en vooral met de eventuele GF-, V– en P-waardes kan het model gefinetuned worden.
We zijn gestart met de onderkant van het model, het gedeelte rond de Industriële productie. De bovenkant is op de uitkomsten daarvan gebaseerd. Het implementeren van deze onderkant heeft heel wat hoofdbrekens gekost (wat is de betekenis van de variabelen, hoe zijn deze variabelen van elkaar afhankelijk, hoe kunnen we de afhankelijkheid modelleren, welke GF-, V– en P-waardes geven een zo getrouw mogelijk beeld van de werkelijkheid etcetera).
Door tijdgebrek moet G-Info het verder vullen van het model dan ook aan anderen overlaten.
Wel zullen we hieronder nog laten zien op welke manier de resultaten in Excel gemakkelijk kunnen worden weergegeven.
Tabblad Variabelen
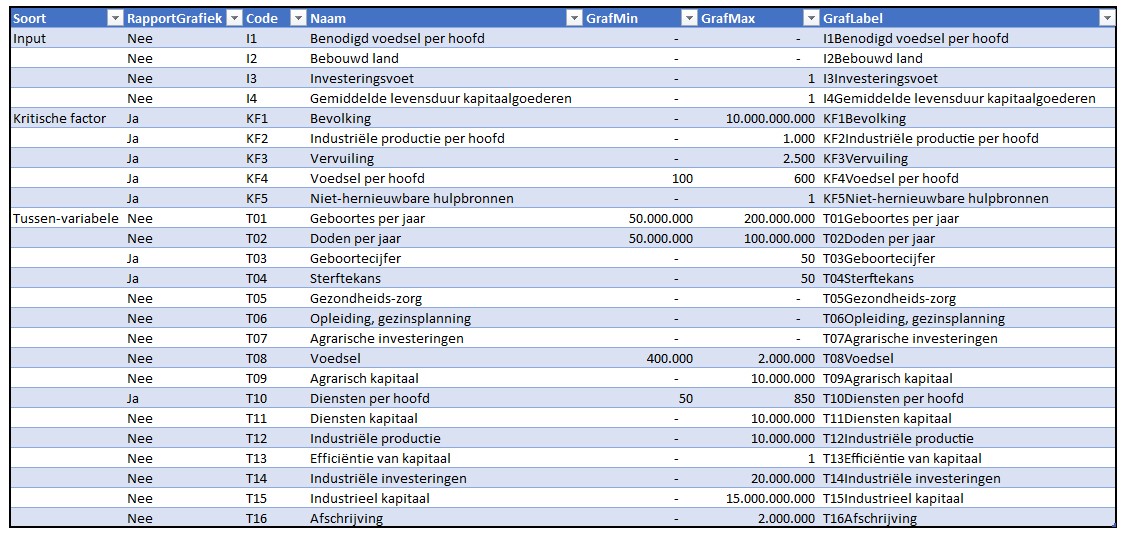
Op dit tabblad in het Voorbeeldbestand staan de 25 variabelen van het model nogmaals in een overzicht. Maar ditmaal met aanvullende gegevens, waarmee we de lay-out van de output kunnen sturen:
in de eerste kolom staat aangegeven welk soort variabele het betreft: Input, KF of Tussen
de tweede kolom geeft aan of de betreffende variabele in de standaard-grafieken van het rapport van de Club van Rome is opgenomen
in dat rapport wordt een variabele altijd op dezelfde (onzichtbare) schaal weergegeven. Dat kunnen we nabootsen door aan te geven welke waarde van de variabele overeenkomt met de onderkant van het grafiekgebied (de kolom GrafMin) en welke waarde met de bovenkant (GrafMax)
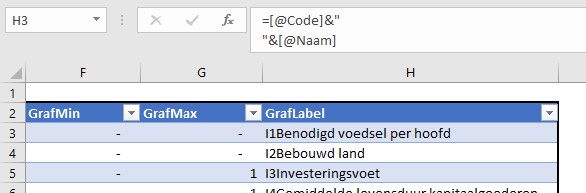
in de laatste kolom staat een formule waarmee het label bij de betreffende lijn in de grafiek wordt bepaald. Standaard is het een combinatie van de 3e en 4e kolom, gescheiden door een ‘harde return’:
Dit overzicht is een Excel-tabel met de naam tblVar.
Query’s en verbindingen
Alle resultaten moeten nu nog geschaald worden. Dit kan uiteraard op de diverse tabbladen zelf door extra kolommen toe te voegen, maar we hebben er voor gekozen om dit met behulp van Power Query te implementeren.
NB1 Ziet u de Excel-verbindingen aan de rechterkant van het scherm niet, kies dan in de menutab Gegevens de optie Query’s en verbindingen.
Voor alle Excel-tabellen is een verbinding gemaakt. Wil je bekijken hoe die er uit ziet? Klik rechts op een verbinding en kies de optie Bewerken (of dubbel-klik op een query-naam).
NB2 de Input-query’s zijn iets ingewikkelder omdat daar één specifieke kolom uit de input-tabel moet worden opgehaald.
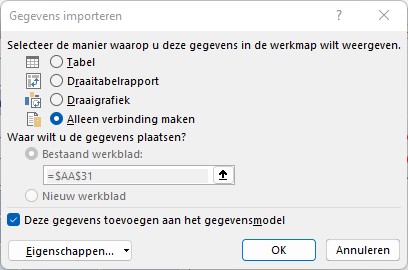
Bij het bewaren van de query’s is de optie Alleen verbinding maken gekozen en is de optie Toevoegen aan gegevensmodel aangevinkt. Die laatste optie zorgt er voor dat de query’s in het gegevensmodel van deze Excel-sheet worden opgeslagen.
Het gegevensmodel bevat nog één extra query, q_GrafData. Deze combineert alle andere verbindingen tot één database. Deze database vormt de basis voor een draaitabel en een daarbij behorende grafiek. Ook deze query is opgeslagen met de eigenschappen Alleen verbinding en Toevoegen aan gegevensmodel.
Bekijk de query door dubbelklikken op de naam.
Tabblad GrafData
Op het tabblad GrafData van het Voorbeeldbestand staat een draaitabel, gebaseerd op de query q_GrafData. Hoe genereer je zo’n draaitabel?
selecteer een lege cel, waar de draaitabel moet komen
kies in de menutab Invoegen in het blok Tabellen de optie Draaitabel
in het pop-up scherm ziet u dat Excel het gegevensmodel zal gaan gebruiken:
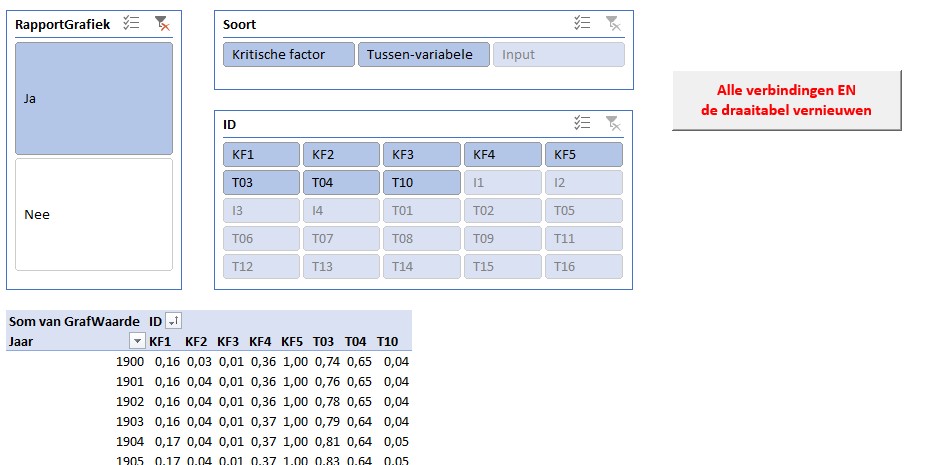
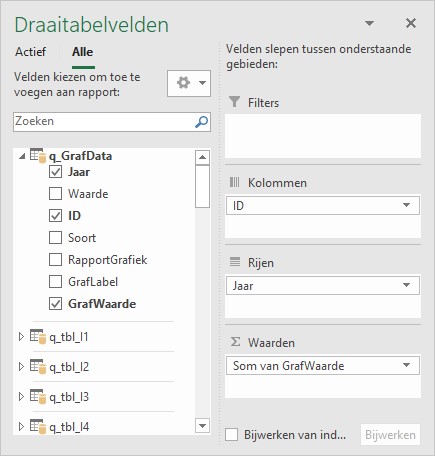
klik op het driehoekje vóór de gewenste query uit het gegevensmodel en sleep de benodigde velden naar de juiste plaats:
In het voorbeeld hebben we ook 3 slicers toegevoegd waarmee het maken van keuzes vergemakkelijkt wordt. Hierboven hebben we met een klik op Ja in de eerste slicer alleen die variabelen geselecteerd, die ook in het rapport van de Club van Rome in de standaard-grafieken voorkomen.
LET OP als er iets aan de parameters van het model wordt gewijzigd dan worden de gegevens op het betreffende tabblad direct gewijzigd. Ook resultaten van formules op andere tabbladen kunnen daardoor wijzigen. De query’s en de draaitabel wijzigen niet automatisch mee! Alles zal vernieuwd moeten worden. Op het tabblad GrafData wordt met één klik op de betreffende button een VBA-routine gestart die deze totale verversing van het Excel-systeem voor zijn rekening neemt. Dit kan wel enkele minuten duren!
Tabblad Grafiek
Het tabblad Grafiek van het Voorbeeldbestand bevat een draaitabelgrafiek. Dit is de grafische weergave van de gegevens van de draaitabel van het tabblad GrafData. Dus: ook keuzes gemaakt met de slicers worden in deze grafiek meegenomen.
Duidelijk is te zien dat de implementatie van het model nog lang niet klaar is. De industriële productie en de hulpbronnen geven bijvoorbeeld wel al een verwacht verloop, terwijl de blijvende toename van de bevolking of voedsel per hoofd niet reëel is. Het model in het Voorbeeldbestand is dan ook nog maar voor een klein gedeelte geïmplementeerd. Zoals gezegd: tijdgebrek noopt ons om de rest aan andere Excel-liefhebbers over te laten.
LET OP: na het downloaden de extensie wijzigen in xlsb
De oudere jongeren onder ons (of de jongere ouderen?) weten het nog wel: in 1972 (50 jaar geleden) verscheen het Rapport van de Club van Rome met als ondertitel De grenzen aan de groei.
Een pocketboekje dat een intensieve discussie op gang heeft gebracht: voor sommige mensen was het een eye-opener (we kunnen niet blijven doorgaan met het ongelimiteerd opsouperen van onze hulpbronnen, we moeten ‘de groei’ temperen), anderen wezen er op dat je met het onderliggende model alles kunt bewijzen (een Eindhovense professor formuleerde dat als ‘Met dit model kun je ook je eigen handtekening maken; een kwestie van de parameters aanpassen aan je wensen‘).
In het vorige artikel van G-Info is een voorbeeld uit het rapport langs gekomen om te laten zien hoe je Vergelijkingen/formules in Excel kunt schrijven. Een losse opmerking daarbij (‘Zou het model in Excel nagebouwd kunnen worden?“) is het begin van een zoektocht geworden. Gelukkig kwam daarbij al snel een vereenvoudigd model naar boven. Het begin van een uitdaging: kan dit model in Excel op een zodanige manier geïmplementeerd worden, dat in ieder geval de resultaten van de Club van Rome gereproduceerd worden?
In dit artikel eerst een korte achtergrond van het Rapport van de Club van Rome, een uitleg van het vereenvoudigde model en daarna wat vingeroefeningen om te laten zien hoe we denken dat de implementatie er uit kan gaan zien.
Rapport van de Club van Rome
Wikipedia: “De grenzen aan de groei is een rapport van de Club van Rome uit 1972 waarin de uitputtingsproblematiek centraal staat. Het rapport werd uitgewerkt door een team van het Massachusetts Institute of Technology (MIT) onder leiding van Dennis Meadows en Donella Meadows. Het rapport heeft grote invloed gehad op het milieubewustzijn.
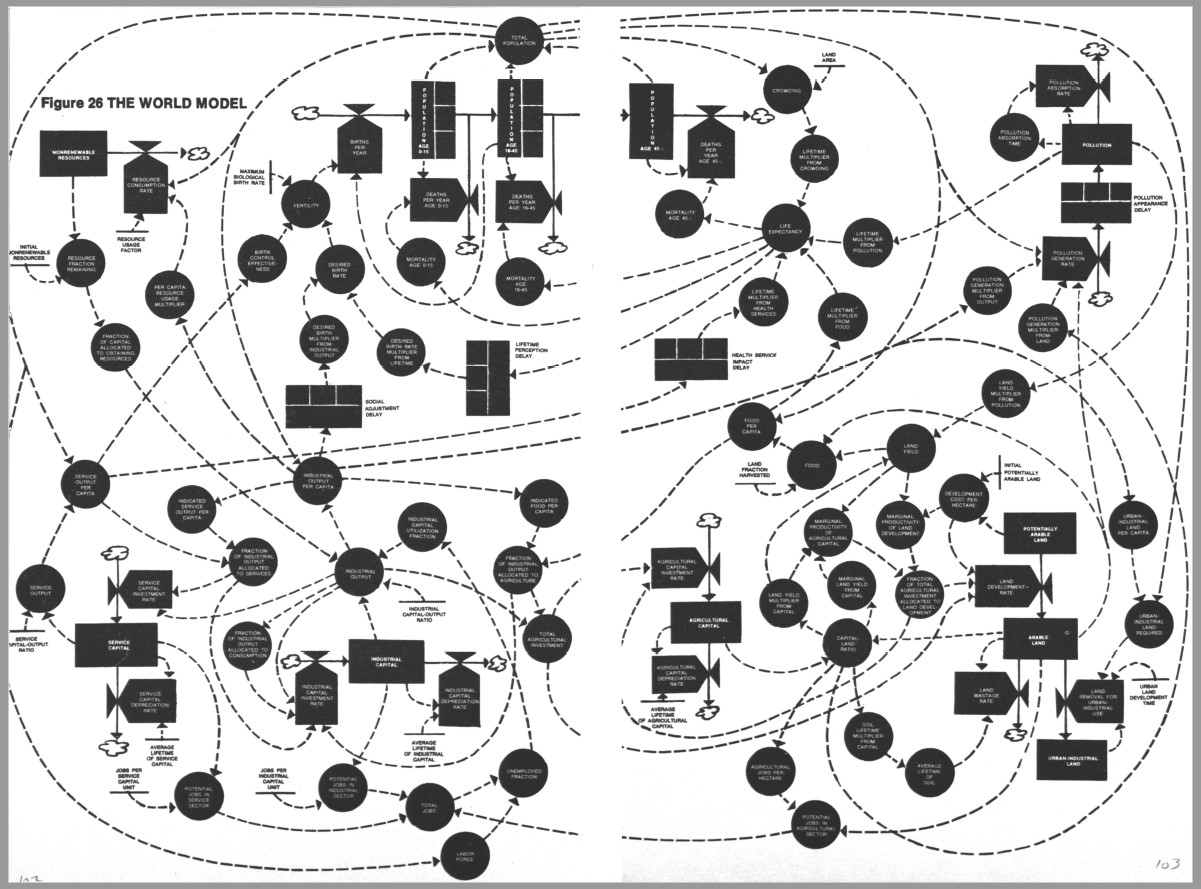
Aan de basis van de studie ligt het gebruik van een systeemdynamisch model met computersimulatie van interacties tussen bevolking, industriële groei, voedselproductie en limieten in de ecosystemen van de aarde: het World3-model, mede ontwikkeld door Jay Forrester. Van deze variabelen werd de ontwikkeling van 1900 tot 1970 vastgesteld. Vervolgens werden de trends voortgezet, waarbij verschillende aannames werden gedaan. Ervan uitgaande dat geen belangrijke veranderingen plaats zouden vinden in de fysieke, economische en sociale relaties (het referentie scenario) waren de uitkomsten schokkend. De natuurlijke hulpbronnen zouden gaandeweg uitgeput raken en de industriële groei remmen. De bevolkingsomvang en vervuiling zouden nog enige tijd toenemen, maar de verslechtering van de voedselvoorziening en de gezondheidszorg leidden in eerste instantie tot stilstand en later tot terugloop in de bevolkingsgroei.“
Het rapport was niet zozeer bedoeld om kwantitatieve voorspellingen over de toekomst te doen (de leden van de Club en MIT’ers beseften terdege dat het model daarvoor veel te globaal en simpel was). Het diende als input voor de discussie over de groei van de wereldbevolking, ons consumptiepatroon en het gebruik van de natuurlijke grondstoffen en het effect van milieuvervuiling.
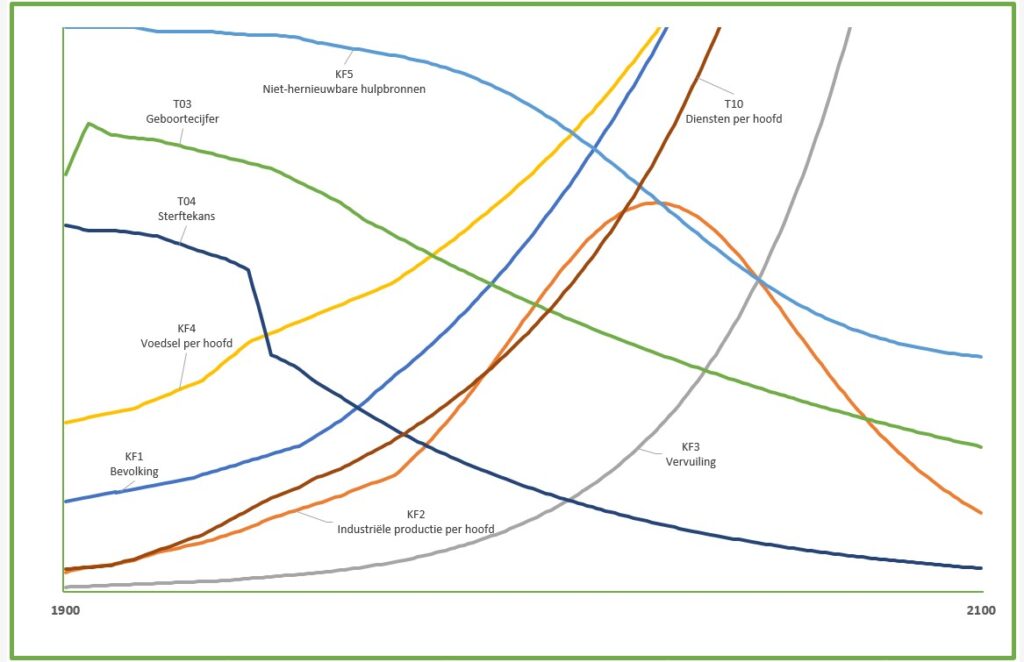
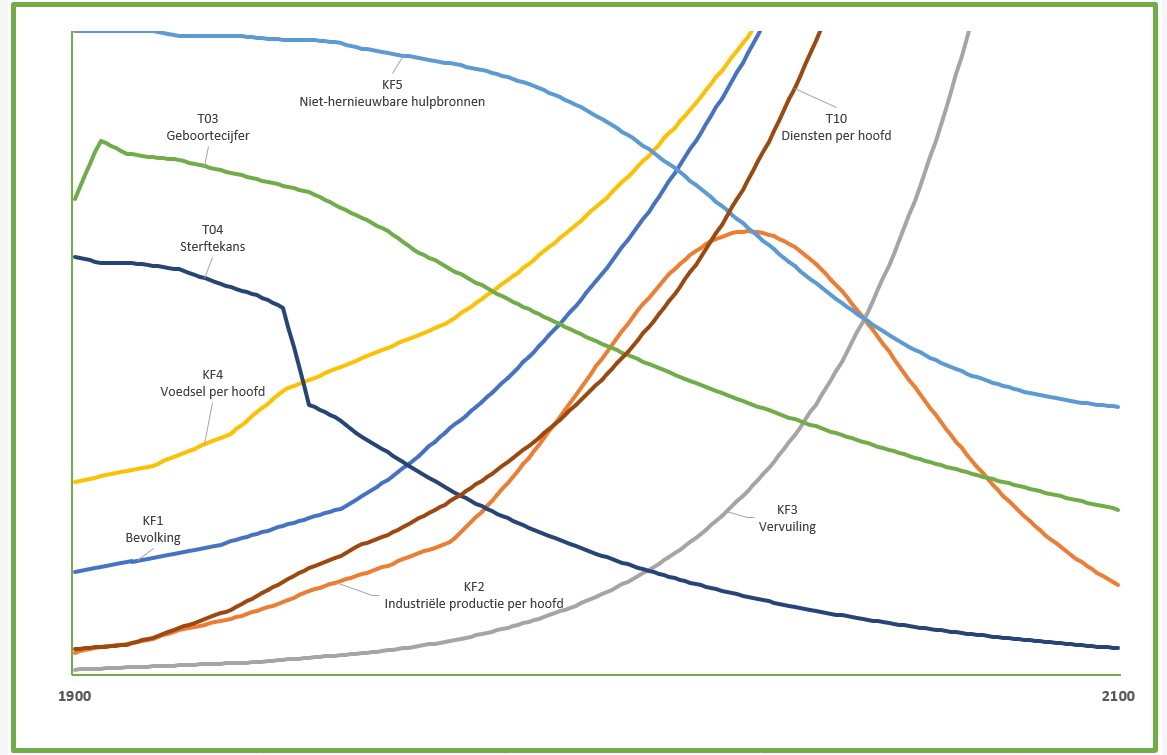
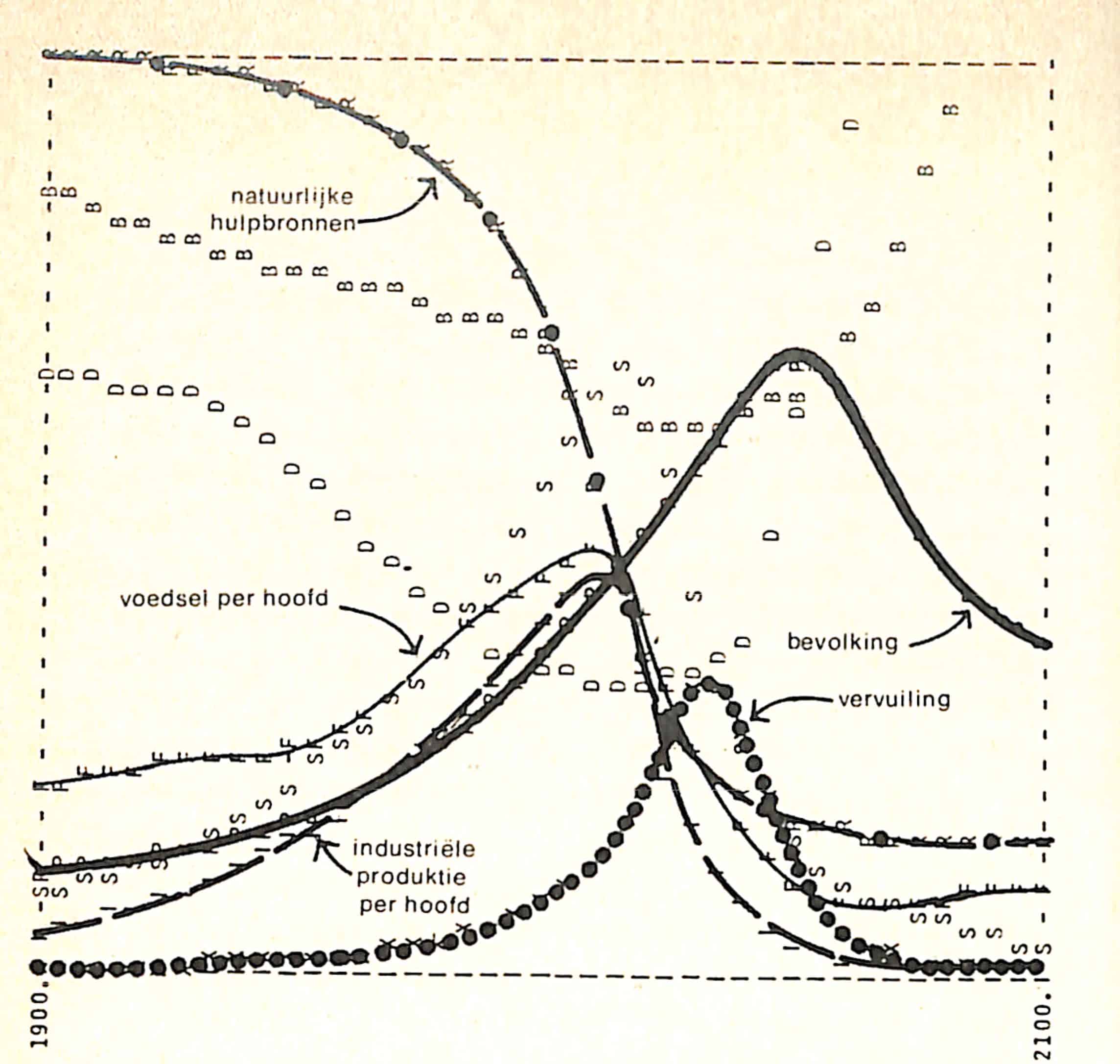
Het model is doorgerekend met diverse scenario’s. Hiernaast staat een grafische weergave van het resultaat van het standaard BAU-scenario (Bussiness As Usual). Daarin volgen alle variabelen van 1900 tot 1970 de historische waarden. De rest is door het model berekend op basis van de aanname dat “er geen belangrijke veranderingen plaatsvinden in de fysieke, economische of sociale relaties.“
De grafieken werden weergegeven door letters, waarna de belangrijkste variabelen met de hand werden ingetekend; B stelt het geboortecijfer voor, D het sterftecijfer en S de diensten per hoofd. Uit het rapport: “Elk van de variabelen is uitgezet op een verschillende schaalverdeling. We hebben met opzet de verticale schaalverdelingen weggelaten en de horizontale tijdas geen indeling gegeven, omdat we de nadruk willen leggen op de algemene gedragspatronen, niet op de numerieke waarden die slechts onnauwkeurig bekend zijn. Maar de schalen zijn in alle scenario’s gelijk, zodat de grafieken gemakkelijk vergeleken kunnen worden.“
Iedereen die geïnteresseerd is in de resultaten van de scenario’s moeten we doorverwijzen naar diverse publicaties. De Nederlandstalige versie van het rapport is nog te koop, de Engelstalige versie is in PDF-versie te downloaden.
Het idee om eens te kijken of we met Excel het BAU-scenario zouden kunnen reproduceren, leek bij bestudering van deze info niet haalbaar. Totdat ….
Een vereenvoudigd model
Bij de zoektocht op internet kwam ik een studie tegen waarin de resultaten van het oorspronkelijke model vergeleken werden met recente data. Ook is daar een vereenvoudigd model te vinden.
Dit model bestaat uit 25 variabelen. Dat moet te doen zijn en ook het aantal verbanden daartussen lijkt behapbaar.
Misschien dat het toch gaat lukken om de resultaten uit 1972 te reproduceren! En dat dan niet alleen: misschien kunnen we de diverse parameters in het model zodanig aanpassen, dat we weten hoe we de wereld de juiste kant op kunnen sturen 😉
Op het tabblad SystemDynamics van het Voorbeeldbestand ziet u een aangepaste vorm van dit vereenvoudigde model:
Bovenstaand model is in Excel gemaakt met 2 soorten vormen: Ovalen en Gekromde pijlen.
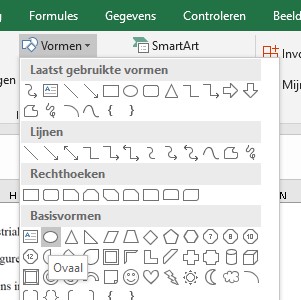
Kies in de menutab Invoegen in het blok Illustraties de optie Vormen.
Selecteer de gewenste vorm en ’teken’ met de muis ongeveer op de plaats waar deze moet komen.
Pas in de menutab Hulpmiddelen voor tekenen de Opmaak aan.
De ovalen zijn gemakkelijk groter en kleiner te maken door middel van de rondjes aan de zijkanten. Bovenin zit een greep waarmee de vorm gedraaid kan worden.
De plaats en de vorm van de pijlen kunnen via de 3 bolletjes aangepast worden. Zorg wel dat de uiteinden van de pijl precies op één van de 8 rondjes van een ovaal terecht komen (het resultaat is dan een dicht zwart bolletje). Wanneer je achteraf een vorm verschuift zal de pijl meebewegen.
Je kunt een tekst in een ovaal plaatsen door daarin te dubbel-klikken en dan de tekst te tikken. Om de consistentie te bewaken hebben we alle codes en namen in een apart tabblad Beschr vastgelegd. Door nu eenmaal in/op een ovaal te klikken kan in de formulebalk een verwijzing naar een cel in dit tabblad gemaakt worden. De cellen in kolom D worden gebruikt in het model; afhankelijk van de grootte van de tekst plaatsen we tussen de Code en de Naam een spatie of een harde return (druk tussen de aanhalingstekens op Alt-Enter). Alle cellen in kolom D hebben een overeenkomende naam gekregen (bijvoorbeeld cel D4 heeft de naam KF1_; de underscore is nodig omdat Excel anders denkt dat we een verwijzing naar de cel in kolom KF en rij 1 bedoelen).
NB heb je een paar vormen (inclusief opmaak) die voldoen, dan kun je die natuurlijk ook kopiëren. De tekst (en misschien de grootte) aanpassen en je bent klaar.
Variabelen
We onderkennen in het model 3 soorten variabelen: de Inputs, de Kritische Factoren en de Tussen-variabelen. De Input-variabelen worden niet beïnvloed door de omgeving, maar kunnen wel in de loop van de jaren variëren. De KF’s zijn die 5 variabelen die in alle grafieken van het rapport terugkomen. Alle overige hebben de naam Tussen-variabelen gekregen.
Verbanden tussen variabelen
De pijlen in het model geven het verband tussen de diverse variabelen aan. De richting en kleur laten de soort beïnvloeding zien.
1. Lineair of absoluut verband
Tussen sommige variabelen zit een lineair/absoluut verband: variabelen worden bij elkaar opgeteld of op elkaar gedeeld om de waarde van een andere variabele te berekenen.
Bijvoorbeeld, voor de bevolkingsomvang gebruiken we de volgende formule: KF1t=KF1t-1 + T1t -T2t De Bevolkingsgrootte KF1 in jaar t is de grootte in jaar t-1plus de Geboortes T1 in jaar tminus de Sterftes T2 in jaar t. In het model gaat er een groene pijl van T1 naar KF1, een rode van T2 naar KF1.
Een ander absoluut verband zien we bij KF4: KF4t=T8t/KF1t-1. Het Voedsel per hoofd KF4 in jaar t is gelijk aan de Hoeveelheid voedsel T8 in jaar t gedeeld door de Bevolkingsgrootte KF1 in jaar t-1. Hoe groter T8 hoe groter KF4 (dus een groene pijl in het model), hoe groter KF1 hoe kleiner KF4 (een rode pijl).
NB we kiezen er voor om te delen door de bevolkingsgrootte in het jaar t-1, omdat we anders het risico lopen op een kringverwijzing: KF4 heeft invloed op de sterftekans T4 en die bepaalt weer de bevolkingsgrootte.
2. Relatief verband
Maar de meeste pijlen in het model vertegenwoordigen een ingewikkelder verband tussen de variabelen. We kunnen bijvoorbeeld niet zeggen dat we de hoeveelheid gezondheidszorg ergens van af trekken om tot een sterftekans te komen.
Maar het is wel aannemelijk dat als de gezondheidszorg van jaar op jaar toeneemt dat dan de sterftekans afneemt (los van andere variabelen). In formulevorm: ofwel
NB1 Hoe sterk de invloed van de gezondheidszorg op de sterftekans is, wordt door α bepaald.
NB2 hadden we te maken met een positieve invloed (een groene pijl) dan hadden we de teller en noemer bij T5 omgewisseld.
LET OP We zullen hierna zien dat deze vorm meestal nog te eenvoudig is om het verband tussen variabelen goed te modelleren.
Zoals het er nu uitziet kunnen we het model op basis van deze 2 soorten verbanden gaan beschrijven. In een volgend artikel zal kolom F in het tabblad Beschr van het Voorbeeldbestand gevuld worden met alle gebruikte rekenregels.
Exponentiële groei
Eén van de belangrijkste oorzaken voor de schokkende resultaten van de MIT-studie is gelegen in het feit dat in onze wereld (in ieder geval in het gehanteerde wereld-model) diverse variabelen de neiging hebben tot een exponentiële groei. De belangrijkste daarvan is de bevolking. Hoe dat komt zullen we hierna bekijken.
Waarschijnlijk de bekendste vorm van exponentiële groei heeft te maken met onze financiën.
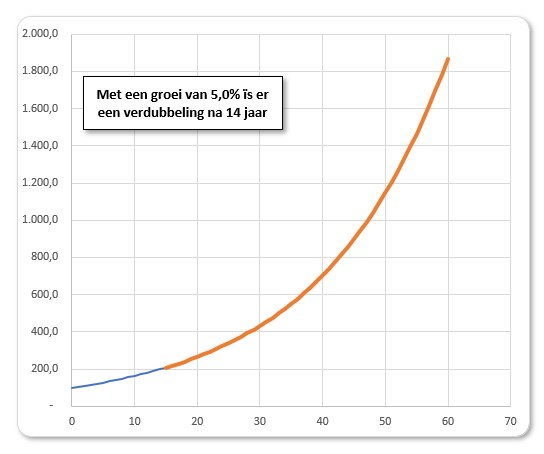
Stel we beginnen met € 100; wanneer we jaarlijks 5% rente krijgen (dat was ooit!) dan hoeven we niet 20 jaar te wachten tot het bedrag verdubbeld is, maar slechts 14 jaar. Dit door het effect van rente op rente. Wacht je dan nog eens 14 jaar dan heb je al 4 keer zoveel.
Op het tabblad ExpGroei van het Voorbeeldbestand kun je met het percentage ‘spelen’ om te zien wat het effect daarvan is. De bijbehorende grafiek past zich automatisch aan.
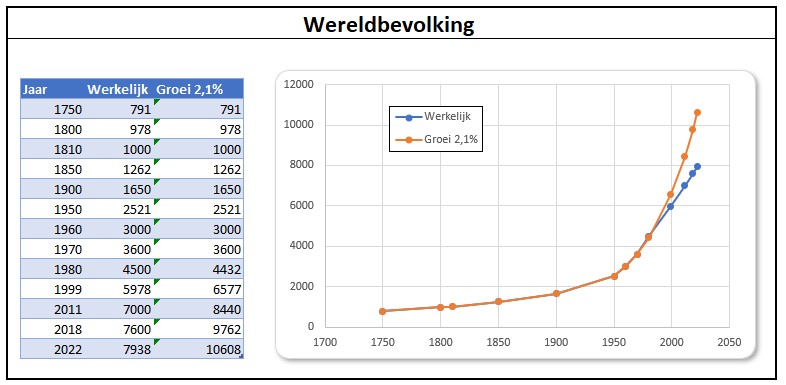
In 1970 was de groeivoet van de wereldbevolking 2,1%. Dit zou een verdubbeling betekenen na 33 jaar. In de grafiek op het tabblad ExpGroei staan de werkelijke groei en de groei met 2,1% vanaf 1970 naast elkaar. Daar valt uit af te leiden dat de groeivoet is gedaald in de loop van de tijd. De consequentie daarvan is dat de verdubbeling niet heeft plaats gevonden in 2003 maar ‘pas’ in 2013.
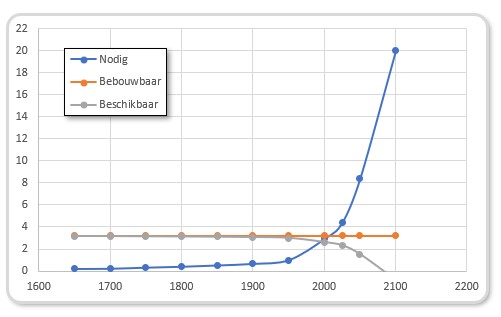
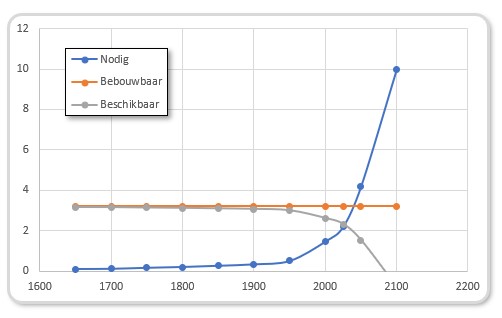
Bebouwbare grond
Eén van de vele consequenties van de exponentiële groei van de bevolking zien we terug bij de verwachting van de beschikbaarheid van voldoende landbouwgrond.
Volgens de Club van Rome was er in 1970 3,2 miljard ha grond beschikbaar voor landbouw. De verwachting was ook dat dat in de toekomst niet significant zou toenemen; dat zou economisch niet rendabel zijn. Op dat moment was er wereldwijd per persoon 0,4 ha nodig om voldoende voedsel te kunnen verbouwen (ter illustratie: in de US werd er toen 0,9 ha pp gebruikt). In het rapport is er ook rekening mee gehouden dat er per persoon 0,08 ha van de beschikbare bouwgrond nodig was voor bewoning en andere infrastructuur.
In het tabblad Bebouwbaar van het Voorbeeldbestand is in de grafiek te zien dat er lang (ruim) voldoende grond was om voedsel te verbouwen. Maar door de exponentiële groei van de bevolking stijgt de benodigde hoeveelheid grond na 1970 snel, terwijl de beschikbare hoeveelheid vanaf dat moment versneld gaat afnemen. De 2 lijnen snijden elkaar ongeveer in het jaar 2000.
Gelukkig is die ‘voorspelling’ niet bewaarheid. Waarschijnlijk door een efficiënter gebruik van de grond en de lagere groei van de bevolking. In het tabblad Bebouwbaar kun je de productiviteit aanpassen. Hiernaast staat de grafiek bij een productiviteitsfactor van 2; ofwel er is maar 0,2 ha pp nodig. De 2 lijnen snijden elkaar nu pas in het jaar 2025.
Het mag duidelijk zijn dat een verdere verhoging van de productiviteit en/of verlaging van de groeivoet van de bevolking slechts uitstel betekent tot er niet voldoende landbouwgrond meer is. Gemiddeld over de wereld gaat het nu nog goed, maar mensen in Afrika kijken daar waarschijnlijk al anders tegen aan. Ook de oorlog in Oekraïne laat ons zien, dat een (relatief kleine) verstoring van de normale wereldorde een groot effect op onze voedselvoorziening tot gevolg heeft.
Bevolkingsgroei
In het model, dat we hier hanteren, wordt de grootte van de bevolking alleen bepaald door het aantal geboortes (T1) en doden (T2) per jaar. Zoals hiernaast te zien is bepaalt de grootte van de bevolking (KF1) echter ook weer de aantallen van T1 en T2. Dergelijke terugkoppelingen zien we meer terug in het model en deze zorgen vaak voor het exponentiele karakter van groei.
In het tabblad TerugKoppeling van het Voorbeeldbestand is dit te zien aan de hand van fictieve cijfers.
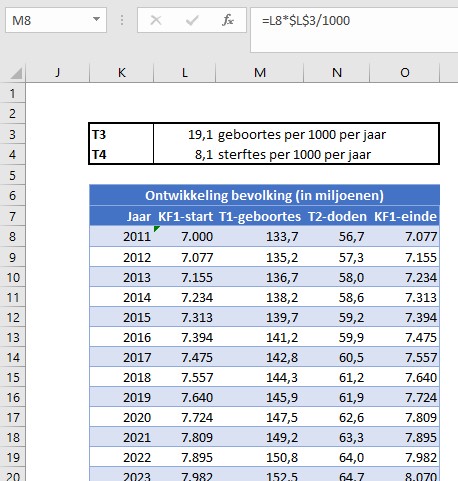
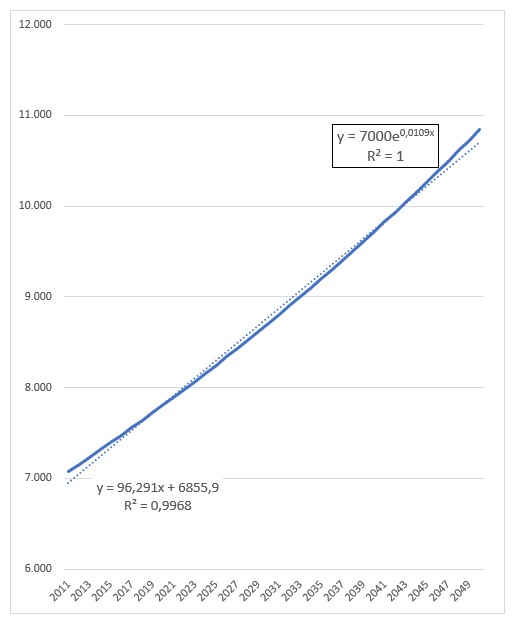
Begin 2011 kende de wereld ongeveer 7 miljard inwoners. Het aantal geboortes per 1000 personen per jaar (Geboortecijfer T3) was toen ongeveer 19,1, terwijl het aantal doden circa 8,1 per 1000 was (Sterftekans T4); de groeivoet van de bevolking per jaar was dus ongeveer 11 per 1000 ofwel 1,1%. Onder de aanname dat T3 en T4 niet veranderen kunnen we gemakkelijk het verloop van de bevolking over de jaren berekenen.
Het verloop is voor 40 jaren berekend en ook in een grafiek uitgezet. We hebben Excel 2 trendlijnen laten bepalen: een lineaire en een exponentiële. De lineaire voldoet met een R2 van 0,9968 (zie het artikel Trend-analyse) prima op het getekende stuk, maar wel is te zien dat als we deze trend zouden gebruiken om te voorspellen dat we al snel uit de pas zouden lopen. De andere trendlijn heeft een R2 van 1 en sluit dus exact aan bij de brongegevens (de trendlijn valt samen met de grafiek zelf). De bevolkingsgroei is dus exponentieel. Op het tabblad ExpGroei kunnen we zien dat een groeivoet van 1,1% betekent dat de bevolking iedere 60 jaar zal verdubbelen.
Vingeroefening 1
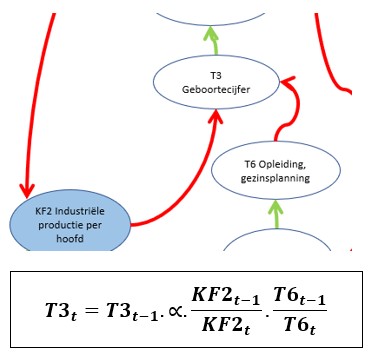
We gaan als eerste eens kijken hoe we de bepaling van het Geboortecijfer T3 kunnen modelleren (zie het tabblad GebCijfer in het Voorbeeldbestand). Zoals te zien is in het schema wordt T3 beïnvloed door de variabelen KF2 (Industriële productie per hoofd) en T6 (opleiding, gezinsplanning). Bij allebei staat een rode pijl. Dat betekent dat een grotere waarde voor KF2 en/of T6 er voor zorgt dat T3 kleiner wordt (in het Club-rapport wordt de achtergrond hiervan kort uitgelegd).
We hebben hier te maken met een relatief verband; hierboven staat de daarbij behorende formule. Maar daar zitten wel wat haken en ogen aan:
de formule bevat één α, waarmee we de gevoeligheid van T3 voor veranderingen in KF2 en T6 kunnen regelen. Maar de gevoeligheid per variabele kan verschillend zijn; dat zouden we zichtbaar willen hebben.
als het gemiddeld opleidingsniveau dit jaar is gestegen ten opzichte van vorig jaar, zal dat niet direct al dit jaar een verandering in T3 geven; daar zit natuurlijk een vertraging in.
een eenmalige grote wijziging in bijvoorbeeld KF2 hoeft niet ook een dergelijk effect te hebben op T3. Het is beter als we een langere periode dan 1 jaar hanteren om de gemiddelde relatieve wijziging te bepalen.
Wanneer we met deze 3 punten rekening houden wordt de formule ‘iets’ ingewikkelder:
iedere variabele heeft zijn eigen gevoeligheidsfactor GF. Omdat er in het model straks veel van dit soort factoren zijn, geven we iedere factor een aanduiding mee op welk verband deze betrekking heeft. Bijvoorbeeld GFKF2,T3 is de gevoeligheid van het verband tussen KF2 en T3. Om decimalen bij de invoer te vermijden schalen we de GF’s tussen 0 en 100. NB als het resultaat van een verband heel sterk wordt beïnvloed door de bron-variabele kan de GF ook groter dan 100 zijn.
de vertraging in het effect wordt door de V-variabelen in de formule bepaald
en de periode door de P’s. NB we bepalen op bovenstaande manier de gemiddelde wijziging tussen het begin en einde van de periode. Voorlopig lijkt dit een goede oplossing, maar misschien blijkt het straks nodig om een gemiddelde over alle wijzigingen in de periode te nemen. Of als het verloop in de periode sterk exponentieel is een nog wat ingewikkelder methode.
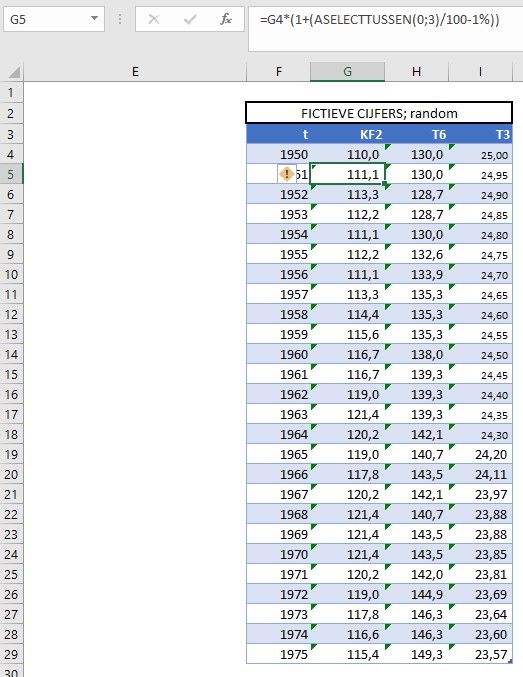
Om wat te kunnen experimenteren staat op het tabblad GebCijfer een tabel met fictieve cijfers over de jaren 1950-1975. De cijfers over 1950 zijn ‘hard’. Met de formule =G4*(1+(ASELECTTUSSEN(0;3)/100-1%)) in cel G5 zorgen we dat KF21951met een waarde tussen -1% en +2% wijzigt ten opzichte van 1950. Op dezelfde manier worden alle cellen in de kolommen G en H met willekeurige waarden gevuld. De waardes voor T3 zijn voor de jaren tot en met 1964 ‘hard’ ingevuld. De niet-harde cellen worden telkens opnieuw berekend wanneer op F9 wordt gedrukt.
In cel I19 staat het eerste resultaat van de berekening volgens bovenstaande systematiek:
de inhoud van cel I18 is de T3 van het vorige jaar
C41 is de waarde van GFKF2,T3
C39 is de VKF2,T3
en C40 is de PKF2,T3
De functie Verschuiving selecteert op basis van (in dit geval) 3 parameters een cel:
de eerste parameter is de start-positie van de selectie; hier de cel in de kolom met de naam T6, die in dezelfde regel staat als de formule ([T6] is de hele tabel-kolom, [@T6] alleen de cel in dezelfde regel).
de tweede is het aantal rijen naar beneden of naar boven voor de daadwerkelijke selectie
en de derde geeft aan of de selectie naar links of rechts ten opzichte van de start-positie moet plaats vinden
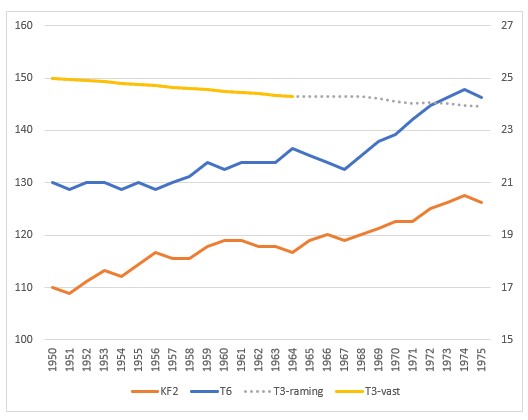
Op het tabblad GebCijfer staat naast de tabel met random-waarden ook een tabel waarin alle waarden in de kolommen KF2 en T6 vast zijn. Op deze manier kun je beter zien wat de consequenties van aanpassingen van de GF-, V– en P-parameters zijn voor het resultaat. De grafieken laten het effect goed zien. Het beoordelen van het resultaat voor wijzigingen in alleen KF2 of T6 kan eenvoudig door de andere GF op 0 in te stellen.
Vingeroefening 2
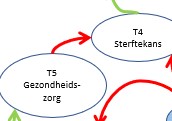
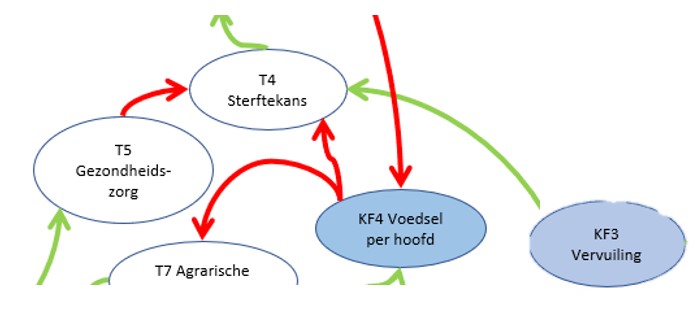
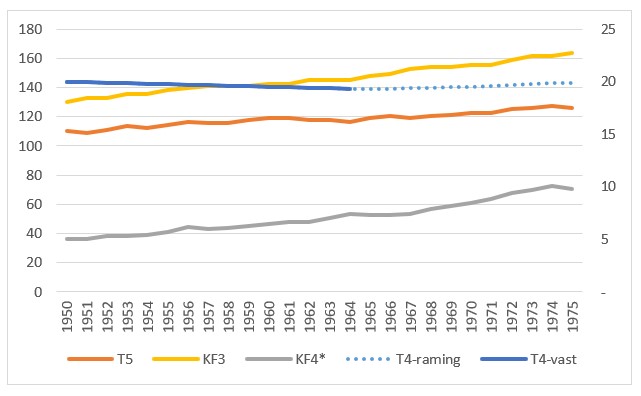
Het tabblad SterfteKans van het Voorbeeldbestand bevat een ander gedeelte van het vereenvoudigde model. We zien hier dat de Sterftekans T4 door 3 variabelen wordt beïnvloed: T5 Gezondheidszorg, KF4 Voedsel per hoofd en KF3 Vervuiling.
We zien 2 rode en 1 groene pijl: als T5 en/of KF4 stijgen zal de sterftekans dalen, maar wanneer de vervuiling toeneemt, neemt ook de T4 toe.
De verbanden tussen de variabelen T5-T4 en KF3-T4 kunnen we modelleren als in de vorige vingeroefening. De relatie tussen KF4 en T4 is ingewikkelder. Wanneer de hoeveelheid voedsel per hoofd blijft stijgen zal dat geen verdere daling van de sterftekans met zich meebrengen (misschien zelfs integendeel).
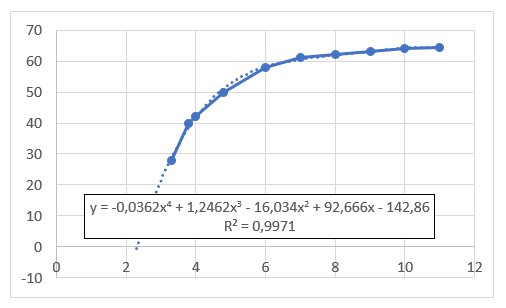
In het Club-rapport is wel een verband gevonden tussen het voedingsniveau (uitgedrukt in groente calorie-equivalenten) en de gemiddelde verwachte levensduur (situatie 1953). Een trendanalyse laat zien, dat dit verband zich goed laat benaderen door een 4e graadsfunctie (tenminste op het relevante stuk met een voedingsniveau tussen 3 en 12). Deze functie zullen we hierna SK_4 noemen.
De formule (zie het tabblad StefteKans) wordt er niet simpeler op! In het tweede blok gebruiken we dus niet de verhouding tussen twee waardes van KF4, maar de verhouding tussen twee uitkomsten van SK_4(KF4*). NB we moeten straks bij de implementatie van het model de waardes van KF4 schalen naar een waarde tussen 3 en 12.
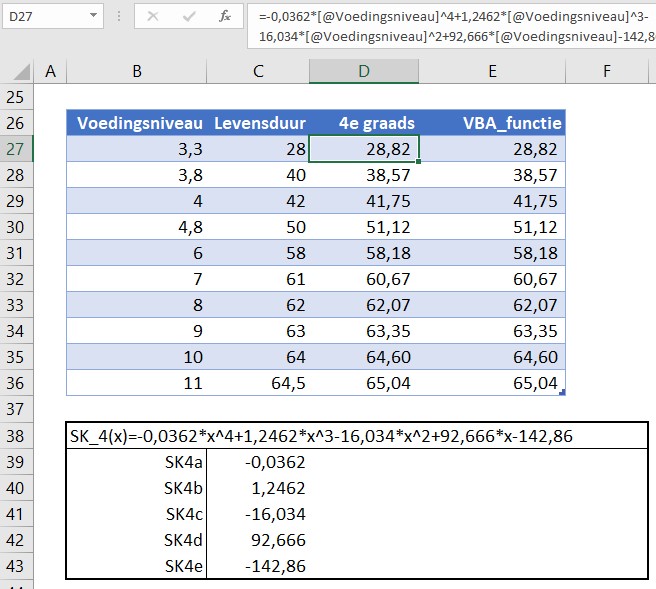
In een tabel op het tabblad SterfteKans hebben we de gegevens uit het Club-rapport overgenomen. In kolom D staat de berekening volgens de 4e graadsfunctie; de verschillen zijn marginaal. Onder de tabel zijn de 5 benodigde parameters voor de functie opgenomen; de cellen hebben overeenstemmende namen gekregen.
Deze namen gebruiken we in de eigen functie SK_4; deze functie zullen we straks in de modelberekeningen gebruiken in plaats van formules met cel-verwijzingen. NB1 voor uitleg over eigen functies, zie het betreffende artikel. NB2 de functie bevat ook een underscore, omdat Excel anders denkt dat het een verwijzing is naar de cel in kolom SK en rij 4.
Ook nu hebben we een overzicht gemaakt met fictieve gegevens. Door met de diverse parameters te spelen krijg je gevoel voor de samenhang tussen de diverse variabelen. De bijbehorende grafiek ondersteunt daarbij.
Het volgende artikel van G-Info zal gewijd zijn aan de implementatie van het vereenvoudigde model. Daar liggen wel wat uitdagingen; technisch maar zeker ook bij het vullen van de diverse parameters. Er zullen heel wat aannames gedaan moeten worden. En of de resultaten van het model dan lijken op de uitkomsten van de Club van Rome? We zullen het zien.
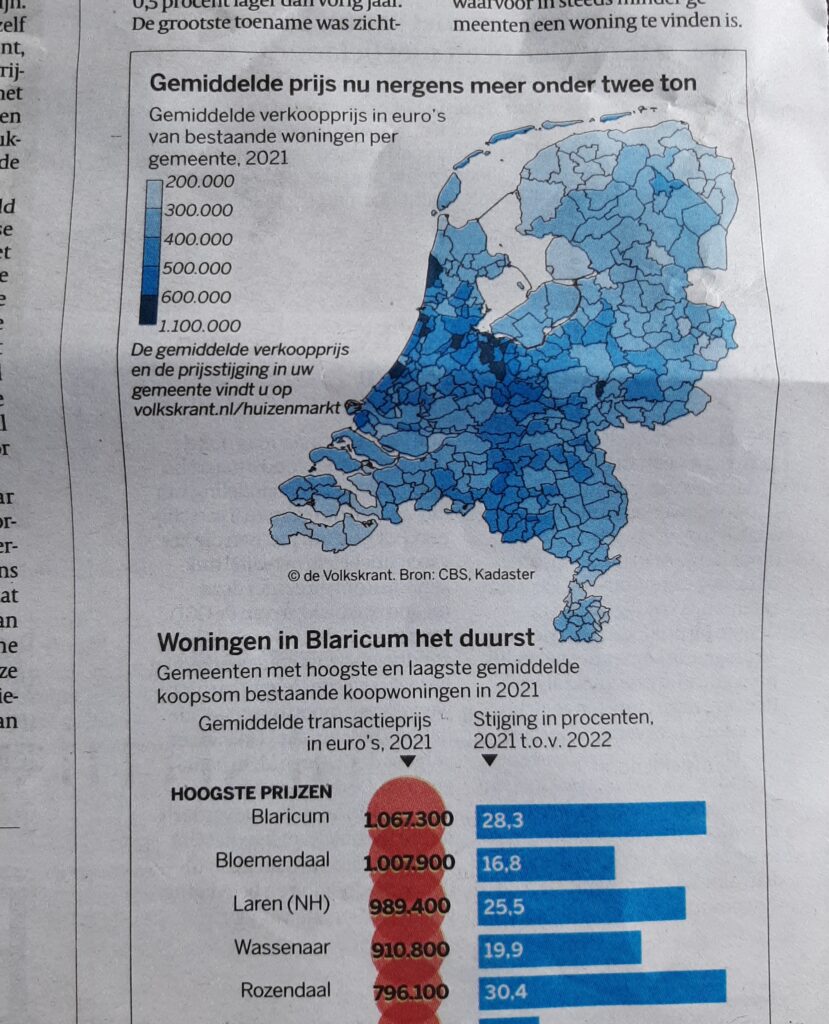
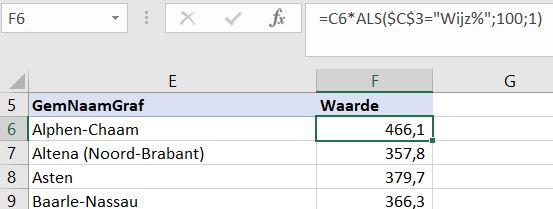
Deze week stond er in de Volkskrant een artikel over de heftige ontwikkeling van de huizenprijzen tussen 2020 en 2021. Er zijn al enkele gemeentes waar de gemiddelde huizenprijs boven de miljoen euro ligt!
Via de link volkskrant.nl/huizenmarkt kun je de gegevens van alle gemeentes van Nederland terugvinden. Het gaat dan over de gemiddelde prijzen in 2020 en 2021, de ontwikkeling tussen die twee jaren en ook de gemeentes met de hoogste en laagste huizenprijzen.
Om het analyseren van de (ontwikkeling van de) huizenprijzen makkelijker te maken hebben we de gegevens in Excel overgenomen en verrijkt met de bijbehorende provincie. In bijgaande werkmap kun je dan ook de gegevens per provincie bekijken.
In dit artikel laten we de diverse elementen van de Excel-sheet de revue passeren.
Brongegevens
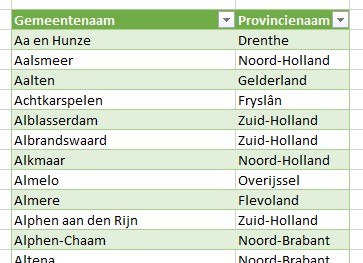
De gegevens van de Volkskrant-website zijn opgenomen op het tabblad GemHuisPrijs van het Voorbeeldbestand.
Per gemeente ziet u de gemiddelde huizenprijs in 2020 en 2021.
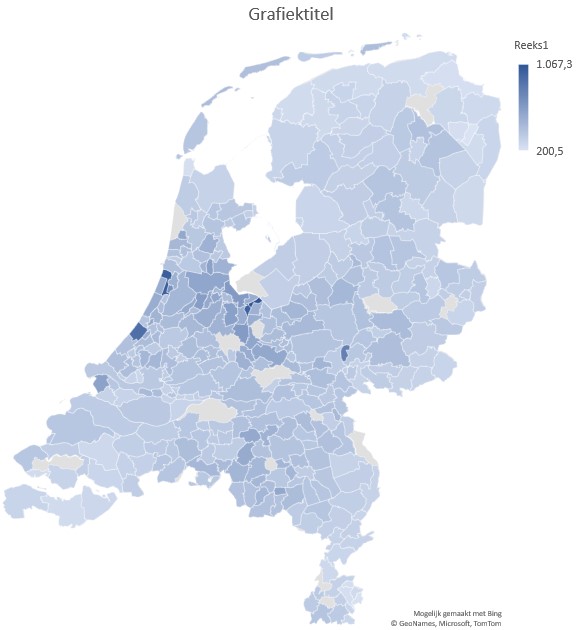
Het ligt voor de hand om deze gegevens in een kaartgrafiek weer te geven om snel een overzicht over heel Nederland te krijgen.
selecteer de gegevens van de eerste twee kolommen
kies op de menutab Invoegen in het blok Grafieken de optie Kaartgrafiek
De gemeentes met de hoogste huizenprijzen in 2021 vallen direct op.
Helaas zijn er ook ‘blinde vlekken’ te zien; Excel (of Bing?) herkent niet alle gemeentenamen zoals ze in het overzicht zijn opgenomen.
Gegevens transformeren
Zoals hiervoor aangegeven willen we de gegevens nog verrijken met de bijbehorende provincie. Ook het ‘blinde vlekken’-probleem willen we oplossen.
Sinds het beschikbaar zijn van Power Query in Excel wordt ons dit wel heel makkelijk gemaakt!
In het tabblad Gemeenten_alfabetisch_2021 van het Voorbeeldbestand zijn deze overgenomen.
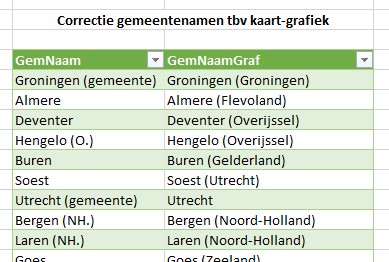
De kaart-grafiek herkent niet alle namen van de gemeentes (zie ook Excel en kaarten 2). Via een hulptabel gaan we proberen Excel ‘wat bij te leren’ (zie het tabblad GemNamen; hoe we hier mee omgaan komt later).
Van deze drie overzichten (basisgegevens, gemeentes per provincie en gemeentenamen-correctie) zijn Excel-tabellen gemaakt met respectievelijk de namen tblHuisPrijsGem, tblGemProv en tblGemNamen. Binnen Power Query zijn verbindingen gemaakt met deze drie tabellen (zie voor de techniek bijvoorbeeld het artikel Power Query).
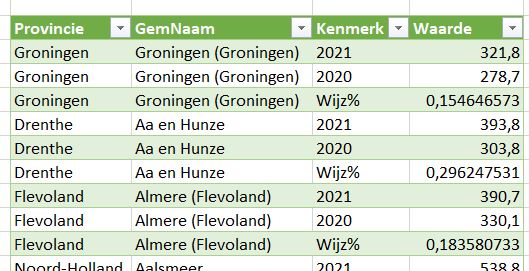
Met de optie Query’s samenvoegen binnen Power Query zijn deze verbindingen aan elkaar gekoppeld (zie de stappen binnen de query q_Resultaat). De laatste stap is het meest interessant: de drie kolommen (2020, 2021 en een berekende kolom Wijz%) worden omgezet naar een database-structuur. Het resultaat staat in het tabblad NwData van het Voorbeeldbestand:
NB we gaan deze nieuwe tabel gebruiken als bron voor draaitabellen. Om de bestandsgrootte te beperken hadden we er ook voor kunnen kiezen om het resultaat van de query alleen aan het gegevensmodel toe te voegen (zie het artikel Power Query) en daar de draaitabel op te baseren.
Overzichten
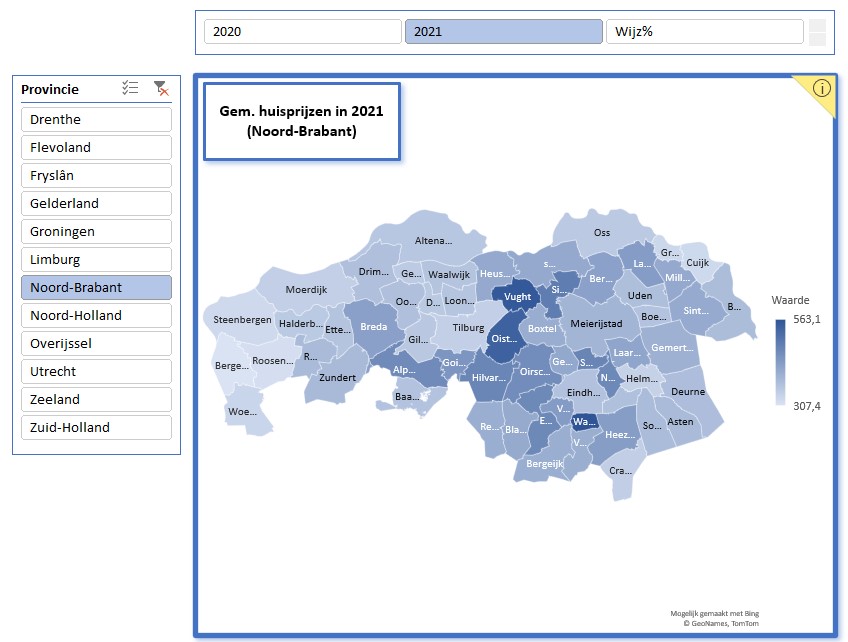
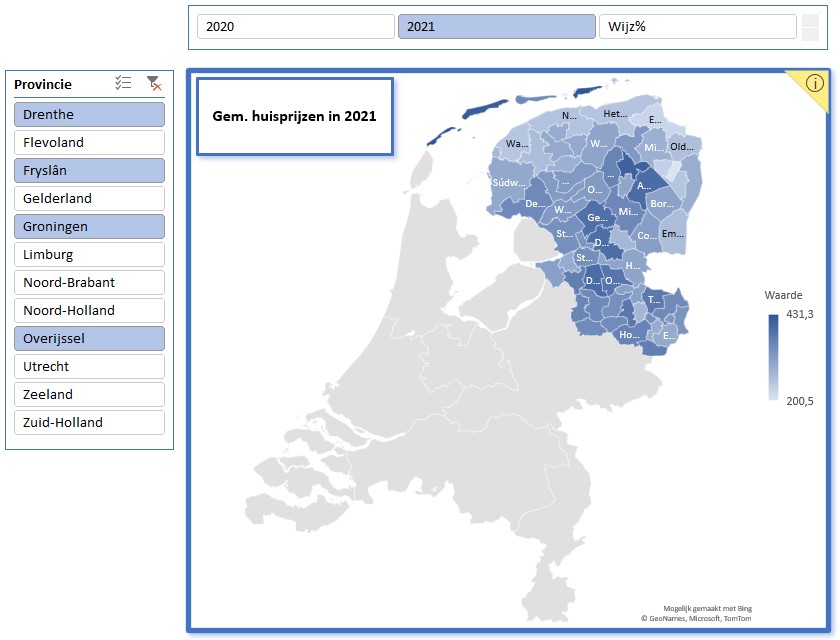
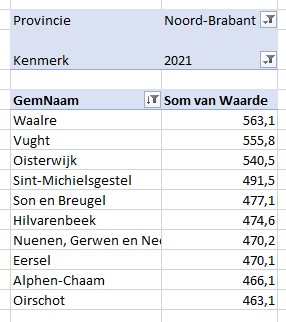
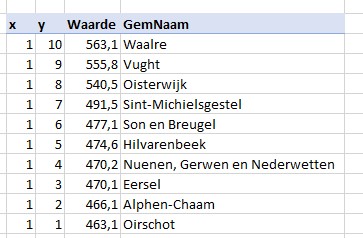
Het eerste overzicht (een landkaart met gemeentes) gaan we baseren op een draaitabel met als filters de Provincie en het Kenmerk (2020, 2021 of Wijz%; zie het tabblad Draai van het Voorbeeldbestand). Aangezien Kaart-grafieken niet rechtstreeks gekoppeld kunnen worden aan een draaitabel maken we naast de draaitabel een hulptabel:
Als we dan toch bezig zijn: als het kenmerk Wijz% is, dan vermenigvuldigen we de waarde met 100, dat is beter interpreteerbaar.
NB achteraf gezien hadden we beter bij de berekening van Wijz% binnen Power Query deze vermenigvuldiging kunnen doen!
Op basis van deze hulptabel hebben we een kaartgrafiek gemaakt en aan de draaitabel zijn 2 slicers toegevoegd (voor de Provincie en het Kenmerk). De grafiek en de slicers zijn ‘geknipt’ en in een nieuw tabblad Dashboard geplakt.
NB1 Aangezien de grafiektitel in een kaartgrafiek niet dynamisch kan zijn (dus gekoppeld aan een cel) is de titel vervangen door een tekstblok. De inhoud daarvan is gelijk aan de cel E3 van het tabblad Draai: =ALS(C3=”Wijz%”;”Verandering tussen 2020 en 2021″;”Gem. huisprijzen in “&C3)& ALS(OF(C2=”(Alle)”;C2=”(Meerdere items)”);””;” (“&C2&”)”)
NB2 de overgang in de formule hierboven van de 2e naar de 3e regel is ingevoerd door de toetscombinatie Alt-Enter, waardoor er in het tekstblok ook altijd op die plaats een regelovergang is.
NB3 voor de kaartgrafiek is een maximaal bereik van cellen geselecteerd, zodat iedere keuze van Provincie (of heel Nederland) meegenomen wordt. De formule in kolom F is daartoe wat uitgebreid anders zou de ondergrens van de legenda altijd 0 zijn; in cel F7 staat: =ALS(C7=””;MIN($F$6:F6);C7*ALS($C$3=”Wijz%”;100;1))
LET OP Excel kan voor de provincies Drenthe en Groningen geen kaart genereren. Eén of meer plaatsen worden niet herkend? Het vreemde is, dat het voor Drenthe wel werkt als je ook Overijssel kiest (hou Ctrl ingedrukt bij het selecteren in de slicer)! En Groningen wordt zichtbaar als je de drie andere provincies in de buurt ook kiest.
Dit is het moment om te kijken of de kaart nog ‘blinde vlekken’ heeft. Als je weet welke gemeente(s) het betreft kun je op het tabblad GemNamen proberen of een andere naam of toevoeging aan de naam werkt. In de eerste kolom komt de naam zoals die voorkomt in het eerste bronbestand, in de tweede kolom plaats je een naam waarvan je denkt/hoopt dat Excel die zal herkennen. Vergeet niet alle verbindingen en draaitabellen te vernieuwen: klik op de button Alles vernieuwen op de menutab Gegevens:
In het tabblad Draai van het Voorbeeldbestand is nog een tweede draaitabel gecreëerd met daarin de Top-10 van de gemeentes (zie voor de werkwijze het artikel Top-5; verschillende methodes). Hier willen we een Bellengrafiek van maken net als in de Volkskrant. Ook dan moeten we met een hulptabel werken:
De draaitabel is automatisch gekoppeld aan de bestaande slicers. Wanneer we op basis van de hulptabel een Bellengrafiek maken en de assen, rasters en overige ‘ballast’ weglaten, kunnen we ook deze grafiek naar het tabblad Dashboard kopiëren.
In de cellen naast de grafiek maken we verwijzingen naar de betreffende cellen in het tabblad Draai. Wel eerst de achtergrond van het teken- en grafiekgebied transparant maken.
Nog een tekstblok met een rand er omheen, et voilà.
Ook voor de laagste prijzen (of wijzigingspercentage) maken we op dezelfde manier een grafiek op basis van een draaitabel en een hulptabel.
Het resultaat mag er zijn (zie het tabblad Dashboard van het Voorbeeldbestand).
In veel artikelen op de website van G-Info worden slicers gebruikt om snel gegevens in een draaitabel te filteren. In het artikel Slicers in Excel hebben we de grondbeginselen laten zien; een soort Slicers voor Dummies dus.
Het werd tijd voor een vervolg, een artikel voor gevorderden.
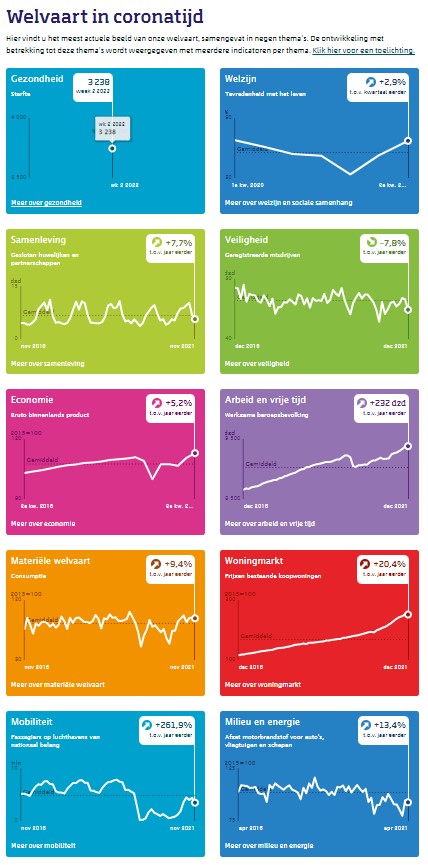
Om wat materiaal te hebben om het gebruik van slicers toe te lichten, ging ik (uiteraard) weer eens rondkijken op de site van het CBS. Daar trof ik een interessante pagina aan, waar geprobeerd wordt de ontwikkeling van de welvaart in Coronatijd zichtbaar te maken. Dit aan de hand van 10 verschillende invalshoeken, zoals Gezondheid (sic!), Economie en Mobiliteit.
Je kunt daar niet alleen grafieken vinden, maar ook doorklikken naar onderliggende data. Dat is voor ons natuurlijk altijd fijn. Kunnen we kijken of we de grafieken na kunnen bouwen of misschien wel verbeteren.
In dit artikel laten we zien hoe de basis-gegevens er uitzien, hoe je daar snel en makkelijk grafieken van maakt en hoe Slicers een rol kunnen spelen bij de presentatie.
Daarnaast zullen we aan de hand van wat fictieve gegevens kijken hoe je de vormgeving van de slicers helemaal naar je hand kunt zetten.
Bron-gegevens
Zoals gezegd hebben we bron-gegevens ontleend aan een pagina op de CBS-website: cbs.nl/nl-nl/visualisaties/welvaart-in-coronatijd. Alle 10 de grafieken hebben een eigen bronbestand; wat opvalt is dat de structuur van de bestanden flink verschillen. Het ene bestand bevat gegevens over diverse jaren, een ander slechts de data van 1 jaar; de detaillering is soms een kwartaal, in een ander geval worden de gegevens getoond op weekbasis etc.
In de eerste 10 werkbladen van het voorbeeldbestand zijn de gegevens overgenomen (soms is de structuur daarvan iets aangepast om het creëren van een grafiek makkelijker te maken).
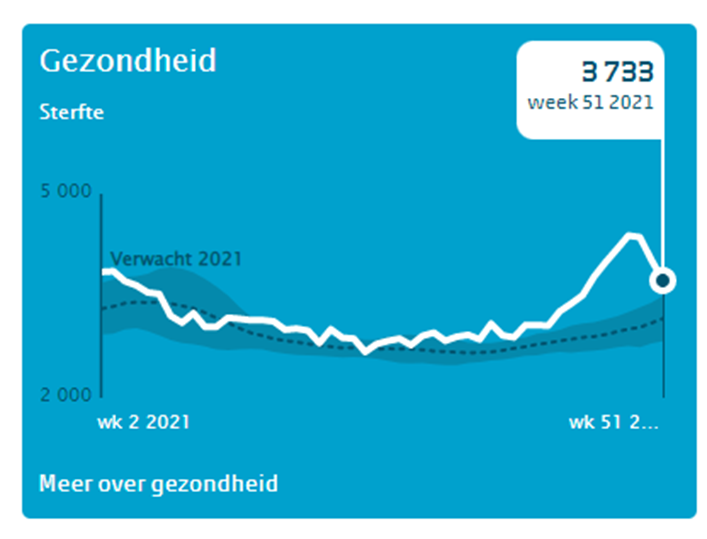
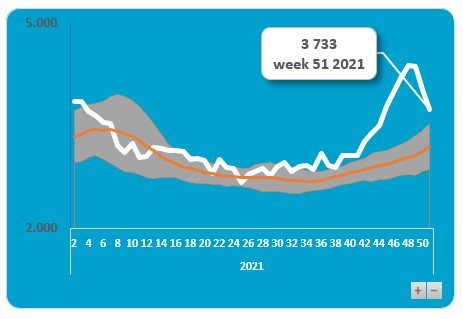
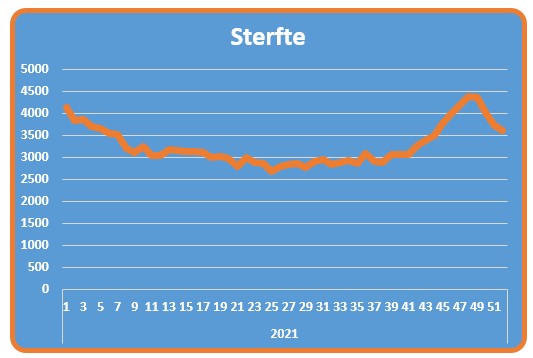
Gezondheid
Op het tabblad Sterfte van het voorbeeldbestand ziet u de grafiek van het CBS en de daarbij behorende gegevens. Als gezondheids-indicator hebben ze ervoor gekozen om de eventuele oversterfte te laten zien.
In de grafiek zijn de weken van 2021 weergegeven, terwijl de bron veel meer gegevens bevat. We hebben daarom aan de tabel tblOverlijden een kolom Grafiek toegevoegd, waarmee we kunnen aangeven of een bepaalde week in de grafiek zichtbaar moet zijn of niet:
Op basis van deze gegevens is een draaitabel gemaakt waarin per Jaar en Week de overlijdens etc. worden geturfd. In het Filter-blok staat het veld Grafiek:
Binnen de menutab Hulpmiddelen voor draaitabellen, in de tab Analyse staat de optie Draaigrafiek in het blok Extra.
Een paar aanpassingen:
rasterlijnen verwijderen
de titel en legenda verwijderen
alle Veldknoppen verwijderen
wijzig het grafiektype in Combinatie, waarbij de overlijdens en de verwachting een lijn worden en de andere 2 een vlak
wijzig de achtergrondkleur en de kleuren van de items in de grafiek (het vlak van de Ondergrens krijgt dezelfde kleur als de achtergrond)
pas de opmaak van de assen aan
NB1 je kunt aan punten van een grafiek ook labels koppelen. In dit geval hebben we alleen aan het laatste punt van de grafiek een label gehangen: klik op een lijn in de grafiek, dan nogmaals op het punt waar een label moet komen en klik dan met de rechtermuisknop op dat punt en kies de optie Gegevenslabel toevoegen (om eerlijk te zijn: het label is gekoppeld aan het punt van week 51 van 2021. Wanneer de bovengrens in het tabblad wordt gewijzigd, zal het label wel de juiste inhoud bevatten, maar niet naar het juiste punt wijzen! Uiteraard is dat aan te passen, maar dat gaat ver buiten de scope van dit artikel).
NB2 de inhoud van het zichtbare label wordt via een formule in het tabblad bepaald
NB3 de achtergrondkleur van de grafiek match exact met het origineel. Ik heb de Google Chrome-extensie Eye Dropper gebruikt om de juiste RGB-codes te achterhalen.
NB4 de grafiek is (nog) niet helemaal gelijk aan die van het CBS. Wat meer toelichting van de grafiek en de cijfers zou op zijn plaats zijn, maar ook dat valt buiten de scope van dit artikel.
LET OP wijzig je de grenzen voor de items die in de grafiek moeten worden weergegeven, vergeet dan niet de draaitabel te Vernieuwen (of rechts te klikken op het Grafiekgebied en de optie Gegevens vernieuwen te kiezen).
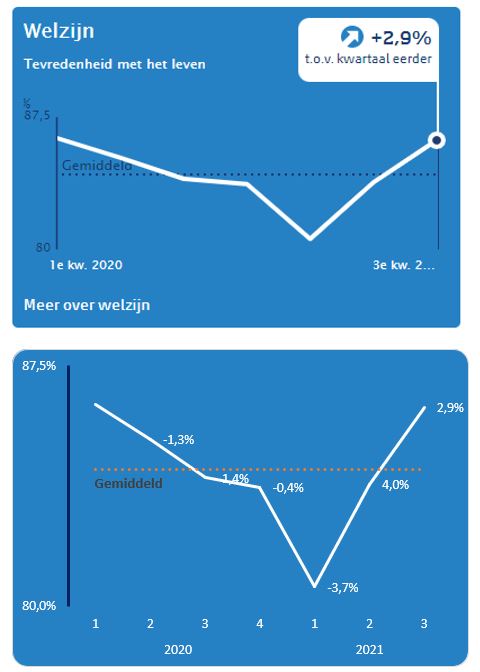
Welzijn
Op het tabblad Welzijn van het voorbeeldbestand staan de betreffende grafiek van het CBS, de brongegevens, een daarop gebaseerde draaitabel en een daarmee gekoppelde draaigrafiek.
In de bron zijn alleen kwartaalgegevens vastgelegd; de getallen op de horizontale as lijken me dat duidelijk genoeg aan te geven.
Het gemiddelde is aan de brongegevens als een aparte kolom toegevoegd. Hetzelfde geldt voor de percentages die de wijziging t.o.v. de vorige maand weergeven.
NB de tekst Gemiddeld is in dit geval als een label aan het eerste punt van de horizontale stippellijn toegevoegd. Door de Notatie van het label aan te passen wordt niet de waarde weergegeven maar in dit geval een letterlijke tekst.
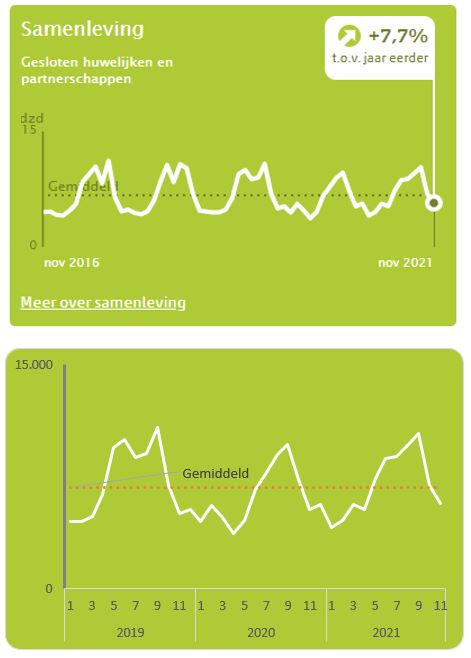
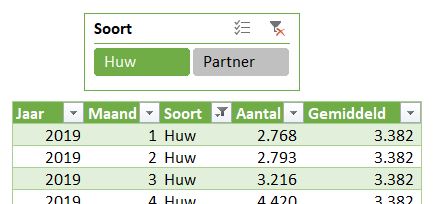
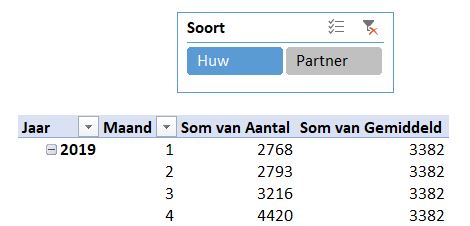
Samenleving
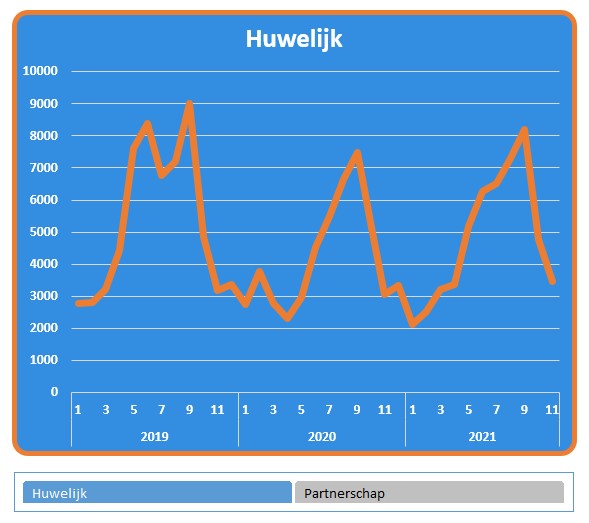
In het tabblad Huw van het voorbeeldbestand ziet u de grafiek van het CBS over Samenleving. Ze hebben daar het verloop van het aantal huwelijken en partnerschappen van de laatste jaren weergegeven.
De brongegevens bevatten daar slecht de gegevens vanaf 2019, dus onze grafiek is wat ‘kleiner’.
De gehanteerde methode is weer hetzelfde: maak een draaitabel op basis van de brongegevens, kies bij Analyse een daarop gebaseerde Draaigrafiek en maak nog wat lay-out-aanpassingen.
De tekst Gemiddeld is weer als een label aan de horizontale lijn gekoppeld. Bij het verplaatsen van dit label naar een plaats waar deze de grafiek niet overlapt, krijgen we ‘gratis’ een koppel-lijntje.
Veiligheid etc.
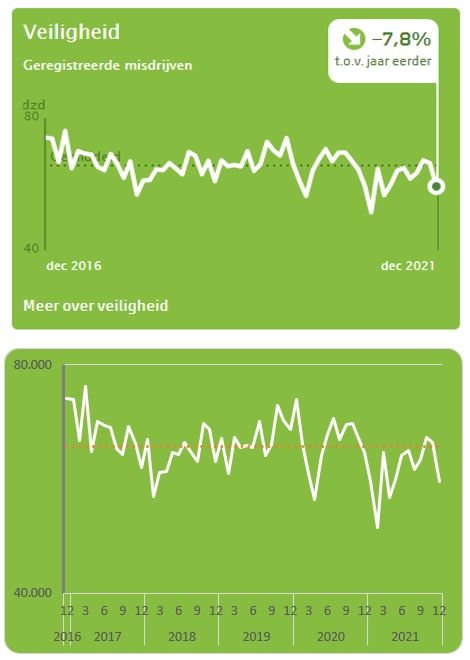
Ook voor Veiligheid en de andere items vindt u in diverse tabbladen de brongegevens zoals het CBS die beschikbaar stelt.
In het tabblad Veiligheid ziet u onder de CBS-grafiek ook weer een vergelijkbare Excel-grafiek. De manier waarop die is gemaakt bevat geen verrassingen. Misschien de inhoud wel: het aantal misdrijven is dalende, en dat niet alleen in de Corona-periode.
Aan u om voor de overige onderdelen een grafiek te maken. Juist ja: het valt buiten de scope!
Combinatie van data en slicers
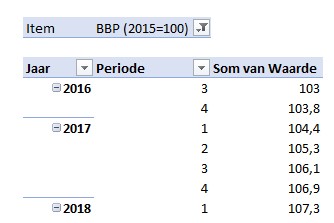
In het tabblad DataTotaal van het voorbeeldbestand zijn de belangrijkste gegevens uit de 10 tabbladen in één tabel opgenomen.
Het soort gegeven staat in de kolom Item, het Jaar is logisch, in de kolom Periode kunnen zowel kwartaal-, maand- als weekaanduidingen voorkomen. In de kolom Waarde staan de bijbehorende percentages, aantallen, indexen etc.
Maken we op basis van deze gegevens een draaitabel dan wordt het een zootje: is die 3 bij periode nu een week, maand of kwartaal, wat stelt die 103 voor?
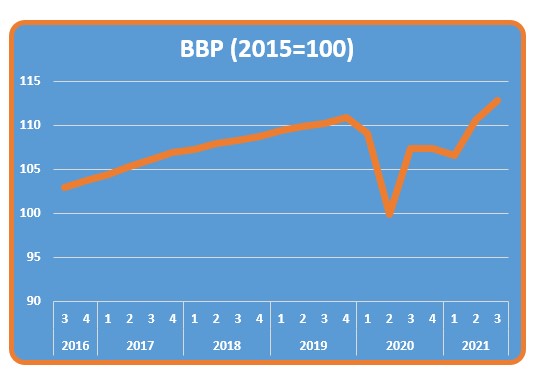
Plaatsen we Item nu in het Filter-gebied en kiezen we als filter het BBP dan wordt alles duidelijk:
De periodes zijn natuurlijk kwartalen en de waarde stelt een index voor (zie de indicatie in de item-naam).
Nog even een draaigrafiek maken via Hulpmiddelen voor draaitabellen/ Analyseren (en wat opmaak) en we zien de ontwikkeling van het BBP over de jaren.
Kies je een ander Item in het Filter-gebied dan krijgen we direct de daarbij behorende grafiek:
Het zou natuurlijk mooi zijn als de achtergrondkleur zich zou aanpassen aan het gekozen item, maar dat is niet de scope ….
Wat we wel kunnen verbeteren is de manier van filteren, namelijk met behulp van een slicer (wel de scope!):
klik ergens in de draaitabel (of in de draaigrafiek)
kies in de menutab Hulpmiddelen in het onderdeel Analyseren in het blok Filter de optie Slicer invoegen
selecteer het veld (of velden) waarvoor je een slicer wilt
en klik OK
In dit voorbeeld hebben we (uiteraard) gekozen om te filteren op Item. Er ontstaat dan een slicer waarbij alle beschikbare item-namen onder elkaar staan.
Klik je in de kop van een slicer dan komt er een menutab Hulpmiddelen voor slicers tevoorschijn. Binnen de Opties hebben we het aantal Kolommen op 2 ingesteld en een Slicerstijl gekozen die qua kleur bij de grafiek past. Nog even de breedte en hoogte aanpassen (via de grepen aan de randen) en klaar!
Slicer met meerdere koppelingen
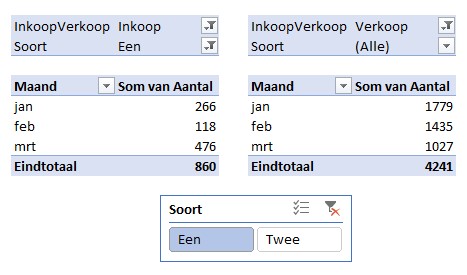
In het tabblad SlicerDubbel van het voorbeeldbestand staat een simpel voorbeeldje met een tabel van Inkopen en Verkopen. Op deze tabel zijn twee draaitabellen gebaseerd.
Aan de eerste draaitabel is een slicer gekoppeld, waarbij de Soort Een is gefilterd. Het zou natuurlijk mooi zijn als ook tegelijkertijd de tweede draaitabel wordt gefilterd.
NB als je een slicer toevoegt is het niet noodzakelijk dat dat onderdeel ook in het Filter-gebied van de draaitabel is geplaatst. In dit geval zou je dus Soort uit de kop van de draaitabellen kunnen verwijderen. De slicer maakt al duidelijk wat er gefilterd wordt.
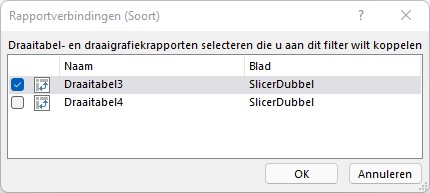
Een slicer koppelen aan meerdere draaitabellen:
klik in de kop van de slicer; daarmee selecteer je deze.
in de menutab Hulpmiddelen voor slicers in de Opties kies je de optie Rapportverbindingen
selecteer de draaitabellen die met behulp van deze slicer gefilterd moeten worden:
LET OP dit koppelen aan meerdere draaitabellen kan alleen wanneer de draaitabellen op dezelfde brongegevens zijn gebaseerd.
Soorten filters
Excel kent (op dit moment) 2 soorten filters: de Slicer zoals we die hiervoor al hebben gezien en een Tijdlijn. Deze laatste kan alleen maar gebruikt worden wanneer de brongegevens een kolom met datums bevat.
Als voorbeeld hebben we aan de tabel met misdrijven een kolom JrMnd toegevoegd, waarin de Jaar– en Maand-kolommen worden gecombineerd (zie het tabblad Veiligheid2 in het voorbeeldbestand).
Op basis van deze gegevens zijn weer een draaitabel en een draaigrafiek gemaakt. Door aan de grafiek ook nog een (lineaire) trendlijn toe te voegen is de tendens in de tijd goed te zien.
NB bij het maken van de draaitabel is het veld JrMnd naar het Rij-gebied gesleept. Excel ‘ziet’ dat het om een datum gaat en maakt direct meerdere velden aan in dat gebied. In dit geval, omdat de reeks meerdere jaren bevat, Jaar en daarnaast ook nog Kwartaal en de Maand. Geen Dag omdat Excel denkt, dat het niet zinvol is om zaken op dagbasis te rubriceren. Wil je dat wel dan moet je zelf de groepering van de datum aanpassen (zie Groeperen in een draaitabel).
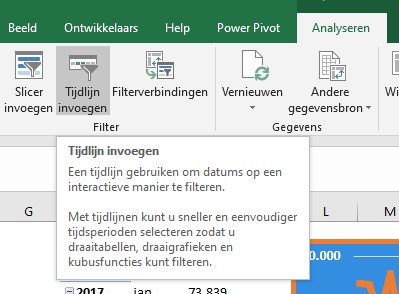
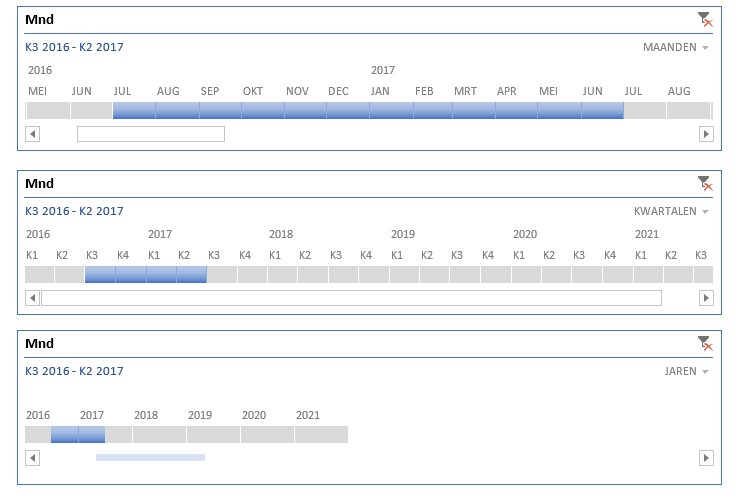
In plaats van een Slicer voegen we nu een Tijdlijn in.
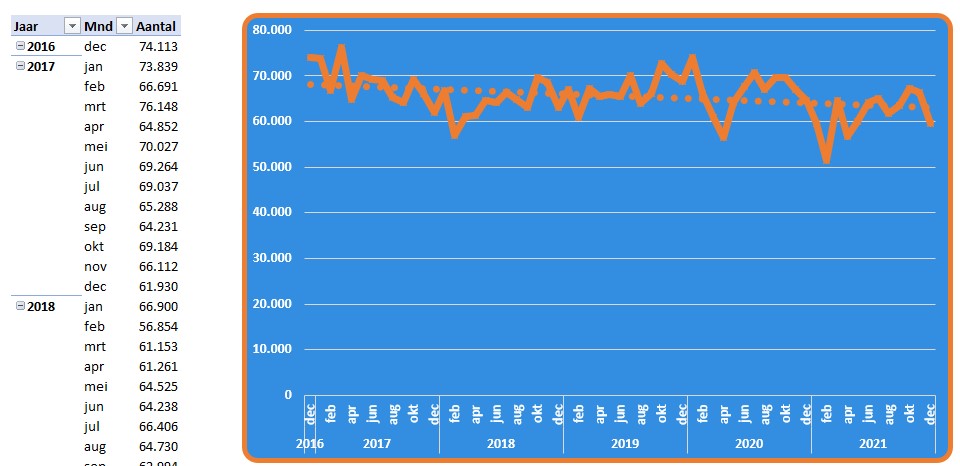
Dit is een heel handig hulpmiddel als je snel de resultaten van verschillende periodes wilt bekijken.
In dit geval hebben we gegevens van 5 jaren tot onze beschikking (en nog een maand in 2016, dus voor Excel 6 jaar); willen we een selectie maken dan moeten we met de schuifbalk onderaan aan de gang.
Het tijdsbestek kunnen we inperken door aan de zijkanten de begrenzing te verschuiven (zie het rode pijltje hierboven). Ook kun je maanden selecteren door op het blokje onder een maand te klikken, eventueel met Shift ingedrukt om een reeks maanden te kiezen.
NB je kunt geen ‘losse’ maanden selecteren, alleen een reeks aaneengesloten perioden.
In de Tijdlijn linksboven zie je altijd de huidige selectie; aan de rechterkant kun je de soort periode kiezen.
In het voorbeeld hebben we de Tijdlijn 2 keer gekopieerd met ieder een andere periodesoort.
Duidelijk is te zien dat een keuze in de ene Tijdlijn invloed heeft op de anderen.
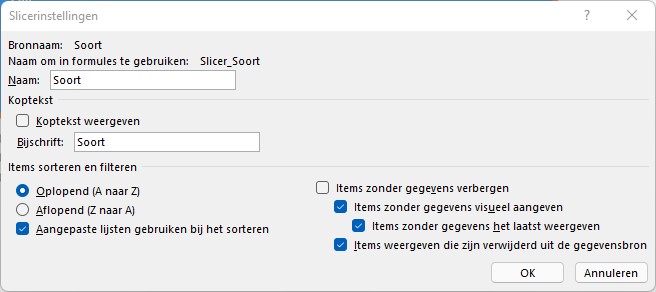
Slicer-instellingen
Op allerlei manieren zijn Slicers (en Tijdlijnen) nog te fine-tunen.
De kopregel van de slicer is lang niet altijd nodig en misschien wel ongewenst wanneer die bijvoorbeeld de lay-out van je dashboard verstoort.
In het voorbeeld op het tabblad Huw2 van het voorbeeldbestand is het ook duidelijk zonder kop wat de 2 keuzemogelijkheden inhouden.
Klik met de rechtermuisknop op een slicer, kies de optie Slicerinstellingen en verwijder het vinkje bij Koptekst weergeven:
NB om alle filteringen in één keer ongedaan te maken is nu iets moeilijker; je kunt niet meer de -button in de slicerkop gebruiken. Klik rechts op de slicer en kies Filter wissen uit.
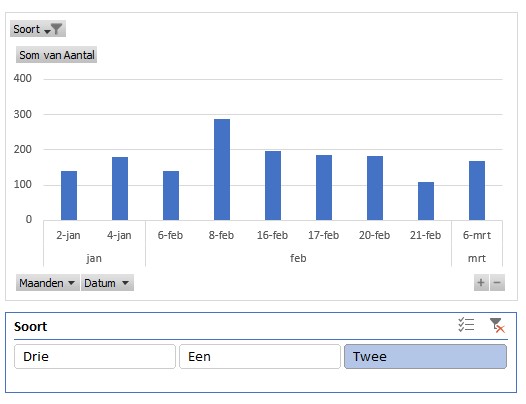
Om nog enkele andere slicer-instellingen te laten zien bevat het tabblad Instellingen van het voorbeeldbestand een tabelletje met per Datum en Soort een Aantal.
Op de bekende manier laten we daar een draaitabel op los en maken dan een draaigrafiek.
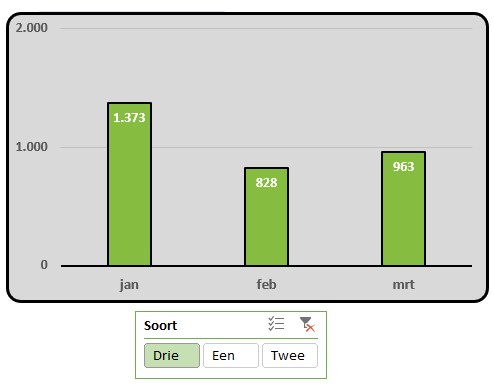
Nog een slicer voor de Soort en we kunnen analyseren.
Vervelend: de sortering in de slicer is niet zoals we zouden willen.
Maar in de Slicerinstellingen kunnen we alleen voor oplopend of aflopend kiezen en deze sortering is niet, zoals bij een draaitabel, handmatig aan te passen.
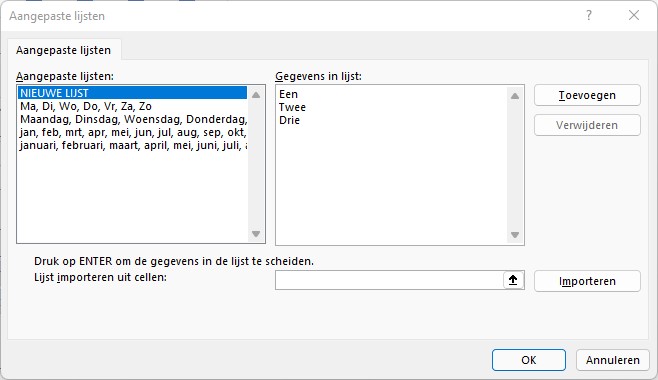
Wel ziet u bij de instellingen staan dat Excel rekening kan houden met Aangepaste lijsten.
scrol helemaal naar beneden en daar ziet u onder het kopje Algemeen een button Aangepaste lijsten bewerken
tik de lijst in, in de gewenste volgorde, en kies Toevoegen
NB1 hier zie je ook waarom Excel de dagen van de week en maanden altijd in de juiste volgorde plaatst bij een sortering.
NB2 je moet nog wel de draaitabel (of -grafiek) vernieuwen om de sortering in de slicer daadwerkelijk uit te laten voeren.
NB3 deze lijst wordt in het Excel-systeem vastgelegd en zal dus ook in andere werkmappen toegepast kunnen worden. Ook in nog nieuw te ontwikkelen systemen.
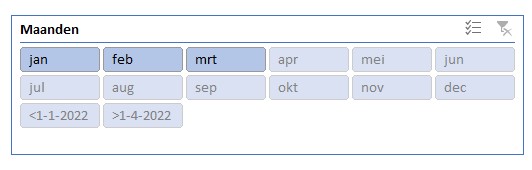
Voor deze draaitabel is ook een slicer voor de Maanden gemaakt. In de slicer zijn diverse periodes ‘grijs’.
Dat betekent dat die niet meer in de bron voorkomen of door een andere filtering nu niet meer actief zijn in de draaitabel. In Slicerinstellingen kunt u de optie Items zonder gegevens verbergen aanvinken.
Opmaak van slicers
Door middel van de Slicerinstellingen, zoals hiervoor aangegeven, kunt u de lay-out van een slicer al behoorlijk aanpassen.
Via de menutab Hulpmiddelen voor slicers/Opties kun je ook een Slicerstijl kiezen, 8 lichtgekleurde varianten en 6 donkere.
Op het tabblad Opmaak van het voorbeeldbestand hebben we een groen/grijze grafiek gecombineerd met een slicer met als stijl Licht6.
Wilt u de slicer helemaal naar uw eigen hand zetten:
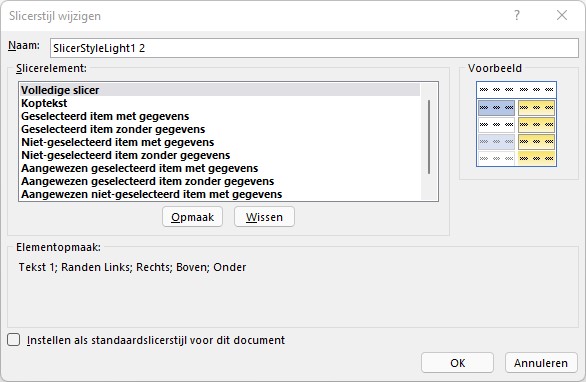
klik met de rechter muisknop op de variant die het meest lijkt op hoe u het wilt hebben.
kies de optie Dupliceren
pas de naam aan
kies een onderdeel (Volledige slicer, Koptekst et cetera) en klik op de button Opmaak
herhaal het vorige punt voor alle onderdelen die u wilt aanpassen
klik op OK In dit voorbeeld is de kop flink onder handen genomen, hebben we de rand van de slicer weggelaten en hebben we ook de kleuren van de niet-geselecteerde items aangepast.
Deze opmaak wordt bij de Slicerstijlen onder het kopje Aangepast opgeslagen; zie het voorbeeld KopGroen in het voorbeeldbestand.
NB1 zoals u ziet kunt u deze stijl ook als standaard voor alle NIEUWE slicers instellen
NB2 experimenteer met de diverse opties om te kijken wat het resultaat is.
LET OP de draaitabel op het tabblad Opmaak is onder de grafiek verborgen.
Slicer gekoppeld aan tabel
Tot nu toe hebben we slicers alleen gebruikt om gegevens in een draaitabel te filteren. Maar slicers kunnen ook toegepast worden op Excel-tabellen (zie het tabblad Huw van het voorbeeldbestand). Een groot nadeel is, dat de filtering in de tabel die daardoor wordt uitgevoerd, er voor zorgt dat sommige gedeelten van het tabblad niet meer zichtbaar zijn (kies maar eens Partner als filtering).
Wanneer je een slicer aan de draaitabel koppelt, heb je dat probleem niet. En het gewenste resultaat (de grafiek in dit geval) wordt automatisch aangepast.
LET OP: na het downloaden de extensie wijzigen in zip
Het einde van het jaar nadert en zo ook de (voor Nederlanders zeer bekende) Top-2000, een marathon-uitzending op Radio-2 met de 2.000 beste (?) liedjes uit de pop-geschiedenis.
In een eerder artikel (Top2000 en draaitabellen) hebben we laten zien hoe je draaitabellen kunt gebruiken om meer inzicht te krijgen in de ontwikkeling binnen deze lijst vanaf 1999.
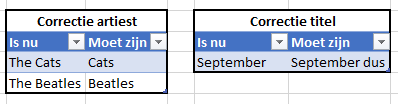
Naar aanleiding van dat artikel reageerde iemand op de site met de opmerking dat de Cats in 2020 met 5 nummers in de lijst voorkwamen. En dat dit in de overzichten niet was terug te vinden. Wat bleek: in de officiële lijst van Radio-2 over 2020 was deze groep opgenomen onder The Cats.
Tijd dus om een nieuw systeem te maken waarmee we inconsistentie in de aanlevering snel kunnen corrigeren. En een mooie aanleiding om een handig onderdeel van Power Query eens onder de loep te nemen.
Brongegevens
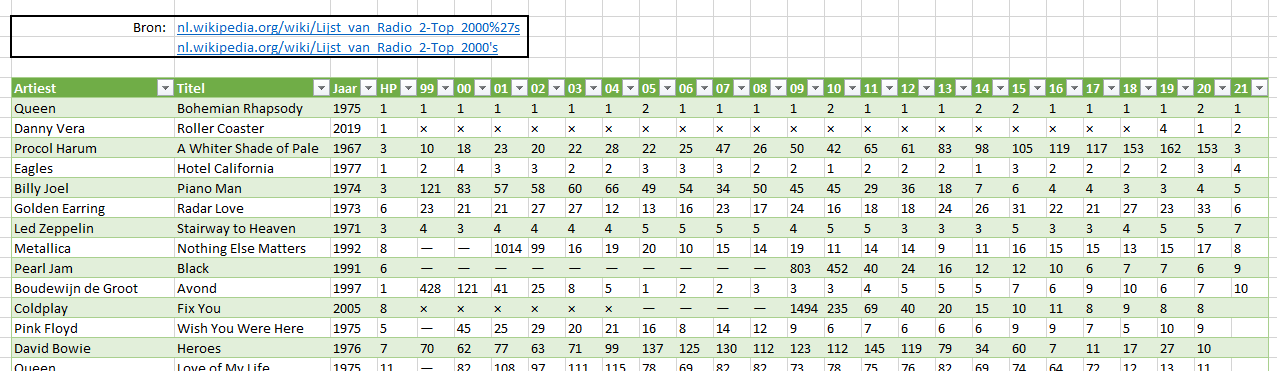
Op het goeie, vertrouwde Wikipedia is veel te vinden, dus ook de standen van de Top2000 in de afgelopen jaren. Zelfs de eerste 10 van 2021 zijn al ingevuld.
Op het tabblad Wiki van de file Top2000 vs2.xlsx in het Voorbeeldbestand hebben we met behulp van Power Query deze tabel overgehaald (zie de query tblWiki in Query’s en verbindingen).
NB de link naar de bron kan op 2 manieren weergegeven worden: eindigend op Lijst_van_Radio_2-Top_2000’s óf op Lijst_van_Radio_2-Top_2000%27s. Een URL mag eigenlijk geen ‘vreemde’ tekens bevatten; tegenwoordig worden deze tekens echter door de browser zelf omgezet naar de bijbehorende ASCII-code (een apostrof heeft de hexadecimale code 27; in de URL voorafgegaan door een %).
Deze Wiki-tabel is met wat Power Query-inspanning omgezet naar losse bestanden per jaar. Deze jaar-standen zijn tot en met 2019 opgeslagen in een map Top2000 in het Voorbeeldbestand.
De laatste 2 jaren hebben we nog even apart gehouden voor demonstratiedoeleinden.
De map, de 2 jaarbestanden en de voorbeeldfile zijn allemaal terug te vinden in het Voorbeeldbestand.
Alle jaar-bestanden hebben dezelfde lay-out: ze bevatten één tabblad (met de naam Data) en hebben allemaal 4 kolommen met dezelfde kopnamen:
NB het Wiki-bestand blijkt wel consistent te zijn in de naamgeving van de artiesten (en de titels)!
Bron-bestanden koppelen
Ja, ik weet het: dat klinkt niet logisch! Eerst losse bestanden maken en dan weer aan elkaar koppelen? Maar we bereiken daarmee wel dat we flexibeler zijn in het maken van overzichten. Daarnaast geeft het inzicht in een methode die veel vaker gebruikt kan worden. Wat dat laatste betreft: in menig rapportageproces gaat iedere maand (te) veel tijd zitten in het ophalen van nieuwe maandstanden, het toevoegen aan de bestaande gegevens en daarna zorgen dat alle overzichten weer up-to-date zijn. En dat kan dus met ‘één druk op de knop’! Tenminste als je rapportage-systeem goed is ingericht.
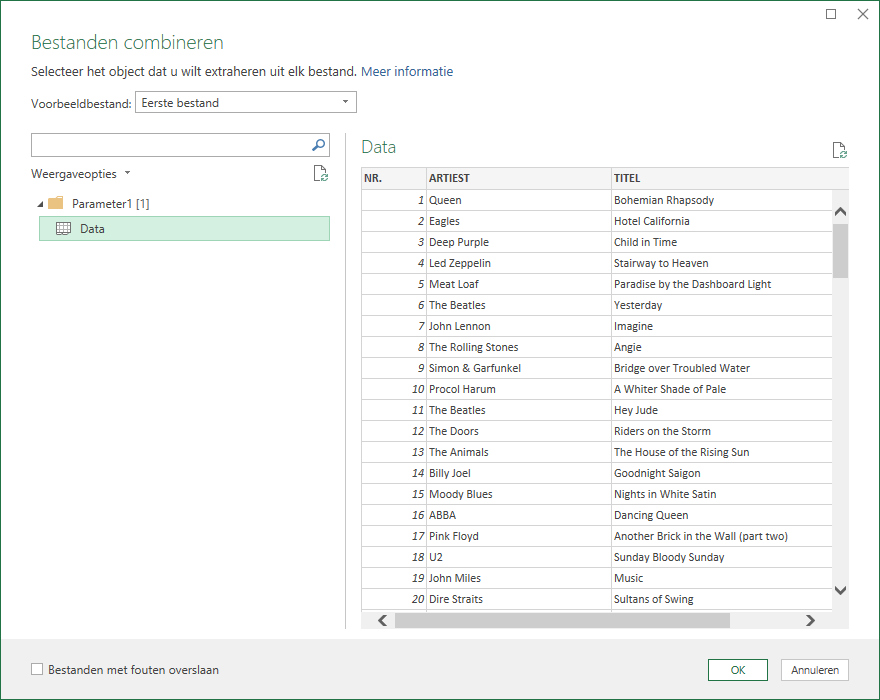
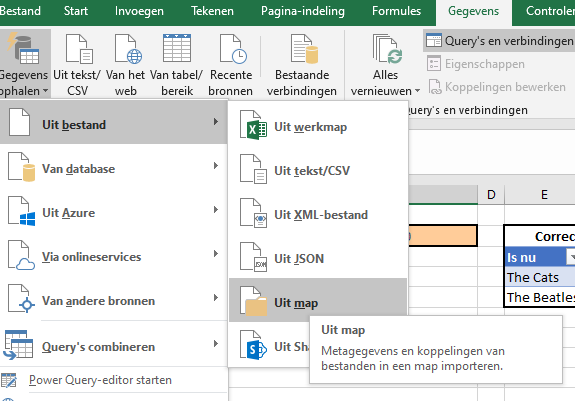
kies in de menutab Gegevens in het blok Gegevens ophalen en transformeren de optie Gegevens ophalen
kies Uit bestand en dan Uit map
selecteer de map Top2000 uit het hiervoor uitgepakte Voorbeeldbestand
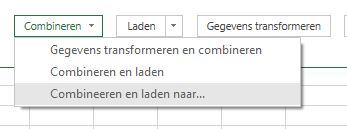
kies bij de button Combineren de optie Combineren en laden naar …
in het vervolgscherm kiezen we het tabblad Data en OK
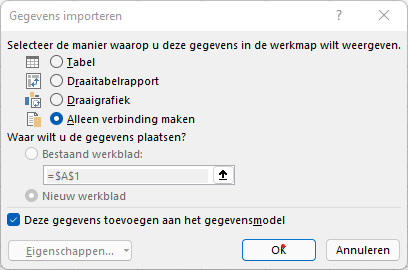
Excel gaat nu even ‘denken’, waarna we de vraag krijgen wat we met de gecombineerde bestanden willen doen. Voorlopig nog niks, dus we kiezen voor Alleen verbinding maken. Wel zorgen dat de gegevens aan het gegevensmodel worden toegevoegd:
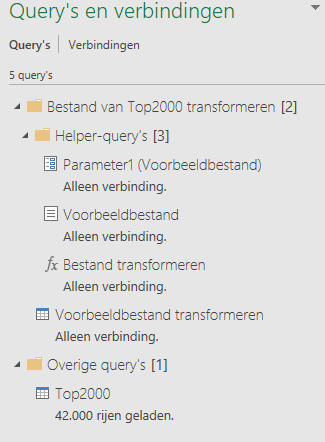
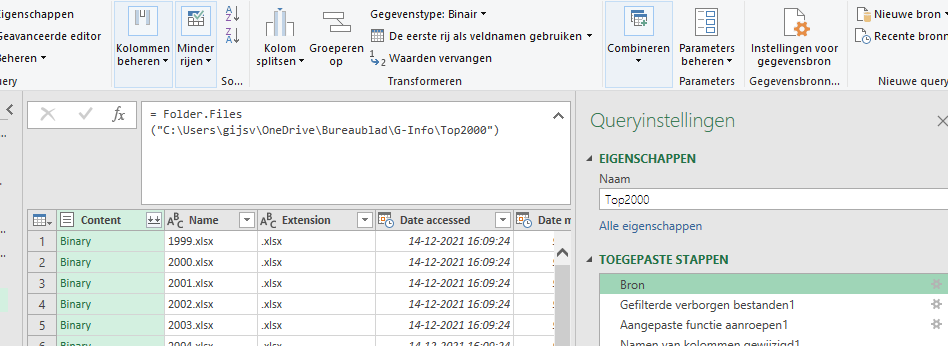
Om de klus te klaren heeft Excel diverse query’s gegeneerd. Voor ons is alleen de Top2000-query interessant.
NB we kiezen er voor om alleen een verbinding te maken. Waarom zou je de gegevens nog een keer in dit bestand opnemen? De basisgegevens zijn altijd te raadplegen in de map Top2000. Met deze techniek wordt het bestand veel minder groot, dat is altijd handig.
Maar het vervelende is nu, dat de Top2000-query altijd naar de net gekozen map zoekt. Wanneer u bijvoorbeeld de file Top2000 vs2.xlsx uit het Voorbeeldbestand opent en u vernieuwt de Top2000-query dan krijgt u ongetwijfeld een foutmelding. Dat kunnen we makkelijk oplossen:
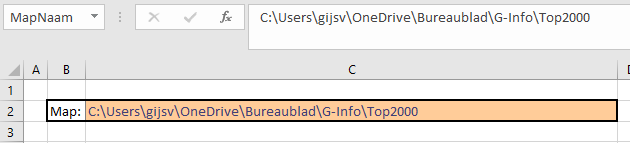
geef een cel een naam (bijvoorbeeld MapNaam; zie het tabblad Data)
vul deze cel met het pad naar en de naam van de gewenste map. In de Verkenner van Windows haalt u die gemakkelijk op door rechts te klikken in de kop en kies dan Adres kopiëren:
dubbelklik op de query Top2000
kies bij TOEGEPASTE STAPPEN de eerste stap: Bron
wijzig de formulebalk nu in = Folder.Files(Excel.CurrentWorkbook(){[Name=”MapNaam”]}[Content]{0}[Column1])
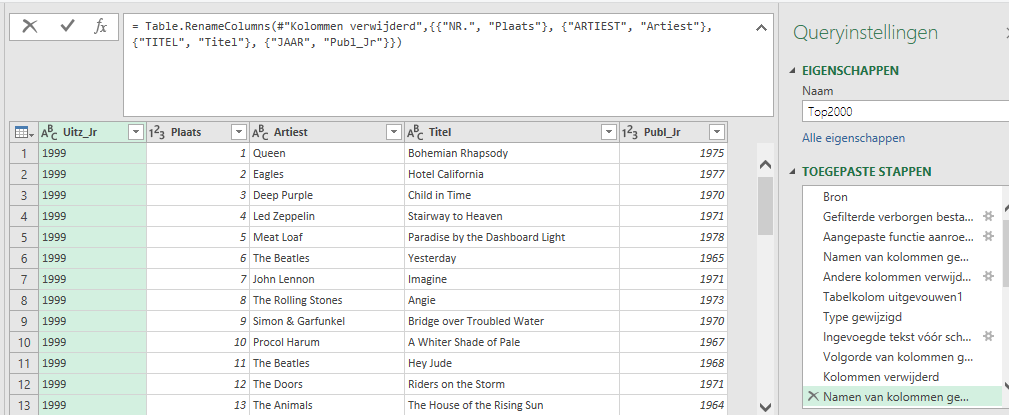
nu we toch bezig zijn, voegen we aan de query nog een paar lay-out-stappen toe:
kies de optie Sluiten en laden
Overzichten
Maar, nu hebben we wel een koppeling maar nog geen gegevens, laat staan informatie. Dat lossen we snel op:
selecteer een lege cel in de werkmap met de Top2000-query
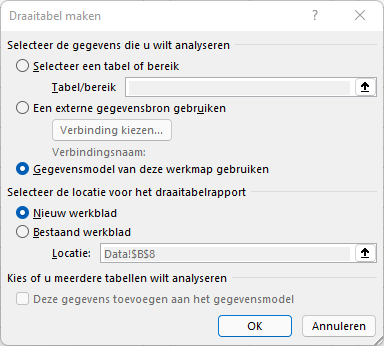
kies in de menutab Invoegen in het blok Tabellen de optie Draaitabel
in het vervolgscherm ziet u dat het systeem als bron het gegevensmodel wil gebruiken. Daar zitten onze brongegevens, dus dat is ok.
de locatie voor het draaitabelrapport kan een nieuw werkblad zijn of beginnen in een cel van een bestaand werkblad.
kies de button OK
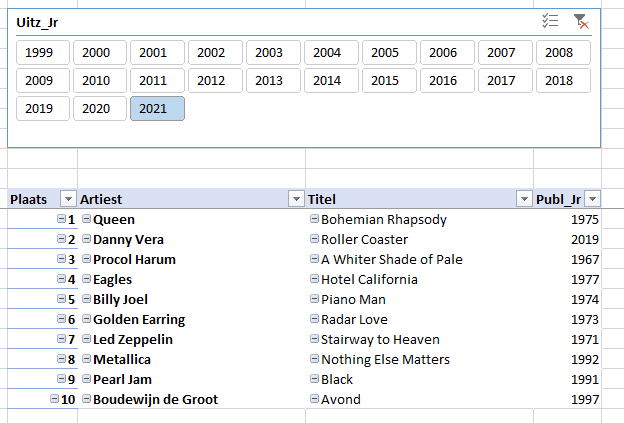
plaats de 4 velden zoals hiernaast in het blok Rijen
plaats het veld Uitz_Jr in het blok Filters of maak een Slicer die op dat veld gebaseerd is
het resultaat staat op het tabblad OvzPerJaar van het voorbeeldbestand
NB1 we gebruiken de draaitabel dus alleen om gegevens snel te rangschikken; we passen geen berekeningen toe.
NB2 gebruik in de draaitabellen die op een gegevensmodel zijn gebaseerd alleen tabellen met daarbij een oranje database-teken (of is het een prullenbak?).
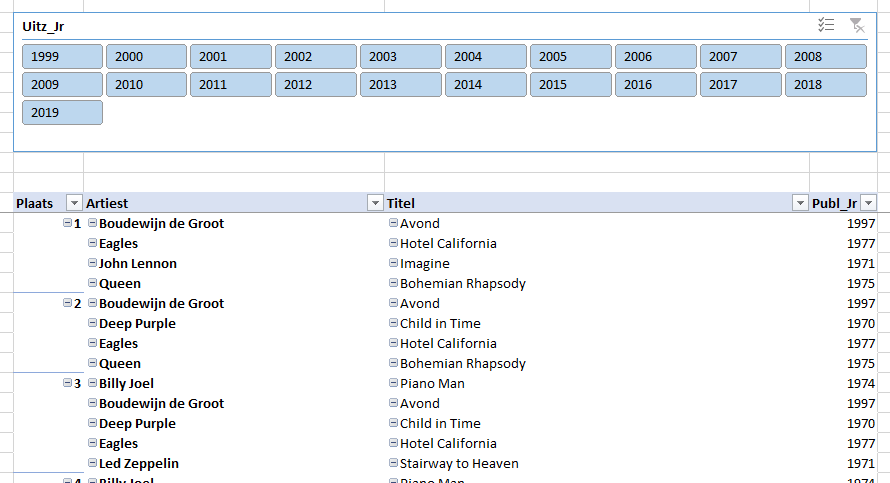
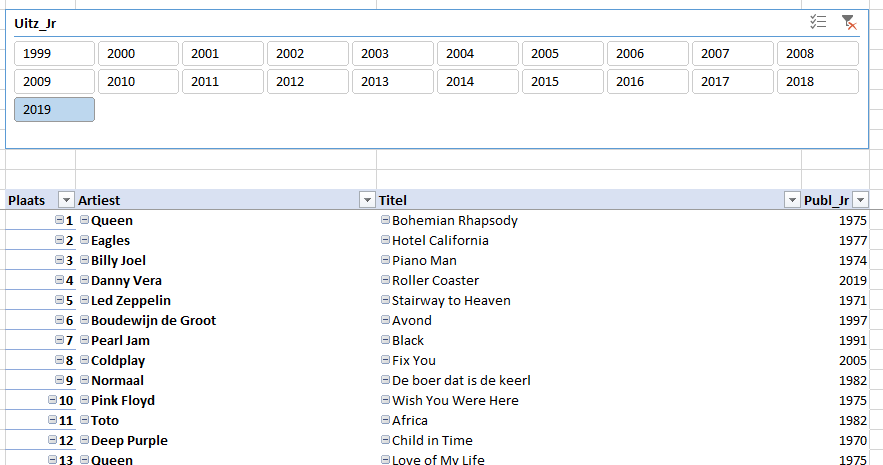
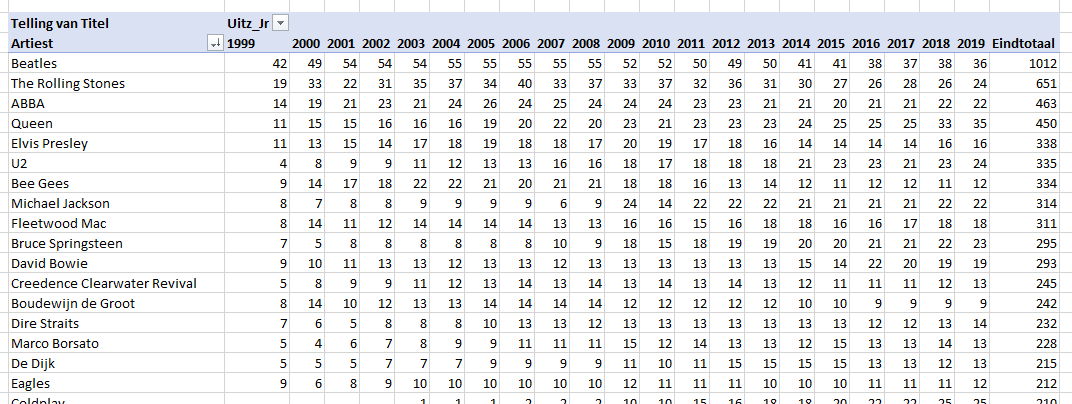
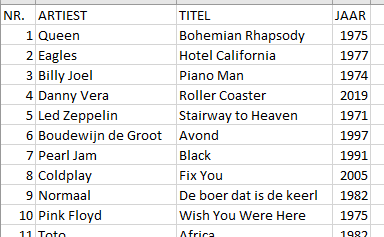
De map Top2000 bevat op dit moment alleen de jaren 1999 tot en met 2019. In die jaren hebben maar vier verschillende nummers op plaats 1 gestaan. Dat geldt ook voor plaats 2; bij plaats 3 zien we al vijf verschillende nummers.
Door in de slicer een specifiek uitzend-jaar te kiezen, krijg je het betreffende jaaroverzicht:
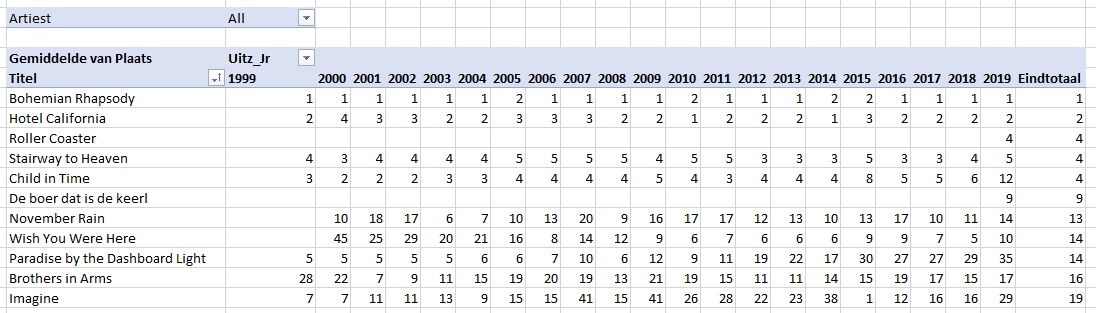
In het tabblad OvzPerArtiest staat een andere draaitabel:
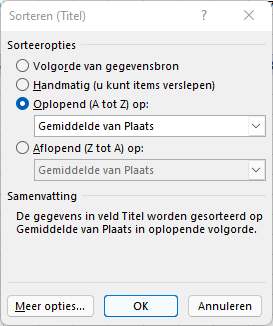
De Titel is oplopend gesorteerd op het Waardeveld (Gemiddelde van Plaats).
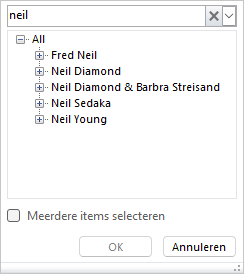
Om een bepaalde Artiest te kiezen, vul je een gedeelte van de naam in in het bovenste blok.
Nog een ander overzicht in het tabblad ArtiestenOvz van het Voorbeeldbestand:
Kijk voor een mooi, meer grafisch overzicht op de site van de Dutch Data Dude:
Consistentie
Zoals beloofd zou ons systeem de inconsistentie in naamgeving moeten oplossen. ‘Helaas’ zijn de makers van de Wiki-pagina zo ijverig geweest om de inconsistentie daar al te verwijderen.
Maar voor het geval dat er in de toekomstige aanleveringen wel weer andere namen opduiken laten we hier zien hoe je dat makkelijk kunt oplossen.
Het tabblad Data van het Voorbeeldbestand bevat 2 Excel-tabellen waarin de noodzakelijke correcties kunnen worden opgenomen.
Deze zijn op de standaardmanier met Power Query aan het gegevensmodel toegevoegd (de query’s hebben de namen q_tblCorArtiest en q_tblCorTitel).
NB de correcties die hier staan zijn natuurlijk niet nodig, maar worden gebruikt als voorbeeld.
Nu gaan we de Top2000-query aanpassen, zodat het resultaat weer consistent is:
dubbelklik op de Top2000-query (of klik rechts en kies Bewerken)
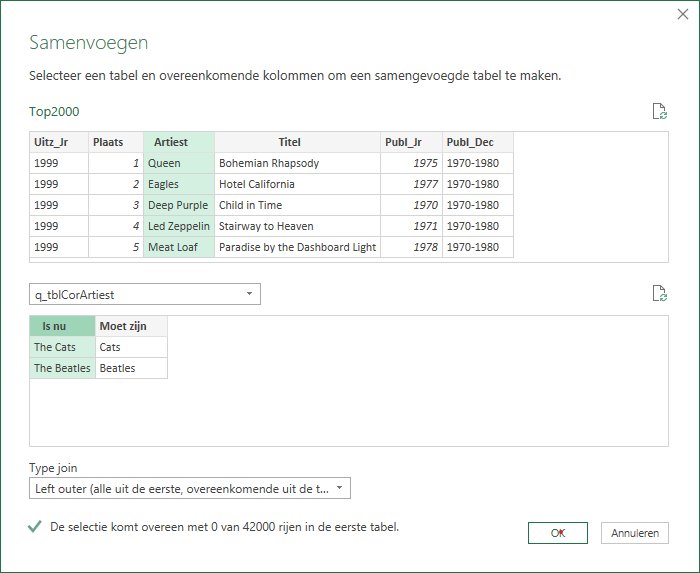
kies in het blok Combineren van de menutab Start de optie Query’s combineren
vul het scherm in, zoals hiernaast; de groene kolommen geven de velden aan met mogelijk overeenkomende waarden.
zorg bij Type join dat Left outer is geselecteerd. We willen natuurlijk wel alle records uit de bron zien!
klik op OK
herhaal de stappen 2 t/m 5 ook voor de correctie van de titels.
vouw de 2 kolommen met tabellen uit door op de button met de 2 pijltjes te klikken Zorg dat alleen de kolom Moet zijn wordt meegenomen.
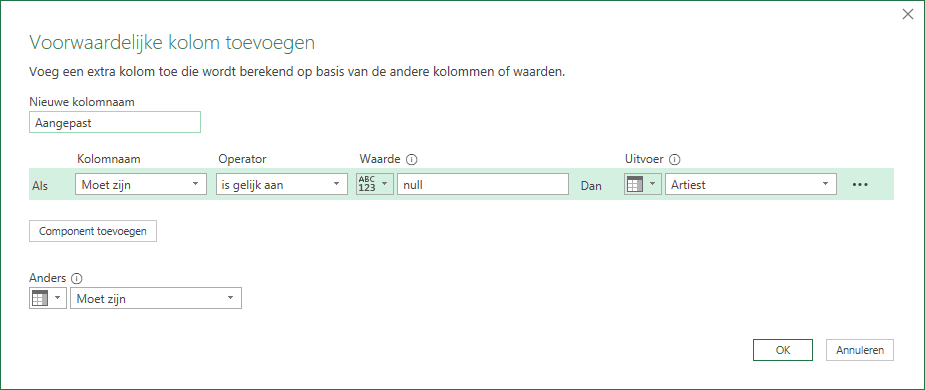
kies in de menutab Kolom toevoegen in het blok Algemeen de optie Voorwaardelijke kolom
vul het scherm in zoals hieronder NB bij Uitvoer en Anders eerst de juiste soort selecteren via de vink-button
voeg nog een Voorwaardelijke kolom toe om ook de gecorrigeerde titels mee te nemen
nu kunnen er nog wat overbodige kolommen verwijderd worden, andere kolommen krijgen een nieuwe naam en misschien een andere plaats. Kies dan weer Sluiten en laden.
Alle stappen kunnen gevolgd worden in het blok aan de rechterkant van de editor.
Klik op een stap en je ziet in de formulebalk wat er precies gebeurt.
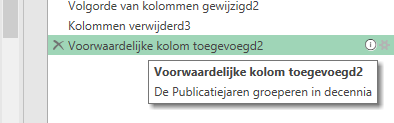
Sommige stappen zijn van een ’tandwieltje’ voorzien; als je daar op klikt krijg je een meer overzichtelijk tussenscherm te zien met de uit te voeren handelingen.
In de laatste stap is bij de Eigenschappen van die stap (rechts klikken) een Beschrijving ingevuld. Ga je met de muis over deze stap dan wordt de beschrijving direct zichtbaar Een prima methode dus om de werking van de query te documenteren.
Nieuwe of gewijzigde gegevens
Na al dat werk kunnen we nu achterover gaan leunen:
kopieer de files 2020.xlsx en 2021.xlsx uit het voorbeeldbestand naar de Top2000-map
zorg dat in de file Top2000 vs2.xlsx in het tabblad Data de juiste mapnaam staat aangegeven
klik rechts op één van de draaitabellen en kies Vernieuwen
alles is bijgewerkt!
Komt Radio-2 met de volledige lijst van 2021: controleer de namen van de kolomkoppen, zorg dat het tabblad de naam Data heeft, bewaar de file in de Top2000-map onder de naam 2021.xlsx (overschrijven dus) en vernieuw een draaitabel.
Dezelfde procedure kun je hanteren als in één van de basis-bestanden een fout zou staan.




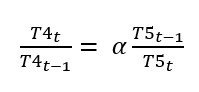 ofwel
ofwel 












 de optie Combineren en laden naar …
de optie Combineren en laden naar …